感谢学习视频:https://www.bilibili.com/video/BV1Y7411d7Ys?p=6&vd_source=2314316d319741d0a2bc13b4ca76fae6
本节考虑分类问题,建立模型是逻辑斯蒂回归,虽然名字叫回归,但处理分类问题的。
标题
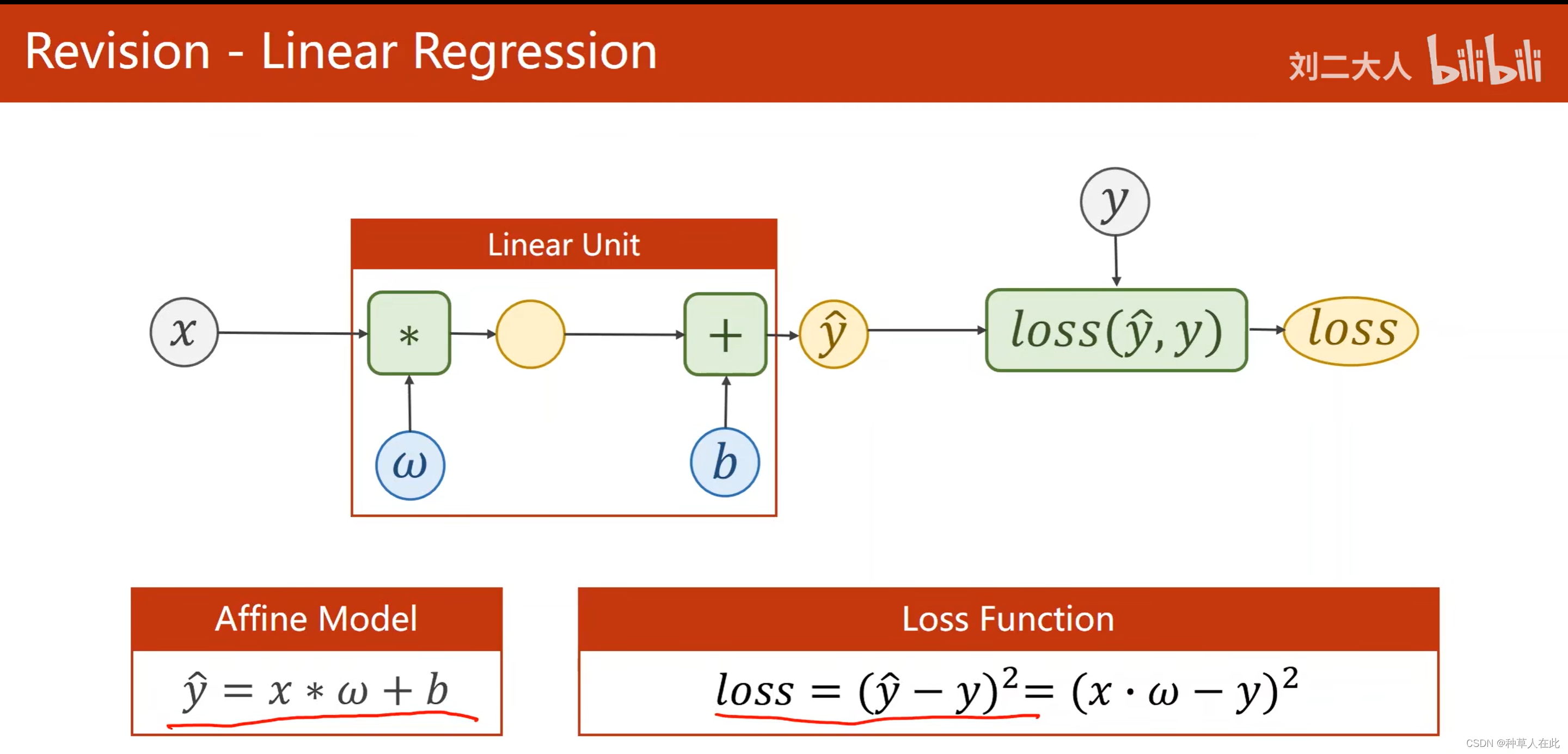
这是之前用线性回归模型。

在这里我们估计的y是属于连续空间,像这种任务叫回归分析。
但机器学习中做的多的是分类问题。

MNIST是一个手写数字数据集,有10个类别,如果用回归方法做分类问题,比如说:第0个类别,就让y=0;第1个类别就让y=1,这种思想是不好的。因为这些0-9的类别没有一维实数空间数值大小的含义,即类别之间不是数值比较,即图片中的9没有比图片中的0抽象概念(类别)大。所以,分类问题不能用线性回归这种模型简单的输出0-9来做。
分类问题的核心是概率:根绝输入x,得到y输出为0的概率,输出为2的概率…。概率是满足一个分布的,概率之和为1,从概率值里找最大概率值。

MNIST是最基础的数据集,用来测量学习器的性能指标,所以在pytorch框架中有一个 torchvison 包,这个包里有一个模块提供相应的数据集,一些比较流行的数据集都有。但,安装torchvison时他不会把数据集包含在包里面,如果你没有下载该数据集,可用上面的程序自动下载。【少部分不支持自动下载】
参数1:数据集存储路径;参数2:train=True表示训练集,False表示测试集;参数3:download=True联网自动下载,False表示已下载了。
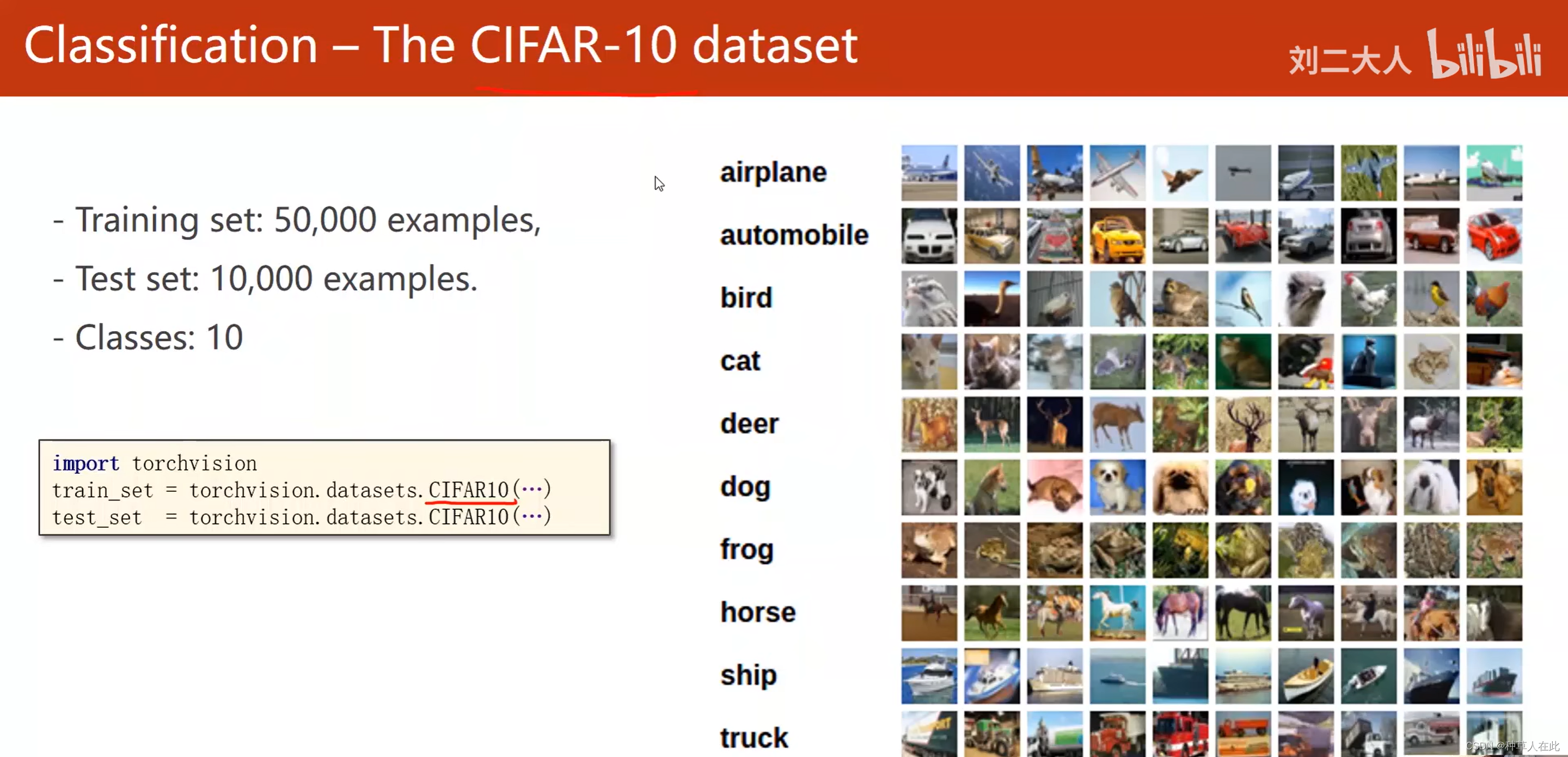
CIFAR数据集:32*32的图片,10个类别,
下载过程和参数设置与上面一致。

在这个数据集下,原来是回归问题,就是学习时间与他最后拿多少分?而在分类任务里,就是他最后是否通过考试?【过;不过,两个类别的分类问题 = 二分类问题】
二分类问题最终要计算的就是两个概率【实际计算一个即可,因为两者加和等于1】
如果计算出来的概率非常接近0.5,意味着我们的学习器对这个数据样本的类别并无十足把握。
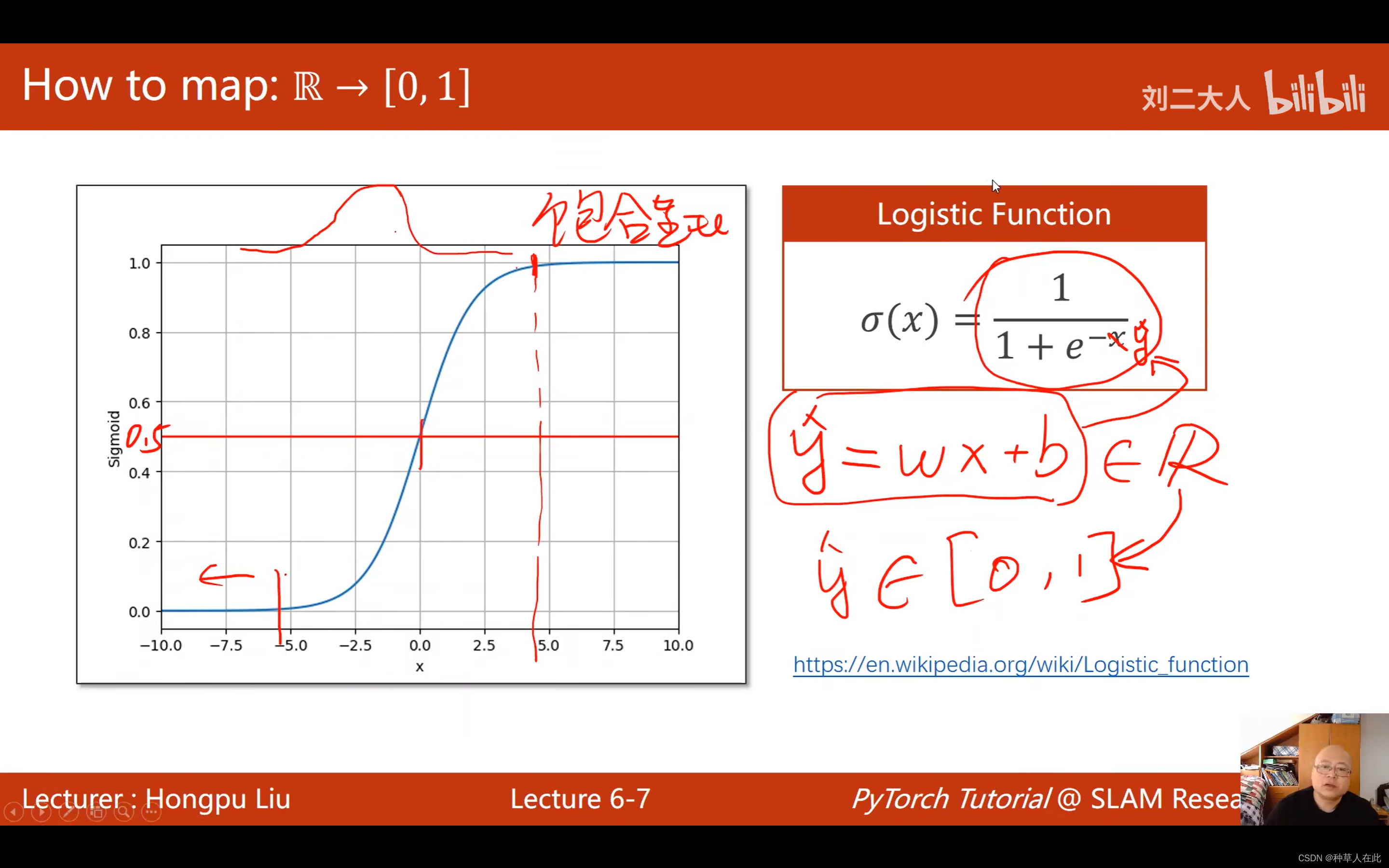
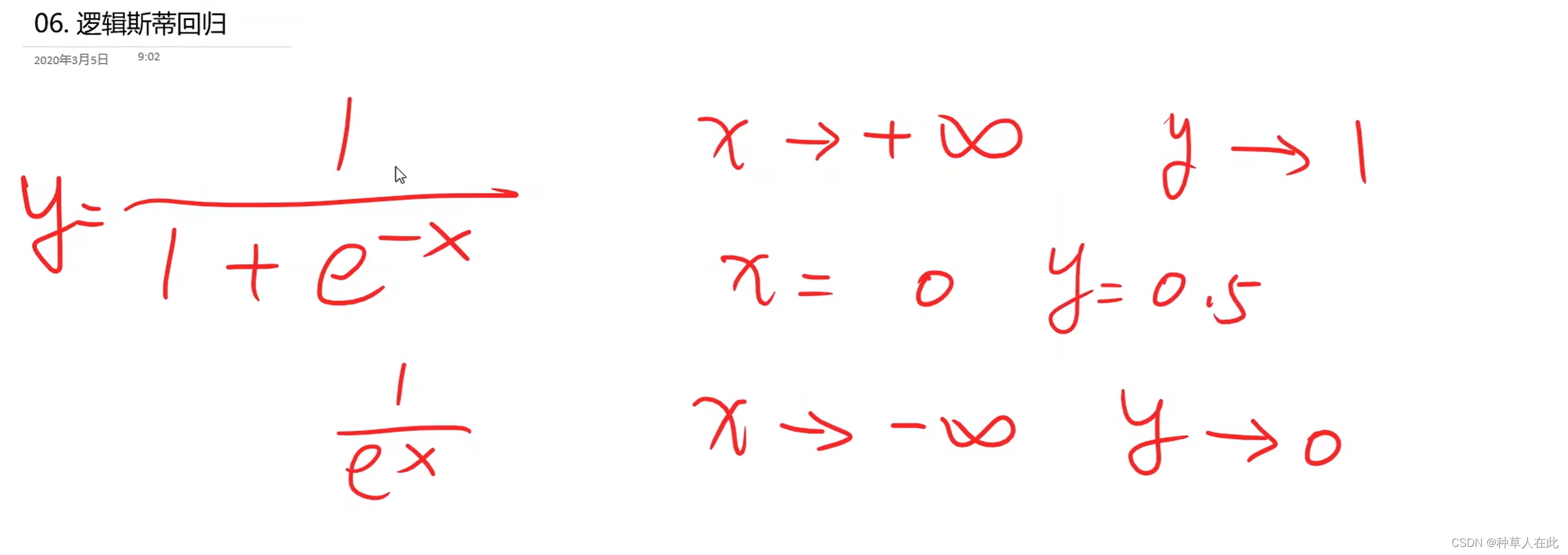
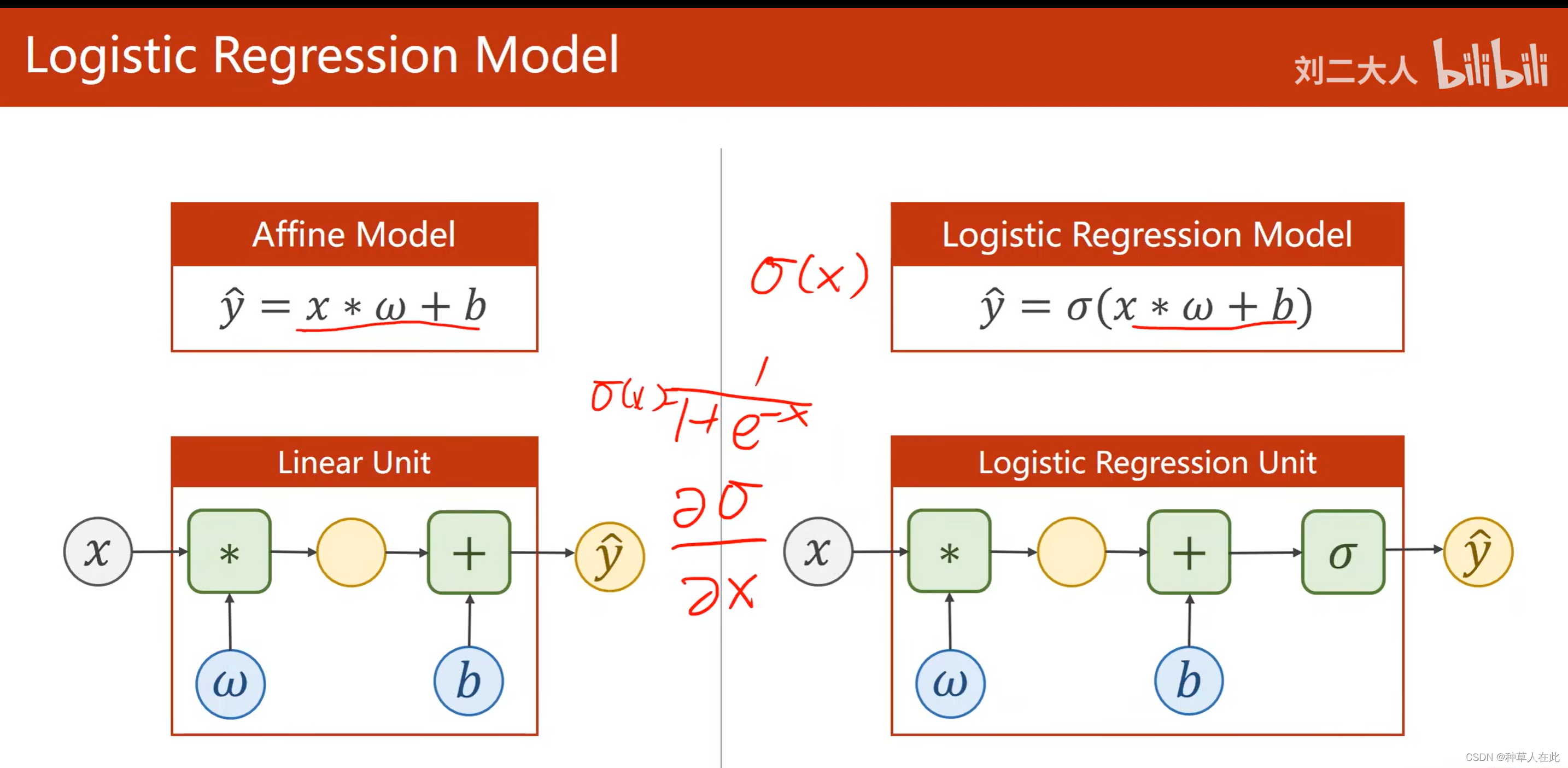
之前用线性模型,y_hat=wx+b 输出为一个实数,而分类问题我们需要的是概率属于【0,1】,所以我们需要把实数映射到【0,1】,即找一个函数来实现: logistic 函数
可以观察到这个函数有个特点: 超过某一阈值后,剩余一段增长的很慢,他的导数会变得越来越小。
这种函数数学中称之为饱和函数
logistic 函数的导数图像像正态分布的分布函数。【它就是因正态分布而产生的函数】
sigmoid Function
- 函数值有极限
- 单调增
- 饱和函数
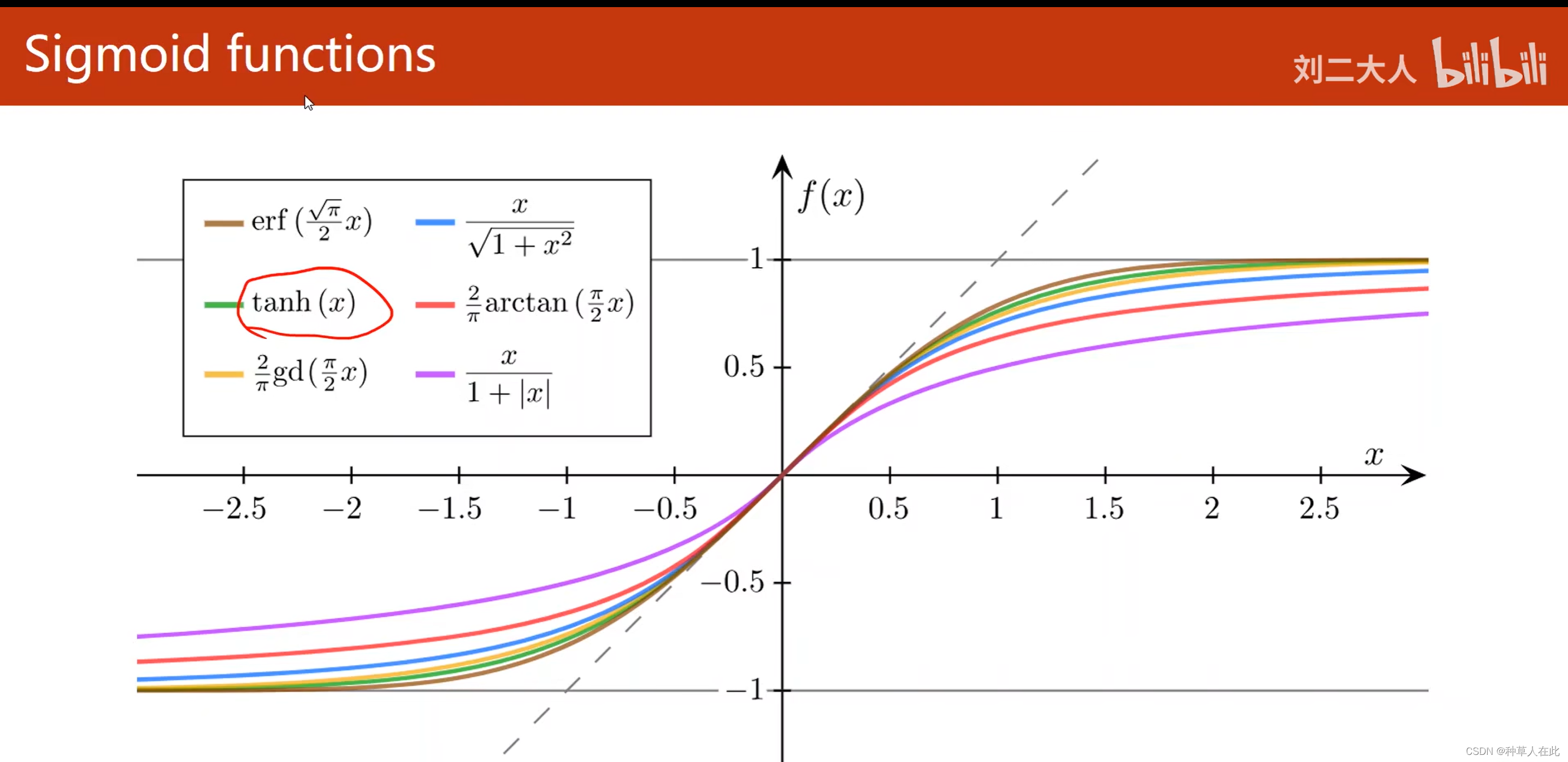
这些函数是【-1,1】
在所有sigmoid函数中最出名的就是logistic 函数,所以,现在在一些框架中,直接把logistic 函数称为sigmoid 【约定俗称】。
模型的不同:
损失函数改变

loss原来用的是MSE,y_hat-y是有意义的,是数轴上两者的距离,目的是让这个距离最小化。而现在输出是分布分布不是数轴上的距离,实际表示的是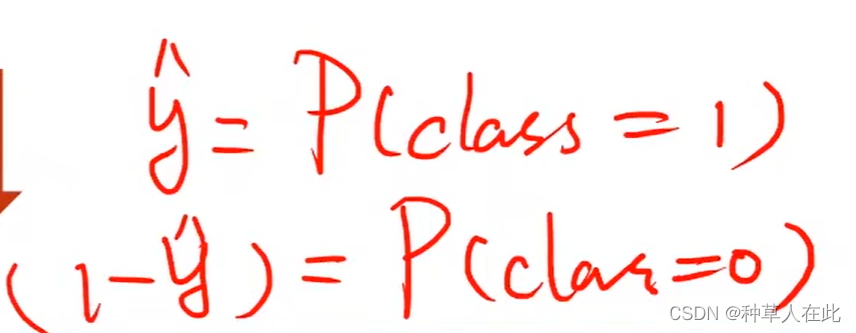
数据集的y有可能为0或1,
想比较的是两个分布之间的差异。计算分布的差异。
计算两个分布直接差异,在概率论中,比如:KL散度、cross-entropy【交叉熵】等。
交叉熵公式:

假如有两个分布,Pd和Pt
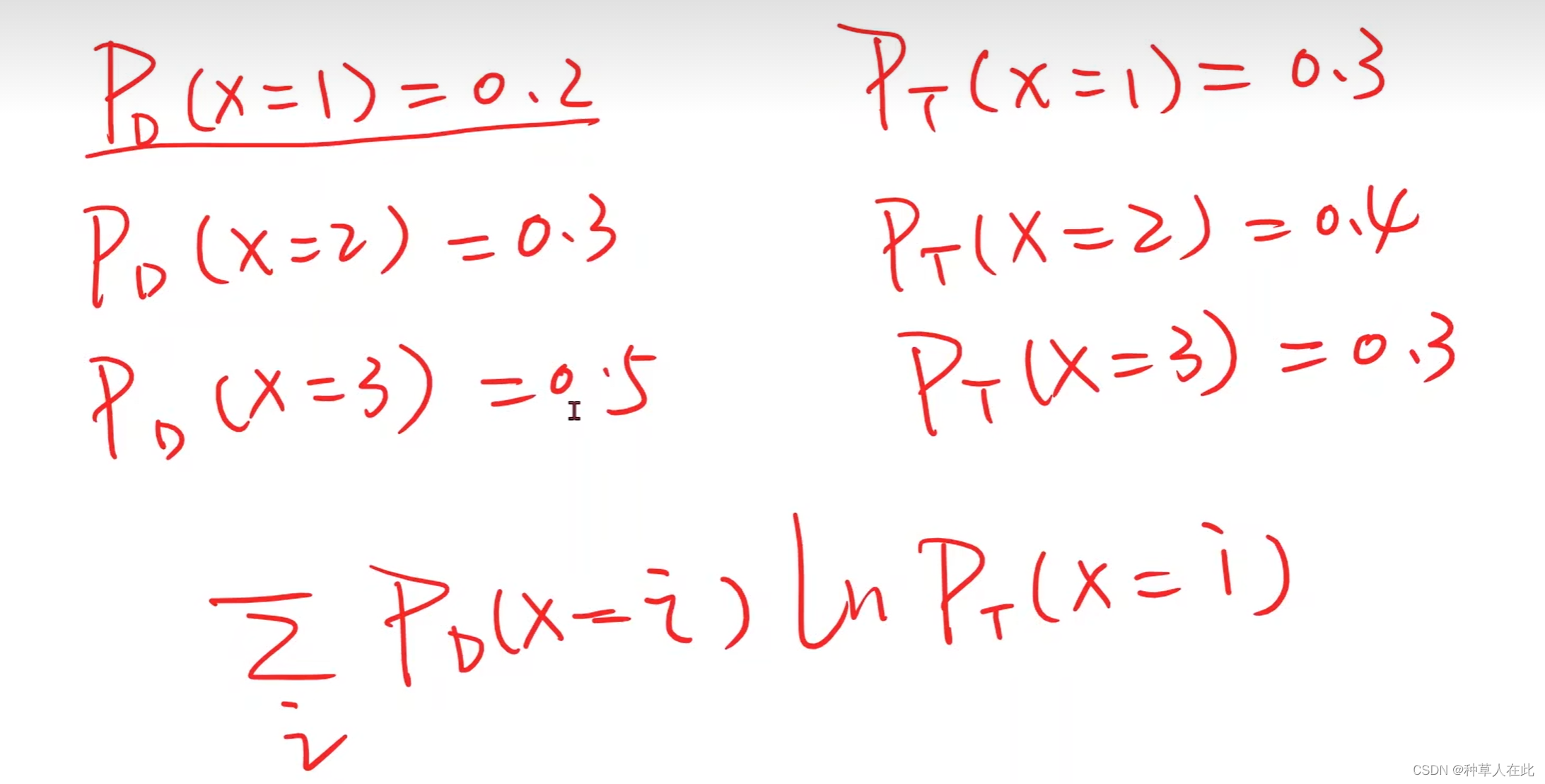
用这个公式来表示两个分布之间差异性的大小,越大越好。
在这里,我们用了一个二分类的交叉熵:

相当于y分布和y_hat分布,两者的差异。加个负号,表示越小越好。

当y=1时,要想最小,y_hat必须要大,但又不能超过1,所以接近1就是最大。
当y=0时,要想最小,y_hat必须小,所以越接近0越好。
所以根据这样一个目标函数,求最小值时就可以让分布项尽可能去和它的真实分类去接近。
这个二分类函数称为:BSE函数
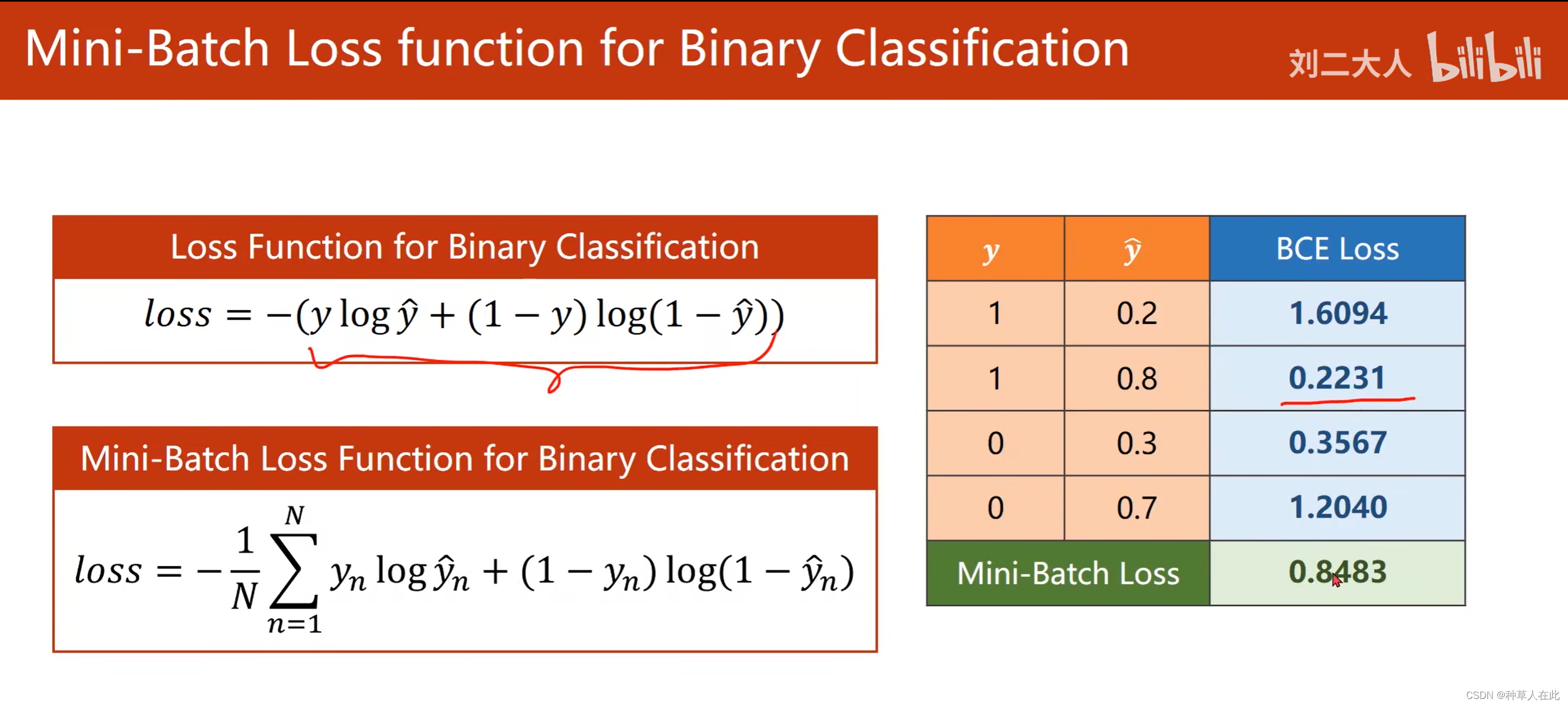
可以看到 预测越接近,BSCloss越小。
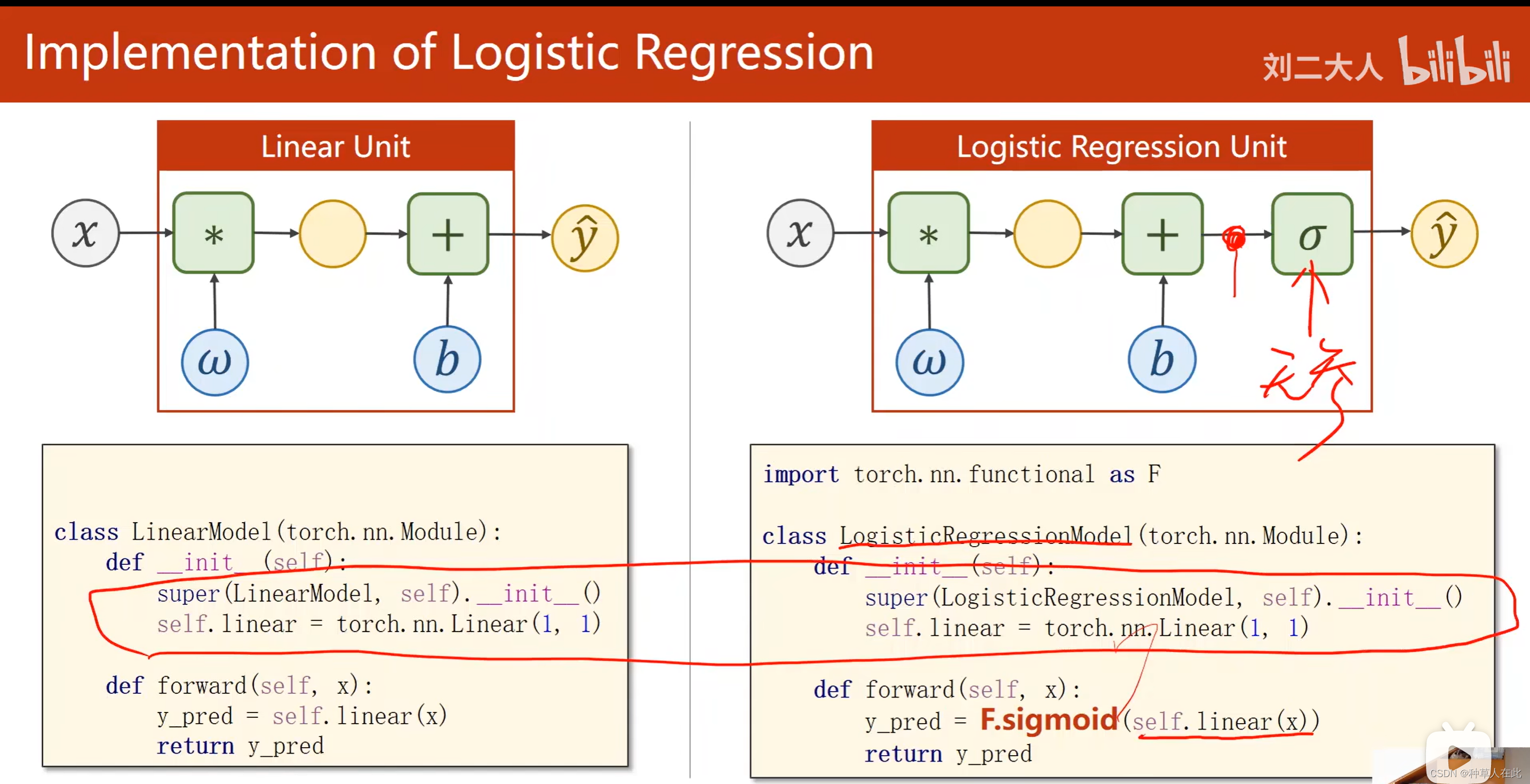
这个模型名字叫LogisticRegressionModel,在构造函数部分基本一致,因为sigmoid函数李米娜没有参数,即不需要再构造函数里去初始化它 ,因为没有参数去训练,后面直接调用即可。
sigmoid函数定义在 torch.nn.functional 函数包里。先进行linear变换,将输出应用到sigmoid中。
F.sigmoid(self.linear(x))和torch.sigmoid(self.linear(x)) 两者计算结果同,前者是方法,后者是一层。
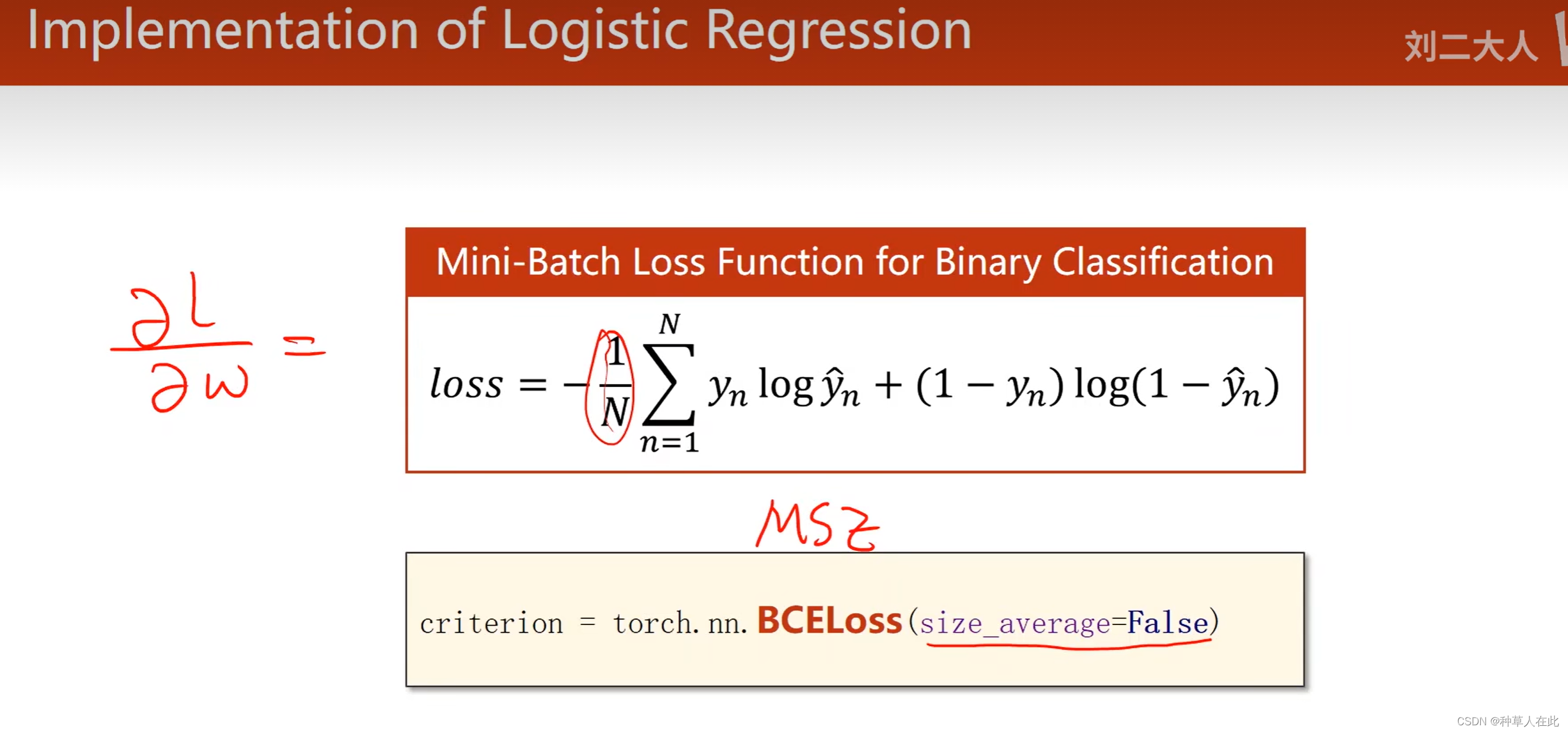
其次就是loss的变化,用BCE交叉熵求loss,初始化只需要设置是否要求每个批量的均值,求不求的关键影响到将来学习率的设置,因为如果求均值,前面有一个小常数,而后面求导也会乘上小常数。
这个框架可胜任大部分的网络模型的编写,编写任何一个网络模型都是四步:1.准备数据【有可能读数据部分很复杂,封装一下,封装到一个模块里,提供一些工具函数或工具类,然后把数据读出来】2. 模型构造,定义相应模型【如果模型比较复杂,单独放在一个文件夹,然后构造这些模型,通过主程序 import 进来】 3. loss和优化器【可以自己进行设计】4.训练循环。



整体代码:
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE" #这是因为anaconda的环境下存在多个libiomp5md.dll文件,如果不加,画图报错
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn.functional as F
# 现在用 torch的 Tensor,用mini-batch的风格
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[0.0], [0.0], [1.0]])
class LogisticRegressionModel(torch.nn.Module): #建立模型
def __init__(self):
super(LogisticRegressionModel, self).__init__()
self.linear = torch.nn.Linear(1,1)
def forward(self, x):
y_pred = F.sigmoid(self.linear(x))
return y_pred
model = LogisticRegressionModel() #实例化模型
criterion = torch.nn.BCELoss(size_average =False) # BCE损失
optimizer = torch.optim.ASGD(model.parameters(), lr=0.01) #优化器
for epoch in range(100): #训练循环
y_pred = model(x_data) #计算y_hat
loss = criterion(y_pred, y_data) # 计算loss
print(epoch, loss.item())
optimizer.zero_grad() #清梯度
loss.backward() #反向传播
optimizer.step()
# output weight and bias
# print('w = ', model.linear.weight.item())
# print('b = ', model.linear.bias.item())
# 测试集
# test model
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data)
# 做测试 画图
x = np.linspace(0,10,200) # 0-10h采200个点
x_t = torch.Tensor(x).view((200,1)) #将200个点编程200*1的矩阵 ;类似于numpy中的reshape
y_t = model(x_t)# 将得到的张量送到模型里
y = y_t.data.numpy() # 将y数据拿出
plt.plot(x, y) # 绘图
plt.plot([0,10],[0.5,0.5],c='r')
plt.xlabel('Hours')
plt.ylabel('Probability of Pass')
plt.grid()
plt.show()
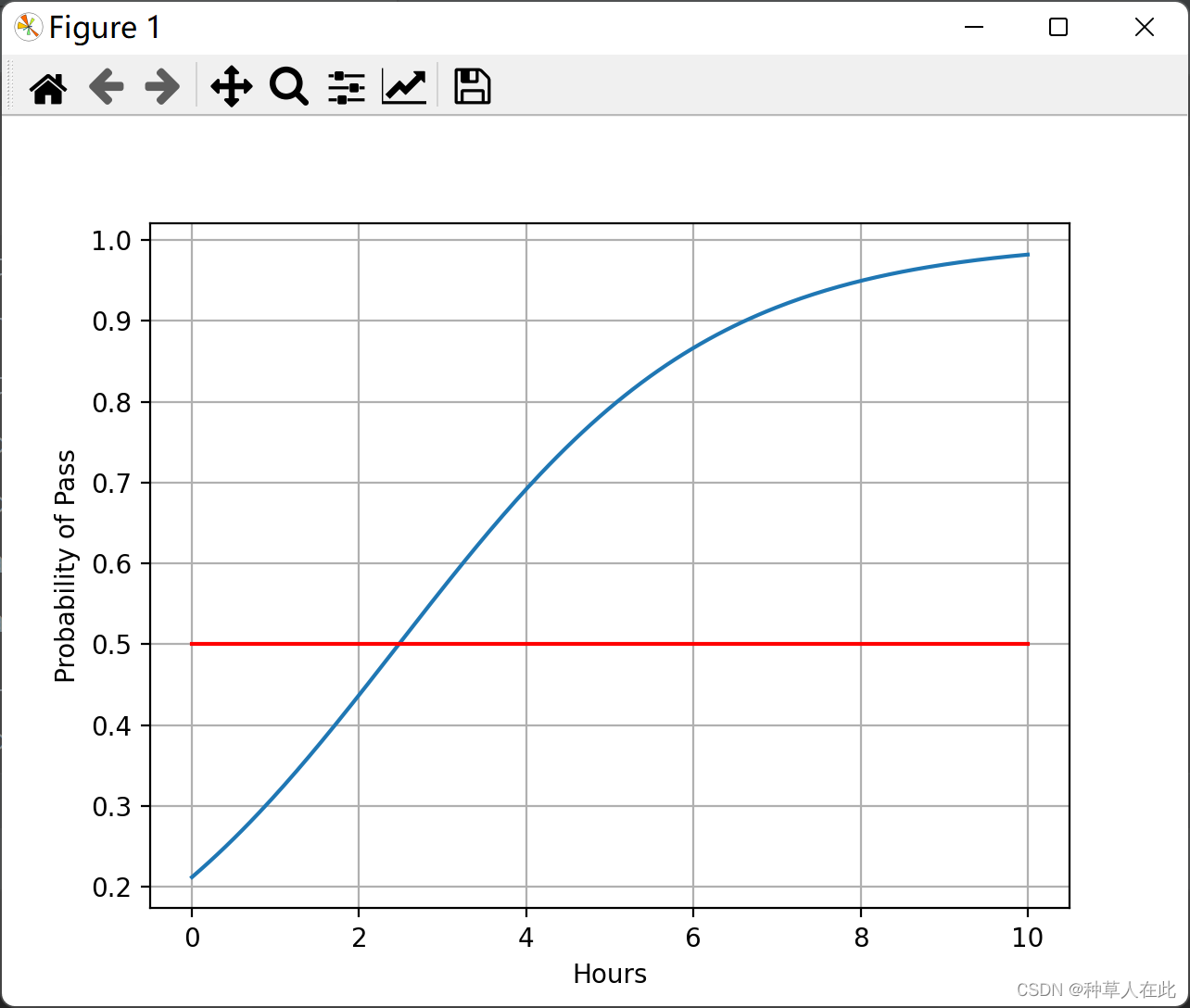
可以看到这个图像非常像logsitc 函数,因为数据经过线性变换,就是缩放、上下平移,然后放入logstic函数,肯定出来就是和logstic函数图像差不多的。
可以看到差不多2.5左右概率就到50%,即过与不过的分界线了。即低于2.5小时,肯定判定不过“0”,超过2.5小时,判定过“1”.