原文:https://blog.csdn.net/qq_37541097/article/details/81214953
1.Darknet-53 network
在论文中虽然有给网络的图,但我还是简单说一下。这个网络主要是由一系列的1x1和3x3的卷积层组成(每个卷积层后都会跟一个BN层和一个LeakyReLU)层,作者说因为网络中有53个convolutional layers,所以叫做Darknet-53(我数了下,作者说的53包括了全连接层但不包括Residual层)。下图就是Darknet-53的结构图,在右侧标注了一些信息方便理解。(卷积的strides默认为(1,1),padding默认为same,当strides为(2,2)时padding为valid)
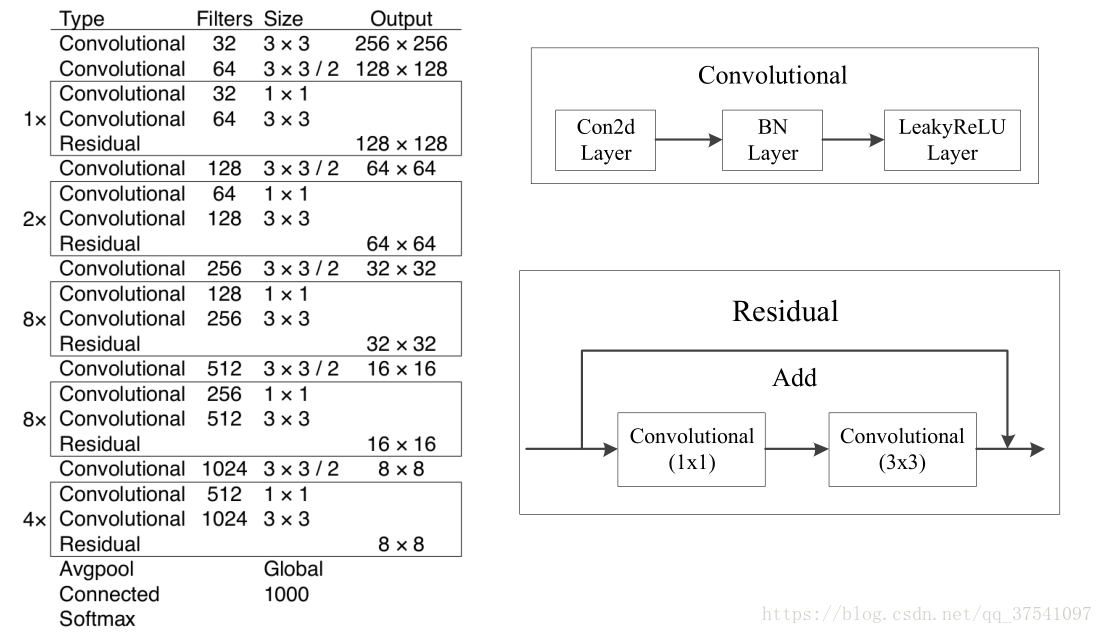
看完上图应该就能自己搭建出Darknet-53的网络结构了,上图是以输入图像256 x 256进行预训练来进行介绍的,常用的尺寸是416 x 416,都是32的倍数。下面我们再来分析下YOLOv3的特征提取器,看看究竟是在哪几层Features上做的预测。
2.Feature Extractor
作者在论文中提到利用三个特征层进行边框的预测,具体在哪三层我感觉作者在论文中表述的并不清楚(例如文中有“添加几个卷积层”这样的表述),同样根据代码我将这部分更加详细的分析展示在下图中。注意:原Darknet53中的尺寸是在图片分类训练集上训练的,所以输入的图像尺寸是256x256,下图是以YOLO v3 416模型进行绘制的,所以输入的尺寸是416x416,预测的三个特征层大小分别是52,26,13。
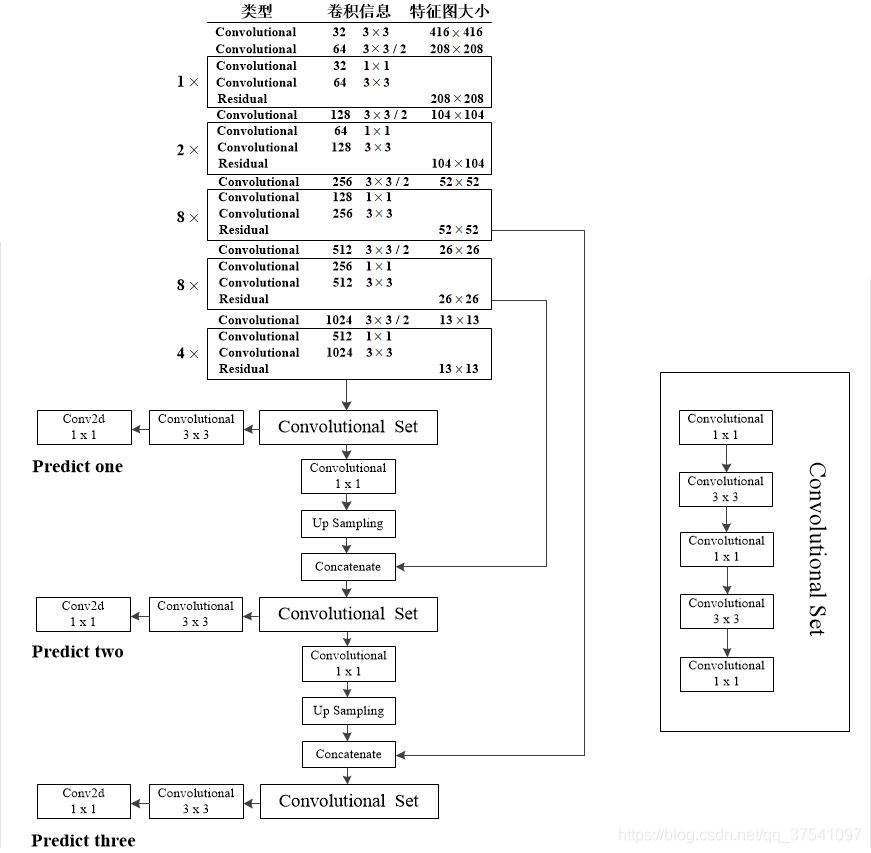
在上图中我们能够很清晰的看到三个预测层分别来自的什么地方,以及Concatenate层与哪个层进行拼接。注意Convolutional是指Conv2d+BN+LeakyReLU,和Darknet53图中的一样,而生成预测结果的最后三层都只是Conv2d。通过上图小伙伴们就能更加容易地搭建出YOLOv3的网络框架了。