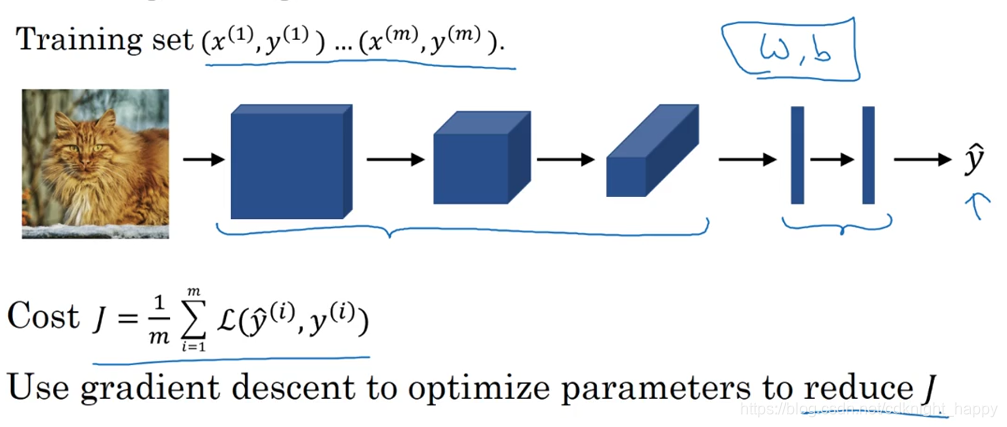
1 计算机视觉
计算机视觉包含的典型任务有:
- 图像分类;
- 目标检测;
- 图像风格转换。
计算机视觉任务的特点是输入数据量较大,对于一副1000 * 1000 * 3的图像而言,需要的输入神经元数量为3百万。假如第一隐藏层有1000个神经元,那么 ,如此大规模的参数很容易造成神经网络的过拟合,也对参数的存储要求了很高的内存需求。因此需要使用卷积运算降低所需要处理的参数数量。
2 卷积
卷积是卷积神经网络的基本组成部分。
卷积的实现是将卷积核依次沿着图像进行滑动,在任一处进行卷积核和覆盖图像块的对应元素相乘再相加的操作。
深度学习的发展就是不再使用手工设计的卷积核与图像进行卷积运算,而是采用有监督的训练样本、通过反向传播逼迫网络自身去学习适合的卷积核。
卷积的定义是需要对卷积核进行翻转操作的,但是一般在卷积神经网络中都是直接进行对应元素相乘再相加的操作,这其实是“相关”。之所以使用相关而不是卷积是因为一个基于核翻转的卷积运算的学习算法所学得的核是对未进行翻转的算法学得的核的翻转,因此在卷积神经网络中使用卷积和相关进行运算学得的核,含义是完全一致的。为了计算的便利性,一般都采用相关代替卷积。
padding
对输入为n * n的图像应用核大小为k*k的卷积操作后,得到的输出大小为(n-k+1) * (n-k+1)。如果进行多层这样的卷积,输出的尺寸会越来越小。同时,使用普通卷积时,图像边缘的像素参与计算的次数远小于图像中间位置的像素参与卷积计算的次数。因此,需要对输入图像进行padding操作以进行图像扩充。
padding操作一般在图像的四周进行尺寸相同的填充0的操作。
假设padding的尺寸为p,则卷积之后得到的输出为(n + 2p - k +1) * (n + 2p - k +1)。进行padding操作一方面可以防止卷积输出尺寸减小,另一方面也可以减弱图像边缘像素作用被弱化。
根据padding的尺寸大小,卷积可以分为vaild convolution和same convolution两种。
- vaild convolution:no padding。输出就是(n - k +1) * (n - k +1);
- same convolution:padding的目的是保证卷积前后得到的图像大小是一样的,padding根据卷积核的大小进行确定,即2p + 1 = k 。计算机视觉中使用的卷积核尺寸一般为奇数,因此 p 一般为整数。
卷积的stride
stride决定卷积核滑过图像时的移动步长。
原始输入图像 n * n,卷积核 k * k,padding尺寸 p,stride尺寸s,则卷积输出的尺寸为: 。向下取整是因为只有卷积核完全包含在图像范围内时才可以进行卷积计算。
多通道卷积–convlution over columes:
进行多通道卷积时,输入数据的通道数必须和卷积核的通道数一样。
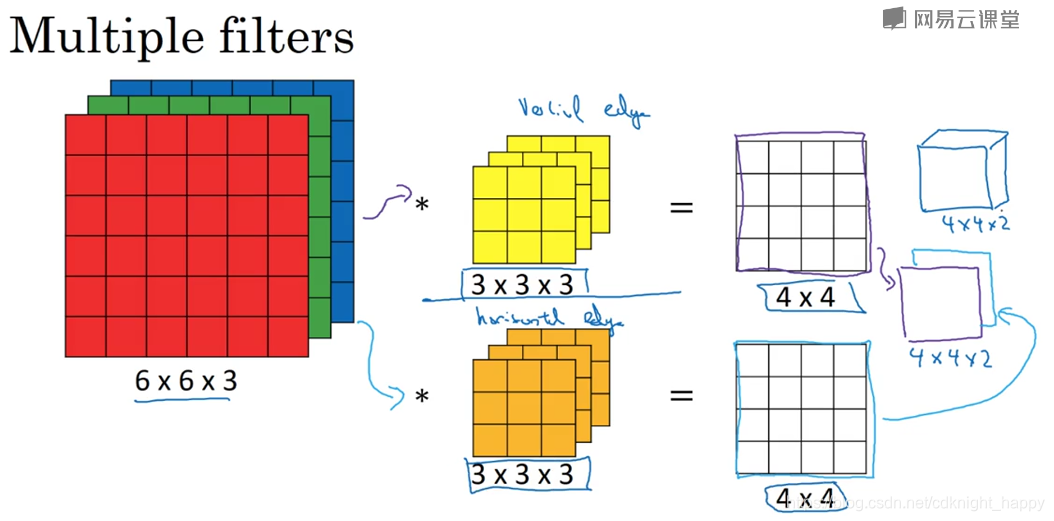
输入
,卷积核
,卷积的输出为
,
表示卷积核的数量。即卷积核必须和输入数据具有相同的通道数。输出的通道数为卷积核的数量。
总结:第l个卷积层也是先进行核和输入数据的卷积操作,然后再加偏差,通过relu激活函数得到输出。
假设第
个卷积层:
- padding大小为 ;
- stride大小为 ;
- 卷积核数量为 ;
- 输入大小为 ;
- kernel大小为 ;
- 输出大小为 ;
- 权重数目为 ;
- bias数目为 ;
- 大小为m的样本batch的激活值为 。
卷积网络中一般随着层数的加深,每一层的空间尺寸都在缩小,而channel数目在增加。
卷积神经网络包含卷积层(CONV)、池化层(POOL)和全连接层(FC)。
使用卷积的好处:
假设输入为32323 = 3072,输出为28286=4704,如果使用全连接,则参数数量为14,450,688。如果使用6个大小为553的卷积核进行卷积操作,则总的参数数量为6*(553+1)=456。因此使用卷积层可以有效减少参数的数量,避免过拟合。
卷积层减少参数数量主要是通过下述两点:
- 权值共享:对输入数据某一区域有用的滤波器对图像的其他区域同样有用;
- 稀疏连接:在每一层,每一个输出值只和局部的输入值有关。
卷积的平移不变性:
对图像进行平移之后,输出的卷积特征也进行相同的平移操作,因此卷积对平移操作是等变的。卷积对缩放和旋转不具有等变性。
3 池化
最大池化/平均池化,最大池化比平均池化更常用;
输入和输出具有相同的通道数;
池化操作中很少用到池化;
池化层没有要学习的参数;
输出的空间尺寸为
。
卷积神经网络中统计层数时,一般只统计包含学习参数的层,所以要不把一个卷积核和一个池化层合称为一层,要不就单独把卷积层作为一层。
4 神经网络示例