逻辑斯蒂函数
引入: 在线性感知器算法中,我们使用了一个f(x)=x函数,作为激励函数,而在逻辑斯蒂回归中,我们将会采用sigmoid函数作为激励函数,所以它被称为sigmoid回归也叫对数几率回归(logistic
regression),需要注意的是,虽然它的名字中带有回归,但事实上它并不是一种回归算法,而是一种分类算法。它的优点是,它是直接对分类的可能性进行建模的,无需事先假设数据分布,这样就避免了假设分布不准确所带来的问题,因为它是针对于分类的可能性进行建模的,所以它不仅能预测出类别,还可以得到属于该类别的概率。除此之外,sigmoid函数它是任意阶可导的凸函数。在这篇文章中,将会使用到梯度上升算法,可能有很多同学学到这里会有点迷糊,之前我们所使用的是,梯度下降算法为什么到这里却使用的是梯度上升算法?
解释logistic回归为什么要使用sigmoid函数
hθ=g(θTX)=1+e−θTX1
hw=g(wTX)=1+e−wTX1
hw=g(Xw)=1+e−Xw1
准备数据
import numpy as np
X = np.random.randn(50,4)
X.shape
w = np.random.randn(4)
X[[0]].dot(w)
3.154665990657282
'''假如有一个罐子,里面有黑白两种颜色的球,数目多少不知,
两种颜色的比例也不知。我们想知道罐中白球和黑球的比例,
但我们不能把罐中的球全部拿出来数。现在我们可以每次任意从已经摇匀
的罐中拿一个球出来,记录球的颜色,然后把拿出来的球 再放回罐中。
这个过程可以重复,我们可以用记录的球的颜色来估计罐中黑白球的比例。
假如在前面的一百次重复记录中,
有七十次是白球,请问罐中白球所占的比例最有可能是多少?'''
f(p) = p**70*(1-p)**30
f(p)=p70∗(1−p)30
70∗p69∗(1−p)30+p70∗30∗(1−p)29∗(−1)=0
70∗(1−p)−p∗30=0
70−100∗p=0
p=0.7
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qYFdaCw1-1574858609335)(l.png)]](https://img-blog.csdnimg.cn/20191127204740396.png)
l(θ)越大越好,梯度上升优化
J(θ)=−l(θ)越小越好,梯度下降了
将似然函数变成log函数
梯度上升添加符号就变为梯度下降
再求导求出j点的梯度
!!!
我是这样认为的:所谓的梯度“上升”和“下降”,一方面指的是你要计算的结果是函数的极大值还是极小值。计算极小值,就用梯度下降,计算极大值,就是梯度上升;另一方面,运用上升法的时候参数是不断增加的,下降法是参数是不断减小的。但是,在这个过程中,“梯度”本身都是下降的。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xKqBTwEo-1574858609336)(d.png)]](https://img-blog.csdnimg.cn/20191127204753314.png)
提取共同系数
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cF1F5HVs-1574858609337)(d2.png)]](https://img-blog.csdnimg.cn/20191127204800253.png)
hθ=g(θTX)=1+e−θTX1
(1+e−θTX)21∗e−θTX∗∂θj∂θTX
(1+e−θTX)1∗(1+e−θTX)e−θTX∗∂θj∂θTX
g(θTXi)∗(1+e−θTX)e−θTX∗∂θj∂θTX
g(θTXi)∗(1+e−θTX)e−θTX∗∂θj∂θTX
1−g(θTXi)=1−1+e−θTX1=1+e−θTX1+e−θTX−1+e−θTX1=1+e−θTXe−θTX
g=1+e−x1
g′=g∗(1−g)
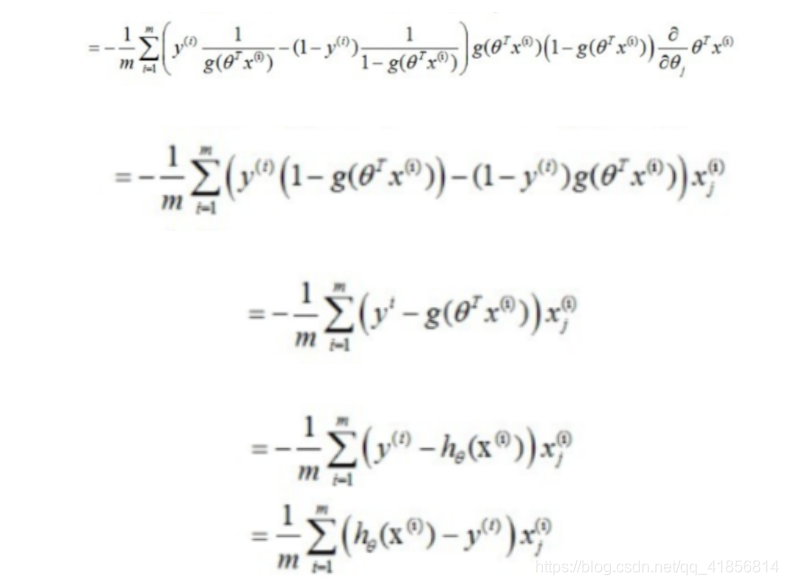
手写笔记个人总结使用



可参考
彻底搞懂逻辑斯蒂回归
