逻辑斯蒂回归是机器学习中经典的分类方法
逻辑斯蒂分布
设X是连续随机变量,X服从逻辑斯谛分布是指X服从如下分布函数和密度函数:


其中,μ为位置参数,σ>0为形状参数
曲线在中心附近增长速度较快,在两端增长速度较慢,形状参数σ的值越小,曲线在中心附近增长的越快

二项逻辑斯蒂回归模型
二项逻辑斯蒂回归模型是如下的条件概率分布:

![]() 是输入,
是输入,![]() 是输出,w,b是参数,w称为权值向量,b为偏置,w*x为w和x的内积
是输出,w,b是参数,w称为权值向量,b为偏置,w*x为w和x的内积
对于给定的样本x,利用二项逻辑斯蒂回归模型计算该样本类别为1和0的概率,然后,将样本x分类到概率较大的那一类
二项逻辑斯蒂回归模型的紧凑形式:有时为了方便,将权值向量和输入向量进行扩充,仍记作w,x,w=(w(1),w(2),…w(n),b)T,x=(x(1),…x(n),1)T此时,逻辑回归模型为:

![]()
几率:一个事件发生的几率是指该事件发生的概率与该事件不发生的概率的比值,如果事件发生的概率是p,那么该事件的几率是p/(1-p),该事件的对数几率(log odds)或者logit函数是:

使用逻辑斯蒂的紧凑形式表示对数几率就是:
![]() ==== 取对数 ====>>>
==== 取对数 ====>>> 
也就是说,在逻辑斯蒂回归模型中,输出Y=1对应的对数几率是输入x的线性函数。或者说,输出Y=1的对数几率是由输入x的线性函数表示的模型,即逻辑斯蒂回归模型
从另外一个角度:对输入x的线性函数wx进行逻辑斯蒂函数计算,得到该样本属于Y=1的概率
有了Y=1的概率,我们就可以1-p得到Y=0的概率,我们就可以判断实例x的分类了,现在我们需要关心的就是w如何进行训练
二项逻辑斯蒂回归模型参数的估计
逻辑斯蒂回归模型学习时,对于给定的数据集T={(x1,y1),(x2,y2), ......(xn,yn)},其中,![]() ,
,![]() ,
,
设:

对于逻辑斯蒂回归模型而言,某个输入样本x对应的输出为y的概率为:![]()
基于极大似然估计的思想:给定Ν个样本,最优的参数应该是使得这给定的N个样本的联合概率密度![]() (即似然函数)取得最大的参数:
(即似然函数)取得最大的参数:

对数似然函数为:
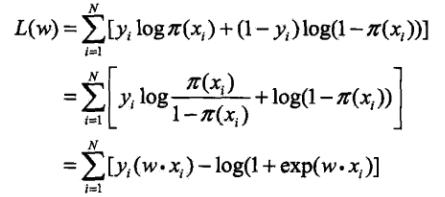
所以,最终参数估计,相当于求似然函数最大值

这样,问题就变成了以对数似然函数为目标函数的最优化问题,逻辑斯蒂回归的参数学习通常采用的方法是梯度下降及拟牛顿法
假设w的极大似然估计值是w*,那么学到的逻辑斯蒂回归模型为:

多项逻辑斯蒂回归
二项逻辑斯蒂回归模型用于且仅能用于2类分类问题,如果是多类分类问题,需要对二项逻辑斯蒂回归模型进行拓展,得到多项逻辑斯蒂回归模型
对于某一个输入样本x,它的输出类别的取值可能有多个(K个),此时,不能再用二项分布来描述这种分布了,而是需要利用多项式分布来描述类别的分布
每一个类别的概率还是以逻辑斯蒂分布的形式描述

二项逻辑斯蒂回归的参数估计法可以推广到多项逻辑斯蒂回归
二项逻辑斯蒂回归和多项逻辑斯蒂回归
