Multi-View Gait Recognition Based on A Spatial-Temporal Deep Neural Network论文翻译和理解
翻译格式:一句英文,一句中文
结合图来讲解
ABSTRACT
ABSTRACT This paper proposes a novel spatial-temporal deep neural network (STDNN) that is applied to multi-view gait recognition. STDNN comprises a temporal feature network (TFN) and a spatial feature network (SFN). In TFN, a feature sub-network is adopted to extract the low-level edge features of gait silhouettes. These features are input to the spatial-temporal gradient network (STGN) that adopts a spatial temporal gradient (STG) unit and long short-term memory (LSTM) unit to extract the spatial-temporal gradient features. In SFN, the spatial features of gait sequences are extracted by multilayer convolutional neural networks from a gait energy image (GEI). SFN is optimized by classification loss and verification loss jointly, which makes inter-class variations larger than intra-class variations. After training, TFN and SFN are employed to extract temporal and spatial features, respectively which are applied to multi-view gait recognition. Finally, the combined predicted probability is adopted to identify individuals by the differences in their gaits. To evaluate the performance of STDNN, extensive evaluations are carried out based on the CASIA-B, OU-ISIR and CMU MoBo datasets. The best recognition scores achieved by STDNN are 95.67% under an identical view, 93.64% under a cross-view and 92.54% under a multi-view. State-of-the-art approaches are compared with STDNN in various situations. The results show that STDNN outperforms the other methods and demonstrates the great potential of STDNN for practical applications in the future.
摘要
摘要-本文提出了一种应用于多视角步态识别的新型时空深度神经网络(STDNN)。STDNN包括时间特征网络(TFN)和空间特征网络(SFN)。在TFN中,采用特征子网络来提取步态轮廓的局部边缘特征,然后这些特征被输入到空间 - 时间梯度网络(STGN),其采用空间时间梯度(STG)单元和长短期记忆(LSTM)单元来提取空间 - 时间梯度特征。在SFN中,步态序列的空间特征由多层卷积神经网络从步态能量图像(GEI)提取。 SFN通过分类损失和验证损失共同进行优化,这使得类间变化大于类内变化。经过训练后,TFN和SFN用于提取时间和空间特征,分别应用于多视角步态识别。最后,通过由每个个体的步态差异学习到的组合预测概率来识别个体。为了评估STDNN的性能,我们在数据集CASIA-B,OU-ISIR和CMU MoBo进行了充分的评估。在相同视角下,STDNN获得的最佳识别率为95.67%,在交叉视图下为93.64%,在多视图下为92.54%。将现在领先的几种方法与STDNN在不同条件下进行比较。结果表明,STDNN优于其他方法,并显示了STDNN在未来实际应用中的巨大潜力。
先看总结构图:
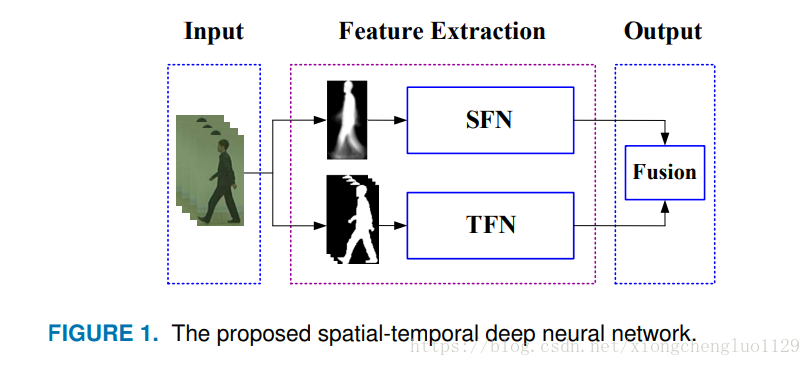
再细看看

看完了? 然后再分别来看 SFN和TFN
A. SPATIAL FEATURE NETWORK (SFN) —空间特征网络
In this section, the proposed spatial feature network (SFN) is adopted to extract the spatial features of a gait sequence. Its working mechanism is as follows.
在这节当中,我们提出能从步态序列中提取空间特征的空间特征网络(SFN),它的工作原理如下:
1) Spatial Feature Extraction
A spatial feature network comprises three parts, the input layer, the feature extraction network and the loss function layer. During the training phase, a pair of GEIs is input to the multi-layer convolutional neural networks in turn, which are adopted to extract the spatial features of a gait sequence. The last convolution layer which is connected to the fullyconnected layer, by which high dimensional feature vectors are generated. SFN is optimized based on two supervised signals, classification loss and verification loss.
空间特征网络包括三个部分,输入层,特征提取网络和损失函数层。在训练阶段,依次将一对GEI输入到多层卷积神经网络中,用来提取步态序列的空间特征。最后一个卷积层后接一个全连接层,通过该层生成高维特征向量。SFN基于两个监督信号对分类损失和验证损失进行优化。
During the testing phase, the network optimized by the two loss functions is adopted to extract the spatial features, based on which the input GEIs pair is judged as to whether it belongs to the same subject or not. Many methods have recently been proposed to extract the effective spatial features based on convolution neural networks [24], [39].

在测试阶段,用训练好的网络来提取空间特征,在此基础上判断输入的一对GEI是否属于同一个人。 最近提出了许多方法来提取基于卷积神经网络的有效空间特征[24],[39]。
To extract the effective spatial features of a gait sequence, a ConvNet with four convolutional layers is designed as the base network model of the spatial feature network. Furthermore, two other kinds of CNN-based networks are selected to compare with SFN on gait recognition accuracy, which is discussed in detail in section V.C.
空间特征网络的基础网络模型是具有四个卷积层的ConvNet,这样设计是为了提取步态序列的有效空间特征。 此外,选择另外两种基于CNN的网络来与的SFN进行步态识别精度比较(这里仅仅是比较他们两个所提取空间特征哪个更有效),这将在 V.C. 部分中详细讨论。
The process of gait spatial feature extraction comprises three parts. In the data preparation phase, GEIs are generated using the method described in section III.C. Then, the sample pair is sent to ConvNet in turn, which is adopted to extract high dimensional feature vectors. These vectors output by ConvNet are capable of representing the spatial features of the input samples, based on which softmax layer is used to predict the categories of the input samples.
步态空间特征提取的过程包括三个部分:在数据准备阶段,使用第 III.C 部分中描述的方法生成GEI。然后,将样本对依次送入到ConvNet,用于提取高维特征向量。 ConvNet输出的这些向量能够表示输入样本的空间特征,softmax层基于这些向量来预测输入样本的类别。
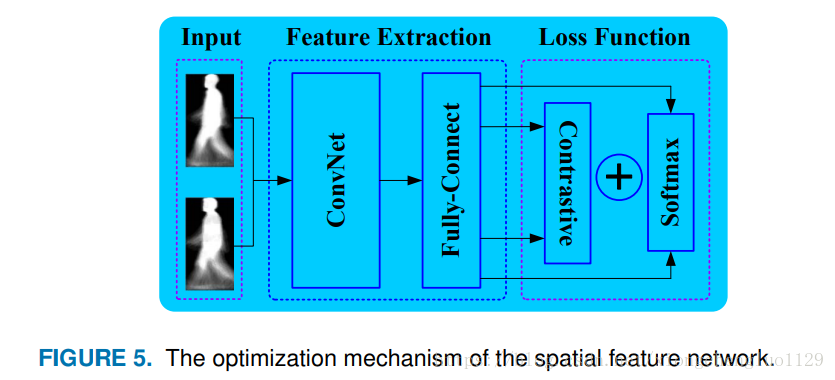
GEI is a kind of small sample due to little information,which is a barrier in identifying different subjects by solely applying the aforementioned method. Inspired by the promising performance of the method proposed in [40], an additional verification signal is adopted, which not only enlarges inter-class variations but also reduces intra-class variations. The two supervisory signals are implemented using two kinds of loss functions which work together to compel SFN to focus on the identity-related feature itself, rather than other influential factors, such as wearing noise, illuminations and so on. The working mechanism of SFN is shown in Figure 5.
由于GEI所携带的信息很少,仅仅应用上述方法来识别不同人的身份效果不佳。 受到[40]中提出的一种比较有前景的方法的启发,我们采用了额外的验证信息,这种验证信息不仅能扩大类间变化而且还可以减少了类内变化。 这两个监控信号是由两种损失函数实现的,由两种损失函数共同作用来迫使SFN专注于身份相关的特征本身,而不是其他影响因素,如佩戴物,噪声,照明等。 SFN的工作机制如图5所示。
The first supervisory signal is verification loss, which is adopted to reduce the intra-class variation of gait samples.
第一个监控信号是验证损失,用于减少步态样本的类内变化。(好强的监督信息)
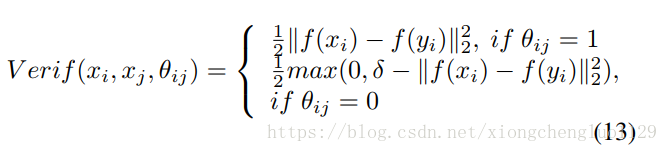
Based on the L2 norm [41], verification loss is defined in Equation (13) where and denote two input GEIs, and and denote the feature vectors output by the fully connected layer . When = 1 this means that and are from the same gait individual, and features and are enforced to be close. On the contrary, when =0 this means that and are from different persons. In this case, the features and are pushed apart. The size of the margin is denoted as , which is smaller than the distance between the features carried by different subjects.
基于L2范数[41]的验证损失在等式(13)中定义,其中 和 表示两个输入GEI, 和 表示由完全连接的层Fc6输出的特征向量。当 = 1时,这意味着 和 是同一个人的步态能量图,并且特征 和 的差异会在训练过程中逐步变小。 相反,当 = 0时,这表示 和 是不同人的步态能量图。 在这种情况下,特征 和 在训练过程中差异会变大。 表示边界的大小,其小于不同主体产生的特征之间的距离。这里说的就是对比损失函数的定义。
方程(15)中
的分母中
的下标
应该改为
,
= 后求和符号的起始下标应该为
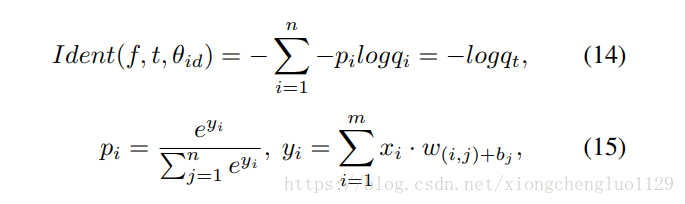
The second supervisory signal is classification loss. After being optimized by this supervisory signal, SFN is adopted to identify different subjects. This loss function is defined in Equation (14)-(15) where denotes the spatial feature vector, pi denotes the target probability distribution, when = 0 for all except = 1 for the target class . and denotes the predicted probability that the input sample belongs to a specific class. The output of the softmax layer is the probability distribution of the input samples. denotes the dimensions of the feature output by the fully-connected layer, is the input feature image, and and denotes the bias and weights between different layers respectively.
第二个监督信号是分类损失。 对该监督信号进行优化之后,就可以采用SFN来识别不同的人。 该损失函数在等式(14) - (15)中定义,其中 表示空间特征向量, 表示目标概率分布,当 = 0时,对于所有 ,除了 = 1对于目标类别 。 表示输入样本属于特定类的预测概率。 softmax层的输出是输入样本的概率分布。 表示全连接层输出的特征的尺寸, 是输入特征图像, 和 分别表示不同层之间的偏差和权重。
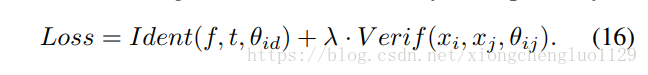
Classification loss and verification loss are used to optimize SFN jointly according to Equation (16). Refer to [24], the hyperparameter λ is set by an empirical value (λ = 0.05). This value ensures SFN achieves the best recognition rate.
分类损失和验证损失用于根据等式(16)一起优化SFN。 参考文献[24],超参数λ由经验值(λ= 0.05)设定。 该值可确保SFN实现最佳识别率。
2) Implementation Details
As shown as Figure 5, we choose a pair of GEIs as the input of SFN at the beginning of the experiment. We choose one GEI from the gallery and the other from probe. In this paper, the term ’gallery’ refers to the training data set and the term ’probe’ refers to the testing data set. GEIs are sent to Conv1 respectively, where the first three layers of the convolutional networks share the network parameters. The size of the original GEI is set as 88×128. The first convolution layer contains pair-filters and all filters are of 16 kernels of size 4×4 with a stride of one. After this, we get 16 feature maps sized 85×125. We extend the GEI pair with a pad of 1 pixel in a horizontal and vertical direction. The processes of local response and max pooling are connected to the outputs of Conv1 and the size of the max-pooling kernel is 2×2 with a stride of 2. Finally, 16 feature maps sized 63×43 are obtained. For the three subsequently shared convolution layers, we design model parameters in the same way. The feature maps output by the last convolution layers are sent to the fully-connected layers Fc5 and Fc6 in turn. Then we perform local response normalization for the feature vectors, the result of which are sent to the softmax loss in which the distance metric is implemented based on the L2 norm. Meanwhile, the two feature vectors extracted from the GEI pair by the last convolution layer are sent to contrastive loss, which is used to verify whether the GEI pair belongs to the same subject or not. The learning rate is initialized at 0.001 and the weight decay is set as 0.005. The momentum is set as 0.9 and the tanh function is adopted as the activation function.
如图5所示,在实验开始时,我们选择一对GEI作为SFN的输入。我们从 gallery set 中选择一张GEI,从probe set 中选择另一张GEI。在本文中,术语 “gallery” 指的是训练数据集,术语 “probe” 指的是测试数据集。 GEI分别被输入到Conv1,其中前三个卷积层共享网络参数。原始GEI大小设置为88×128。第一个卷积层包含成对的滤波器,所有滤波器的核数为16核,大小为4×4,步长为1也就是说,这16个滤波器会对这两张GEI同时进行卷积操作,滤波器参数共享。在此之后,我们得到16个大小为85×125的特征图谱。我们使用1像素的水平和垂直方向扩充GEI对。在Conv1之后紧接着的是一个局部响应和最大池层,并且最大池化层参数设置为:核的大小是2×2,步幅为2。最后,获得16个大小为63×43的特征图谱。在最大池化层之后,紧接着的是三个权重共享的卷积层,我们以相同的方式设计模型参数 <同Conv1> 。由最后的卷积层输出的特征图谱依次被输入到全连接层Fc5和Fc6。然后,我们对特征向量进行局部响应归一化,其结果被输入到softmax来计算损失,损失的度量是基于L2范数的。同时,由最后一个卷积层从GEI对中提取的两个特征向量被用来计算对比度损失,用于验证GEI对是否属于同一对象。学习率初始化为0.001,权重衰减设定为0.005。动量设定为0.9,采用tanh函数作为激活函数。 这里的网络结构和论文<< A comprehensives tudy on cross-view gait based human identification with deep CNNs>>中的结构如出一辙,就多加了一个对比损失函数,但是我做过实验,加了对比损失函数和不加对比损失函数效果相当,甚至正确率还降低了1个百分点。所以我对这个SFN的网路结构设计持保留态度了
B. TEMPORAL FEATURE NETWORK (TFN)
The proposed TFN consists of two parts: feature sub-network (FSN) and spatial-temporal gradient network (STGN). As shown in Figure 4, the normalized silhouettes of each gait sequence are sent to FSN to extract the low-level spatial feature. Then these feature vectors are taken as the input of STGN. The feature vectors extracted from adjacent frames are sent to STG after the convolution operation. Due to the capacity of LSTM in storing and accessing temporal features, the LSTM unit is integrated in TFN, which is adopted to extract the dynamic dependent features of the output of the gait sequences by STG. Finally, these feature vectors are transferred to the loss layer through the fully connected layer Fc5. After being trained by the softmax loss, TFN is capable of effectively improving the accuracy of gait recognition effectively by extracting the temporal features of the gait sequence. The working mechanisms of FSN and STG are introduced as follows.
所提出的TFN由两部分组成:特征子网(FSN)和空间 - 时间梯度网络(STGN)。 如图4所示,归一化好的每个步态序列轮廓被输入到FSN用以提取低层次的空间特征。然后将这些特征向量 作为STGN的输入。 在卷积运算之后,从相邻帧提取的特征向量被输入到STG。 由于LSTM具有存储和获取时间特征的能力,LSTM单元被集成在TFN中,它从STG的输出中提取步态序列的动态依赖特征。最后,这些特征向量通过全连接层Fc5转化到损失层。在经过softmax损失训练后,TFN能够通过提取步态序列的时间特征有效地提高步态识别的准确性。 FSN和STG的工作机制介绍如下。
1) Silhouette Feature Extraction
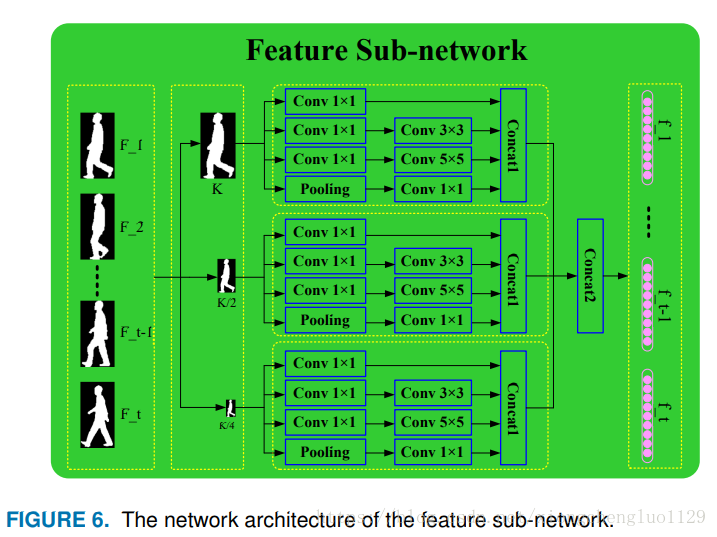
Before extracting spatial-temporal gradient features, the feature sub-network is employed to extract the edge features of gait silhouettes of 128×88. Inspired by the BN-inception proposed in [39], the stacked convolution layers with multiscale
filters are designed in this section. The gait silhouettes of different sizes, such as K, K/2, K/4, are taken as input. AS shown in Figure 6, three kinds of gait silhouettes of different sizes are sent to the inception module used to extract the low-level features. The three modules share weights. The network parameters of the convolution layer and pooling layer are set to be the same as the BN-inception. At first, convolution units with a filter size 1×1 and one pooling unit are adopted to extract the fine-grained features of the gait silhouettes. The feature vectors output by the following three layers are sent to three convolution units, with a filter size such as 1×1, 3×3, 5×5, to further extract gait features. The features output by the last convolution layer are combined by concat1. Finally, the feature vectors extracted from the three kinds of gait silhouettes of different scales are concatenated by concat2. After the feature extraction conducted by feature subnetwork, the original gait silhouette sequence
is transformed into the low-level feature vectors
that are adopted as the input of STGN in the next section.
在提取时空梯度特征之前,采用特征子网络提取128×88的步态轮廓的边缘特征。受[39]中提出的BN-inception的启发,本节在用堆叠的卷积层中使用多尺度卷积核。将不同尺寸的步态轮廓(例如K,K / 2,K / 4)作为输入。如图6所示,将三种不同大小的步态轮廓输入到用于提取低层特征的 inception 模块。这三个模块共享权重。卷积层和池化层的网络参数设置为BN-inception。首先,采用滤器的尺寸为1×1的卷积单元和一个pooling单元来提取步态轮廓的细粒度特征。这种细粒度特征在论文《Beyond View Transformation Cycle-Consistent Global and Partial Perception Gan for View-Invariant Gait Recognition》的AAN结构中 W x H 概率结构的设计。由后面三层输出的特征向量被输入到三个具有诸如1×1,3×3,5×5的滤波器大小的卷积单元,以进一步提取步态特征。最后一个卷积层输出的特征由concat1层进行拼接。最后,从三种不同尺度的步态轮廓中提取的特征向量由concat2层进行拼接。在由特征子网进行特征提取之后,原始步态轮廓序列 被转换为低层特征向量 ,这些低层特征向量被当做STGN(下一节介绍)的输入。
2) Spatial-Temporal Gradient Unit (这个网络感觉设计的很清奇)
As discussed in section III.D, the spatial-temporal gradient features are taken as temporal feature instead of the optical flow image, which is capable of speeding up the process of temporal feature extraction. Figure 7 illustrates the detailed process of spatial-temporal gradient feature extraction. According to Equation (12), the spatial-temporal gradient feature consists of two parts, namely the spatial gradient feature and the temporal gradient feature, which are extracted by the Sobel and subtraction operations, respectively. The features output by the feature sub-network are taken as the input of STG. After feature extraction is implemented by a convolution layer with a 1×1 filter, the features of adjacent frames are input to the Conv-based Sobel operator and subtracting operator that are employed in extracting the spatialtemporal gradient features.

如III.D所述,空间 - 时间梯度特征被视为时间特征而不是光流图像,其能够加速时间特征提取的过程。 图7说明了时空梯度特征提取的详细过程。 根据等式(12),时空梯度特征由两部分组成,即空间梯度特征和时间梯度特征,它们分别由Sobel和减法运算提取。特征子网输出的特征作为STG的输入。在经过1×1滤波器的卷积层实现特征提取之后,将相邻帧的特征输入到基于Conv的Sobel算子和用于提取空间时间梯度特征的减法算子当中。
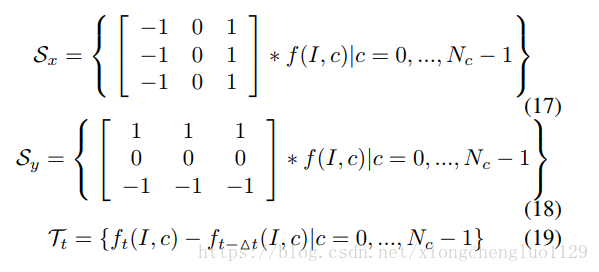
where denotes the channel of the basic silhouette feature . and denote the image gradient along x and y directions respectively, which corresponds to the spatial gradient feature calculated by the Sobel operator in Equation (17)-(18). The constant denotes the number of channels of feature , ∗ indicates a convolution operation. Furthermore, denotes the image gradient along a temporal direction. The temporal gradient features among the silhouette sequences are obtained by element-wise subtraction according to Equation (19). In the STG unit, a convolution layer with a filter size of 1×1 is connected to the input basic features before the Sobel and subtraction operations to reduce the number of channels. Finally, the spatial gradient features , , temporal gradient feature and the features output by the front STG unit are concatenated and output。
其中 表示基本轮廓特征 的第c个通道特征。 和 分别表示沿x和y方向的图像梯度,其对应于由Sobel算子在等式(17) - (18)中计算的空间梯度特征。 常数 表示特征 的通道数,* 表示卷积运算。 此外, 表示沿时间方向的图像梯度。 根据等式(19)通过逐元素减法获得轮廓序列之间的时间梯度特征。 在STG单元中,在Sobel和减法操作之前,将具有1×1滤波器尺寸的卷积层连接到输入的特征图谱来实现降维。 最后,将空间梯度特征 , ,时间梯度特征 和前STG单元输出的特征拼接作为Spatial-Temporal Gradient Unit 的输出。
3) Temporal Feature Extraction
In this section, the temporal feature extraction process for the gait sequence is described in detail, which consists of three parts. First, the low-level silhouette features are extracted by the feature sub-network. Then, these features are input to the spatial-temporal gradient feature extraction network. As shown in Figure 4, the low-level feature vectors f1, f2, …, ft output by the feature sub-network are first filtered by a 1×1 convolution. After this, the spatial-temporal gradient features are extracted from the adjacent frames by the STG unit. The output of STG is sent to the LSTM unit discussed in section III.B, which is employed in further extracting the temporal features of the gait silhouettes. The temporal features carried by the gait silhouette sequence are extracted by the multilayer stacked STG networks connected by the LSTM units. Finally, the feature output by the last STG unit is input to the loss layer through the fully-connected layer Fc5. The softmax layer is adopted to predict the category of the sample based on the features extracted by TFN, which is defined as follows:
在本节中,详细描述了步态序列的时间特征提取过程,该过程由三部分组成。首先,由特征子网提取低级轮廓特征。然后,将这些特征输入到时空梯度特征提取网络。如图4所示,首先通过1×1卷积对特征子网输出的低层次特征向量 进行滤波。此后,由STG单元从相邻帧中提取空间 - 时间梯度特征。STG的输出当做在章节III.B中讨论的LSTM单元的输入,其用于进一步提取步态轮廓的时间特征。由步态轮廓序列承载的时间特征由LSTM单元连接的多层堆叠STG网络提取。最后,最后一个STG单元输出的特征通过全连接层Fc5输入到损失层。采用的softmax层根据TFN提取的特征预测样本的类别,定义如下:
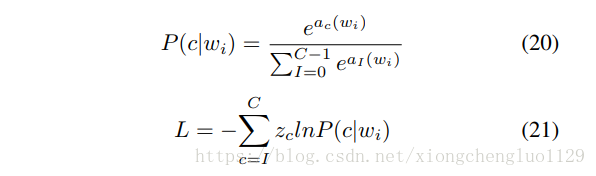
In Equation (20), is obtained from the last hidden layer for the relevant class c, and denotes the accumulated value. The category of the sample is denoted as i. Finally, TFN is optimized by the objective function named cross-entropy loss that is defined as Equation (21), ∈ (0, 1). The predicted probability of gait category c is denoted as . The goal of optimization is to minimize the maximum likelihood.
在等式(20)中, 是从相关类c的最后隐藏层获得的,并且 表示累加值。 样本的类别表示为i。 最后,TFN通过称为交叉熵损失的目标函数进行优化,该目标函数被定义为等式(21), ∈(0,1)。 步态类别c的预测概率表示为 。 优化的目标是最小化最大可能性。
4) Implementation Details
C. FUSION STRATEGY
To improve the accuracy of gait recognition, SFN and TFN are employed. As shown in Figure 4, the cross-entropy loss function and verification loss function are used jointly to optimize the network parameters of SFN, based on GEIs. TFN takes the softmax loss to optimize its network weights based on the normalized gait silhouettes. After training, the SFN model and TFN model are adopted to extract the spatialtemporal feature used for gait recognition. The recognition scores are fused by the strategies such as score-level fusion and SVM-based one. Their performance is evaluated later.
为了提高步态识别的准确性,本方法采用了SFN和TFN结构。如图4所示,使用基于GEI的交叉熵损失函数和验证损失函数来优化SFN的网络参数。TFN根据归一化的步态轮廓,采用softmax损失来优化其网络权重。 训练完毕后,采用SFN模型和TFN模型提取用于步态识别的时空特征。 识别率通过多种策略组合决定,比如,分数级融合和基于SVM的策略融合。 他们的表现将在以后评估。