YOLOv3是在YOLOv2基础之上的提升,本论文主要包含以下几个方面:1.对YOLOv3的改进;2.改进的效果;3.一些“didn't work”的处理;4.这些改进的意义。
the deal
bounding box prediction
延续YOLOv2的做法,仍使用dimension cluster来生成anchor box作为prior,网络仍输出X进行坐标预测,左上角偏移量(),bounding box prior宽高为
,预测结果为:
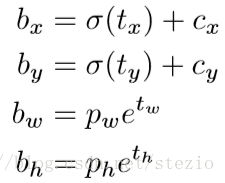
训练时采取平方和形式计算loss。对于GT预测和预测值
,梯度为
。
YOLOv3对于每个bounding box采用逻辑回归预测一个objectness score。如果一个bounding box与一个GT的IOU在所有bounding box中最高,这个objectness score置为1。如果一个bounding box prior不是最好的但是与一个GT的IOU高于一个阈值,则按照Faster RCNN的做法(添加正样本标签)。在这里使用0.5作为阈值,然而与Faster RCNN有所不同,对于每一个GT只指派一个bounding box prior,而如果一个bounding box没有被指派到一个GT,则不会参与坐标和class预测的计算,只会影响objectness。
class prediction
每个bounding box对于其可能包含的类别采用多重标签分类。作者认为softmax对于好的表现“没有必要”,因此简单地使用独立的逻辑分类器。在训练时对分类预测采用binary cross-entropy损失。即:
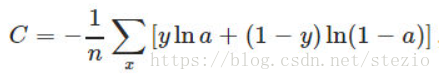
对于binary cross-entropy与softmax对比见:https://blog.csdn.net/wtq1993/article/details/51741471
这一公式在对更复杂的域(例如Open Images Dataset)的处理上有所帮助。在这一类数据集中有重叠的标签(比如女性和人类),使用softmax强行加上了每个box只有一个类别这一假设,然而一般不是这种情况。多标签的方法更有利于给数据建模。
值得一提的是,这里是对YOLOv2的改进,并没有用到YOLO9000中提出的WordTree,因此不存在对同义词采用softmax而上下义词计算不互相影响的情况。因此才会有softmax对一类的预测会压缩对另一类别(父类或者子类)置信度的问题,而对每一类采用逻辑回归则没有这个问题,这一说法。
predictions across scales
在YOLOv2中的Fine-Grained Features中用到了一个passthrough layer,将26*26的特征图转变为13*13的特征图并与原始特征图连接,以获得更好的细粒度特征。在YOLOv3中则强化了这种做法。
YOLOv3借鉴了FPN的做法,在3个不同尺度的特征图上进行预测。
每种尺度预测3个box, anchor的设计方式仍然与YOLOv2相似使用k-means聚类,得到9个聚类中心,将其按照大小均分给3个尺度。
-
尺度1:在基础网络之后添加一些卷积层再输出box信息;
-
尺度2:从尺度1中的倒数第二层的卷积层上采样(x2)再与最后一个16x16大小的特征图相加,再次通过多个卷积后输出box信息,相比尺度1变大两倍;
-
尺度3:与尺度2类似,使用了32x32大小的特征图。
feature extractor
在YOLOv2基础上借鉴Resnet添加了shortcut connection,使得网络达到了53层,称为Darknet-53。
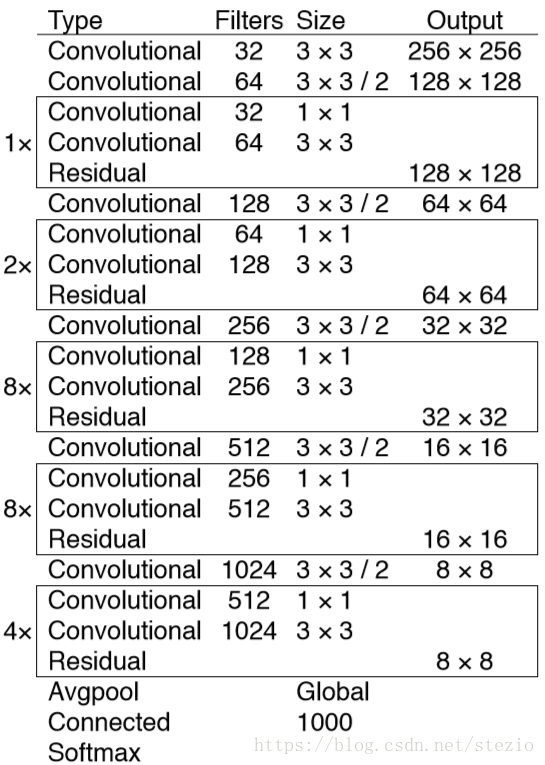
该网络比Darknet-19“powerful”,比ResNet-101和ResNet-152“efficient”:
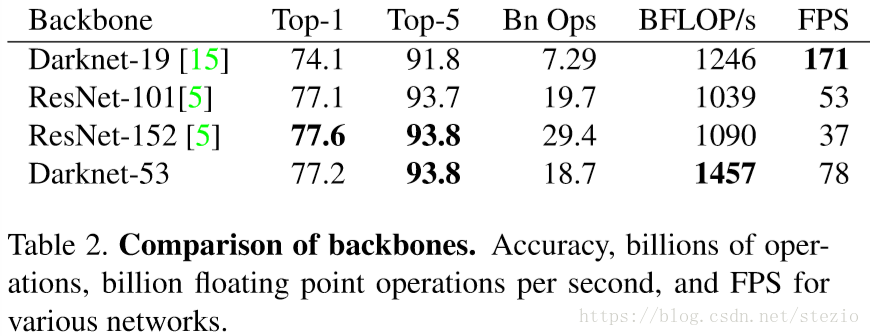
测试利用Titan X,基于完全相同的设置并在256*256的single crop上进行。Darknet-53与现有最优分类器表现相当但消耗更少的浮点运算并取得更快的速度。Darknet-53也取得了最高的BFLOP/s,作者认为这说明该网络结构更好地利用了GPU,使其更有效因而更快。同时说明ResNet在层之间创造了太多的路径,因而不高效。
Training
在整张图片上进行训练,没有使用hard negative mining。使用多尺度训练,数据增强,BN等等。使用Darknet神经网络结构来训练和测试。
How We Do
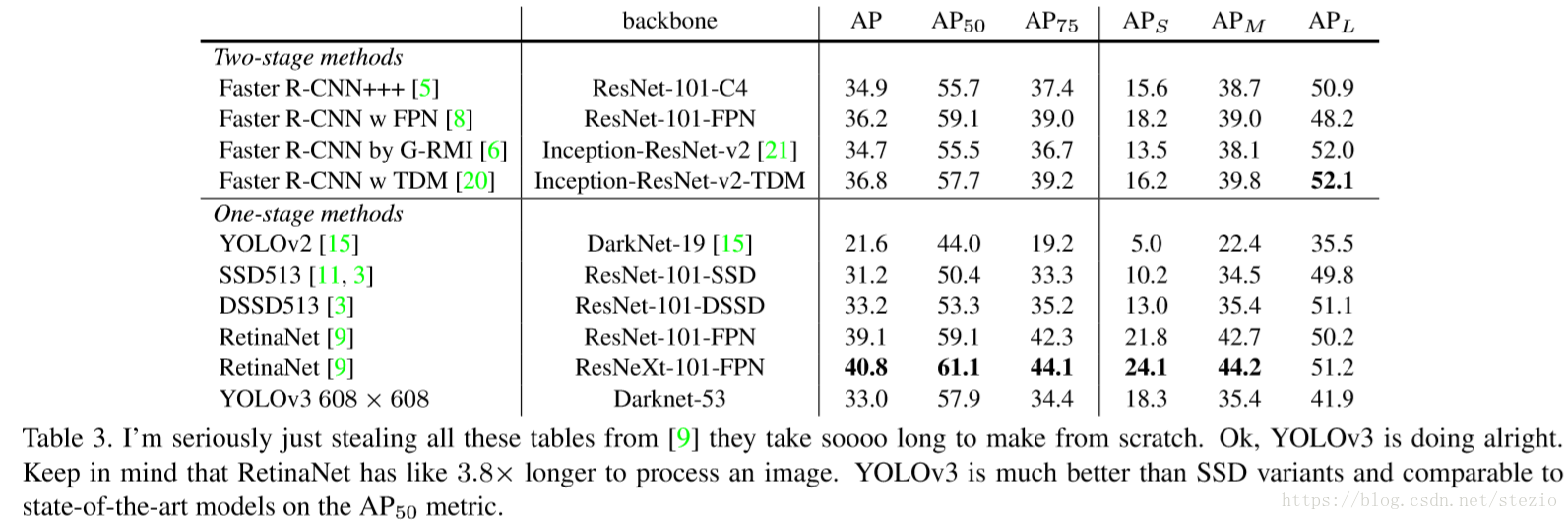
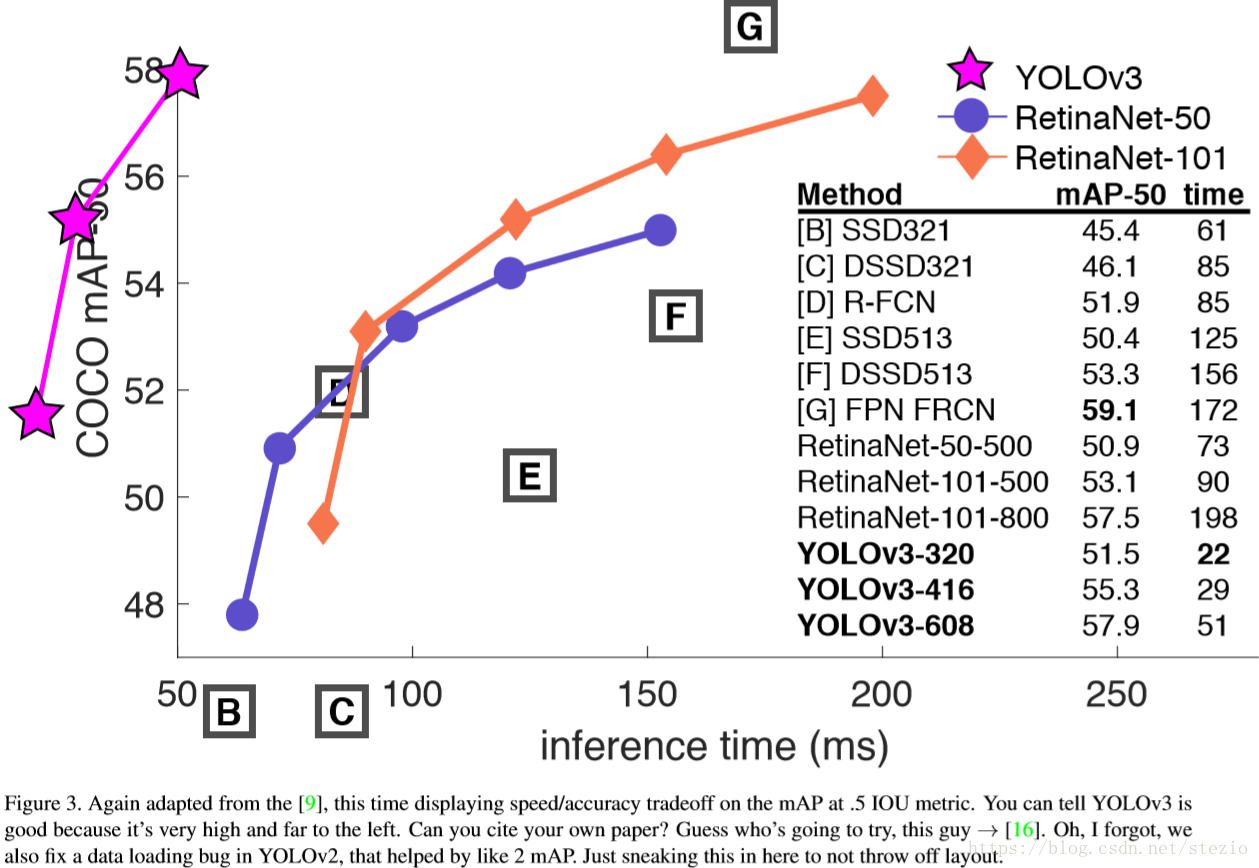
表中AP规则采用COCO数据集规则,在此规则下YOLOv3与SSD变体(DSSD513)平分秋色但3倍快于它。
在“旧的”mAP标准下,当IOU=0.5时,YOLOv3取得与RetinaNet相当的效果,但是当IOU阈值增大时,AP下降明显。
YOLOv2在对小目标的检测不太好,这一点在YOLOv3中得到很大的改进,但是对中等或者大目标的效果相对较差,作者认为对此需要“more investigation”。
作者画出了在IOU阈值为0.5下的AP曲线,认为YOLOv3“better and faster”。
things we tried that didn't work
作者给出了一些“didn't work”的改进如下。
Anchor box x,y offset predictions
作者尝试采用正常的anchor box预测机制,使用线性激活对于box的宽高预测x,y偏移量,结果这一方法降低了模型的稳定性而表现不好。
Linear x,y predictions instead of logistic
尝试采用线性激活而不是logistic activation直接预测x,y偏移量,导致mAP的下降。
Focal loss
尝试使用focal loss,使得mAP下降了2%。作者认为YOLOv3分开了对objectness和conditional class的预测因而对此具有一定的鲁棒性,而这一问题正是focal loss所想要解决的。是因为对于大多数样本是否没有loss从class预测中传出还是其他原因,作者也没有给出答案。对于focal loss的解析见https://blog.csdn.net/u014380165/article/details/77019084
Dual IOU threshholds and truth assignment
Faster RCNN在训练时使用了两个IOU阈值,大于0.7为正样本,小于0.3为负样本,0.3-0.7之间被忽略。作者采用了相似的策略却没有取得好效果。作者认为YOLOv3对此的处理达到了局部最优,而这些方式需要通过对稳定训练的一些调整才能最终产生较好的效果。
What This All Means
作者在此讲了一堆冷笑话。。。