毕业开题答辩很顺利,但是感觉自己真的给自己挖了个大坑啊。想哭。。。。。真的不知道怎么开展自己的工作,还是先补一些基础知识。写一些博客,把之前做的工作记录一下。
最近在看yolov3的网络结构,了解了一下yolov3的cfg文件。
看了很多博客,但是还是理解的不是特别明白,博客中的图片是从别人的博客下载的。
贴一下觉得讲解的很好的博客 https://blog.paperspace.com/how-to-implement-a-yolo-object-detector-in-pytorch/
汇总一下,然后再记录一下自己的理解。
首先,yolov3的网络结构



yolov3进行了五次下采样,提取特征,然后在85层进行上采样,将85层和61层的特征拼接起来(这里的拼接到底是怎么操作的还不明白)同样的操作在98层也进行了。这里应该是采用了FPN的思想,想利用多尺度的特征增加特征的丰富程度,然后达到大目标和小目标的检测效果都很好的效果。
这里面也用到了resnet的思想,进行shortcut的思想来解决网络层数深,梯度消失的情况。
接下来了解了anchor机制。anchor机制是借鉴的fast-rcnn的思想。
首先,anchor应该是指在image原图上的锚框,而不是在特征图上的。anchor是我们自己在程序中设置的,fast-rcnn系列的anchor是在程序中手动设置,而yolov3则是用了k-means的聚类方法自动生成anchors。

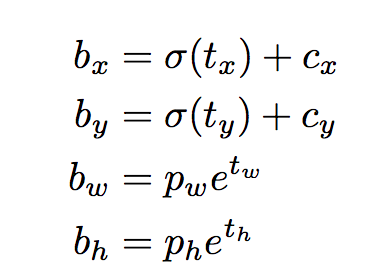
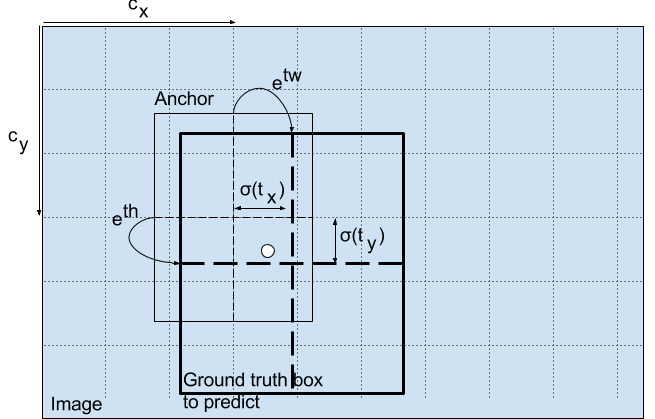
网络实际的预测值为tx、ty、tw、th,根据上图中的四个公式计算得到预测框的中心点坐标和宽高bx、 by、 bw、 bh。其中,cx、 cy为当前grid相对于左上角grid偏移的grid数量。(这部分不是理解的很清楚)。
yolov3的源码在架构网络结构的时候用了很多链表,还在继续看,看不太懂。最近刷leetcode也在看链表(python3).