版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/cdknight_happy/article/details/85077086
1 深层神经网络
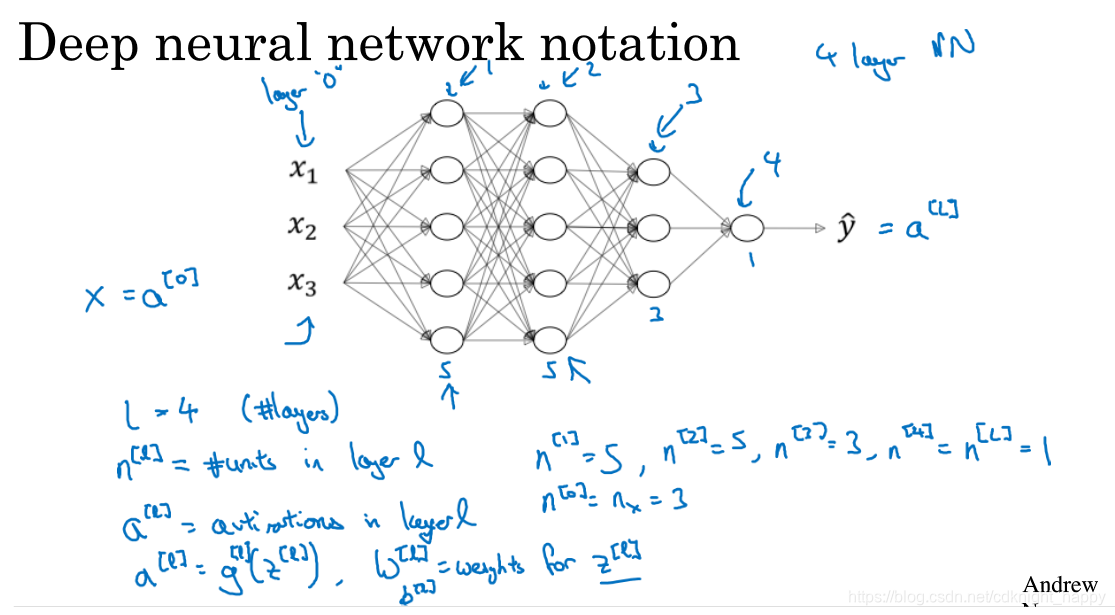
参数:
W[l]∈Rnl×nl−1
b[l]∈Rnl×1
dW[l]∈Rnl×nl−1
db[l]∈Rnl×1
Z[l]∈Rnl×m
A[l]∈Rnl×m
dZ[l]∈Rnl×m
dA[l]∈Rnl×m
深度学习块:
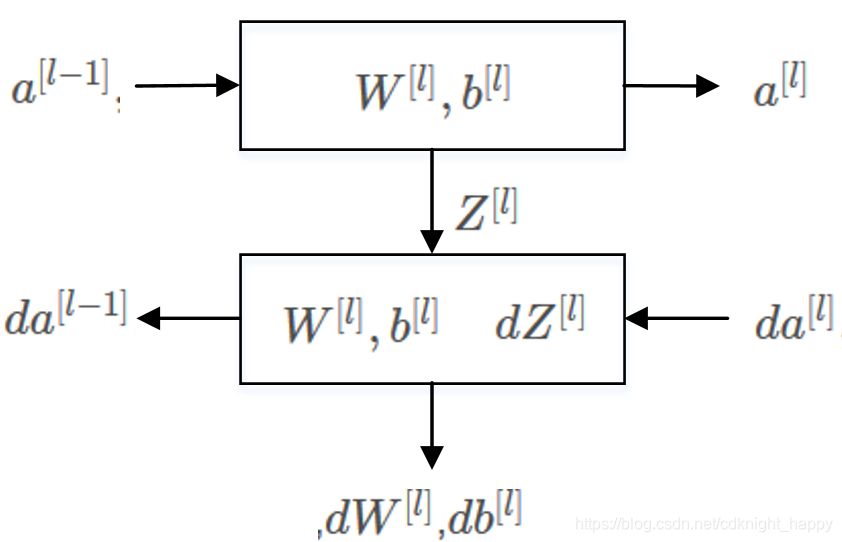
前向运算:
输入:
Z[l],
W[l],
b[l]
输出:
A[l]
Z[l]=W[l]A[l−1]+b[l]
A[l]=g[l](Z[l])
输出是
A[l],但是
Z[l]要暂存起来以便进行反向运算的梯度计算。
反向运算:
输入:
dA[l]和缓存的
Z[l]
输出:
dA[l−1],
dW[l],
db[l]
dZ[l]=dA[l]∗g[l]′(Z[l])
dW[l]=m1dZ[l]A[l−1]T
db[l]=m1np.sum(dZ[l],axis=1,keepdims=True)
dA[l−1]=W[l]TdZ[l]
深度学习网络:
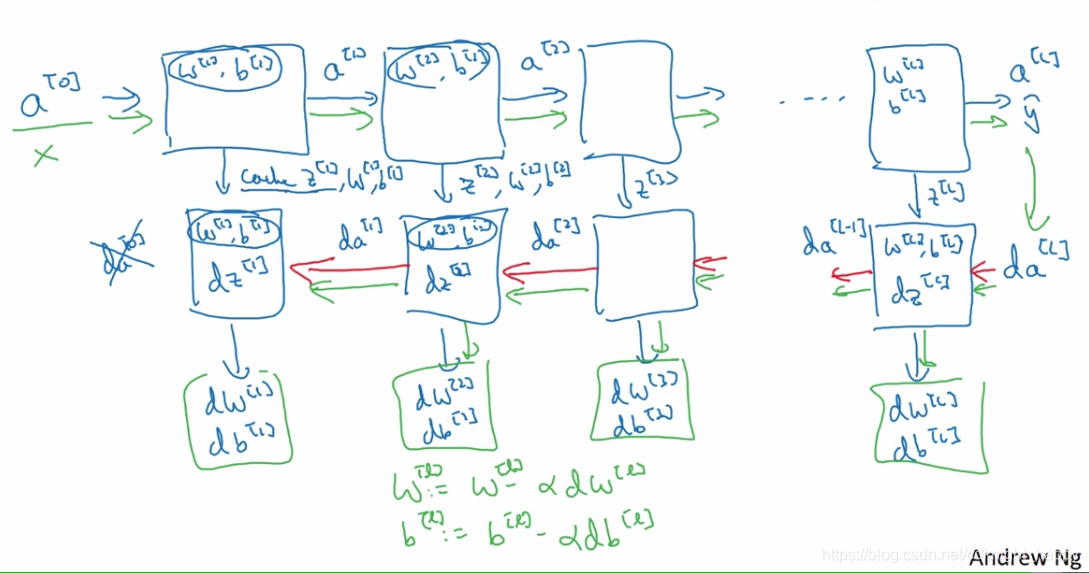
前向运算:
X=A[0]
for l in 1,...,L:
Z[l]=W[l]A[l−1]+b[l]
A[l]=g[l](Z[l])
反向运算:
反向运算的输入是损失函数对
a[L],也就是
y^的导数。之所以有
m1,是因为m个样本均与各个神经元的参数进行了乘积/相加运算。
for l in L,...,1:
dZ[l]=dA[l]∗g[l]′(Z[l])
dW[l]=m1dZ[l]A[l−1]T
db[l]=m1np.sum(dZ[l],axis=1,keepdims=True)
dA[l−1]=W[l]TdZ[l]
2 为什么使用深度表示?
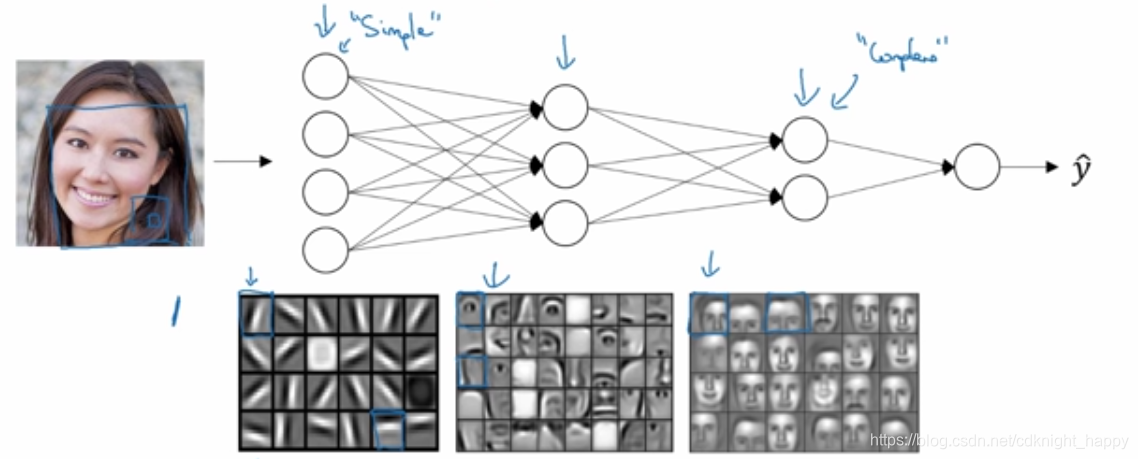 深层网络,浅层神经元在进行类似边缘检测的功能,比如每一个神经元在检测指定的边缘;中间层的神经元在进行类似部件检测的功能,比如检测人脸的鼻子、嘴巴等五官区域;深层的神经元在进行人脸局部的检测。这样特征逐步由简单向复杂进行汇聚组合,就实现了人脸检测功能。
深层网络,浅层神经元在进行类似边缘检测的功能,比如每一个神经元在检测指定的边缘;中间层的神经元在进行类似部件检测的功能,比如检测人脸的鼻子、嘴巴等五官区域;深层的神经元在进行人脸局部的检测。这样特征逐步由简单向复杂进行汇聚组合,就实现了人脸检测功能。
理论解释:
 能够使用小的深层网络表示的函数,若使用浅层网络进行表示,需要的隐藏神经元个数需要进行指数级的扩充。也就是说使用深层网络,那么每一层的神经元个数很有限,也可以表示很复杂的函数,也就是神经网络具有强大的函数拟合能力。
能够使用小的深层网络表示的函数,若使用浅层网络进行表示,需要的隐藏神经元个数需要进行指数级的扩充。也就是说使用深层网络,那么每一层的神经元个数很有限,也可以表示很复杂的函数,也就是神经网络具有强大的函数拟合能力。
3 参数 vs. 超参数
参数:
W[l],
b[l]
超参数:控制参数的参数
学习率 learning_rate
隐藏层数量
隐藏层单元数
激活函数的选择
迭代次数
动量值
mini batch的大小
正则化系数
…
因为超参数的选择决定了最终的参数,因此称之为超参数。
尝试不同的超参数进行实验,根据训练模型的效果选择超参数。
深度学习训练过程高度依赖于经验和试错。
深度学习和大脑的关联并不大。
4 作业
本周作业完整复习了神经网络的前向计算和反向传播过程,需要认真去实现下。