在《机器学习实战》一书的第5章逻辑斯蒂回归的代码介绍中,p79中开头有一句,“此处略去了一个简单的数学推导”,那么到底略去了哪一个简单的数学推导呢?本着要将这个算法彻底搞明白的态度,笔者在百度上搜了好多资料,终于找到了相关的资料,以供参考。


从上图中按照逻辑斯蒂回归算法,利用梯度下降法求解其最值的方法,可以看到,最后求得的w如上图最后更新迭代所示。那么《机器学习实战》一书中,通过代码理解,得到它的做法是:

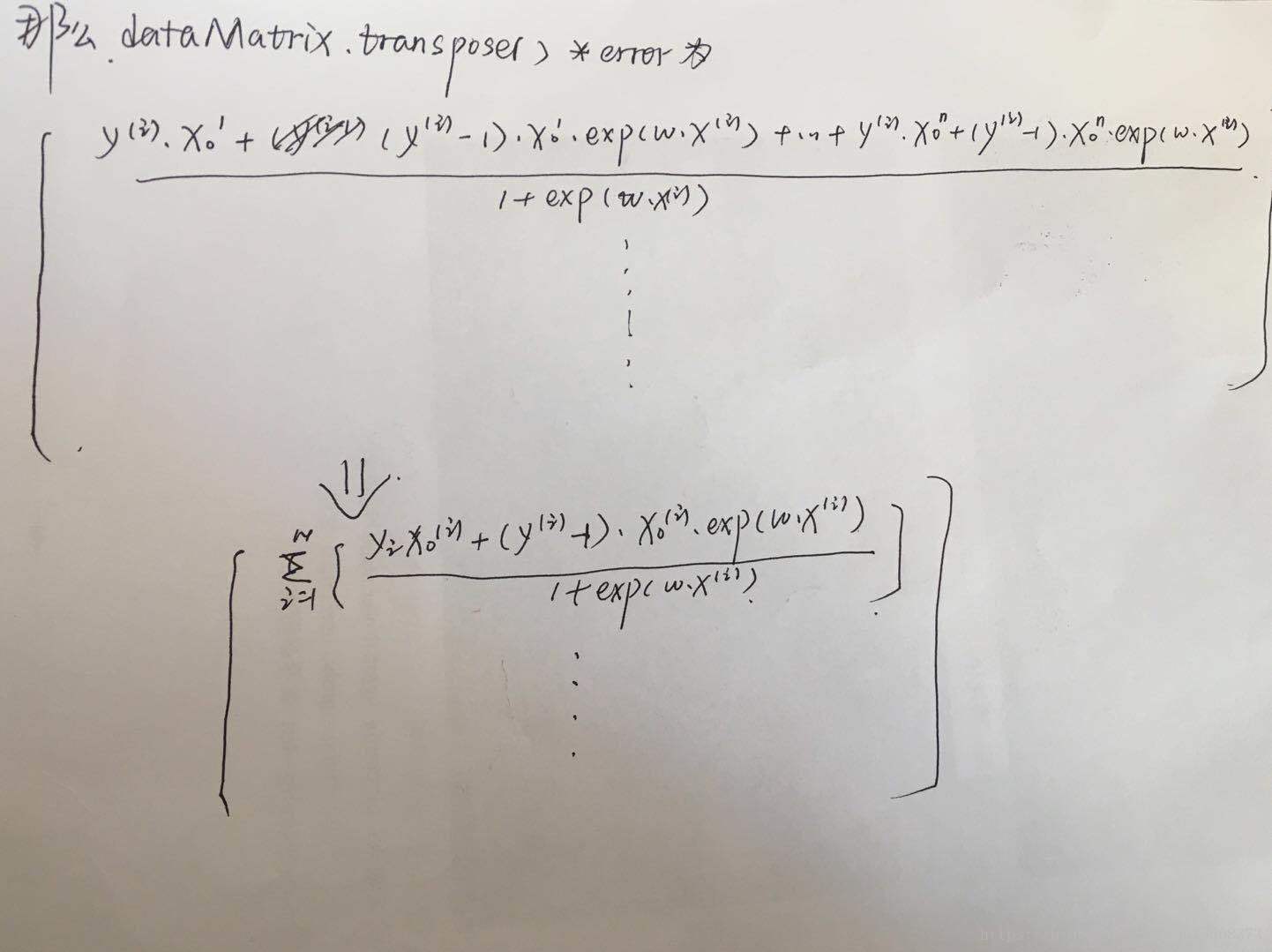
正好那一行weights = weights + alpha * dataMatrix.transpose() * error得到的结果即为刚才通过梯度下降法得到的w的更新结果。那么这就可以理解书中代码的含义了。
但是理解了上述书中代码的含义,那么真正的推导是如果做到的呢?且看下文分解:
假设函数为:
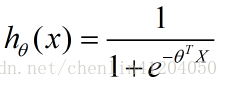
1、梯度上升法(参数极大似然估计)
通过查看《统计学习方法》中的模型参数估计,分类结果为类别0和类别1的概率分别为:
则似然函数为:
对数似然函数为:
最大似然估计求使得对数似然函数取最大值时的参数θθ
对L(θ)L(θ)求导得:
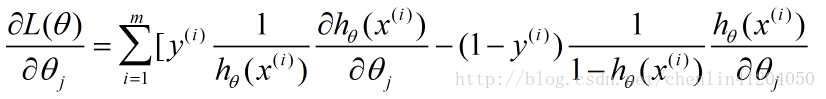
即为:
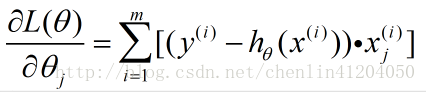
则单个特征系数的梯度上升法的迭代公式为:
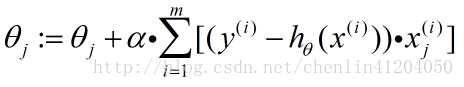
对整个特征参数向量的梯度上升法的迭代公式为:
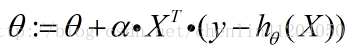
那么这个式子就是《机器学习实战》一书p79略去的数学推导部分的内容。