作者
德克萨斯农工大学
阿里巴巴集团
香港理工大学
Abstract
在各种在线服务中,顺序推荐变得越来越重要。它的目的是根据用户的历史交互来建模用户的动态偏好,并预测他们的下一个项目。真实系统上累积的用户行为记录可能非常长。这些丰富的数据带来了追踪用户实际兴趣的机会。之前的努力主要集中在根据相对较新的行为提出建议。然而,整个顺序数据可能没有得到有效利用,因为早期的交互可能会影响用户当前的选择。此外,在对每个用户执行推理时扫描整个行为序列已经变得无法忍受,因为现实世界中的系统需要较短的响应时间。为了弥补这一差距,我们提出了一种新的长序列推荐模型,称为基于动态记忆的注意力网络(DMAN)。它将整个长行为序列分割成一系列的子序列,然后训练模型并维护一组记忆块,以保持用户的长期兴趣。为了提高存储器保真度,DMAN通过最小化辅助重构损失来实现动态地将每个用户的长期兴趣抽象为它的自己的内存块。在动态记忆的基础上,可以明确提取用户的短期和长期兴趣,并在此基础上对用户的兴趣进行分析。结合起来,进行高效的联合推荐.实验再四个基准数据集的结果表明,我们的模型在捕捉长期依赖性方面比各种最先进的顺序模型更有优势。(可以获取长短期的兴趣,但是主要是在长期兴趣上)
以前的问题
为了捕捉用户建模的顺序动态,已经提出了各种顺序推荐方法来基于用户过去的行为进行推荐(Hidasi等人。2015年;唐和王,2018年;谭恩美等人。2021年)。他们的目标是根据用户的历史交互,预测用户可能与之交互的下一个(或多个)项目。最近,大量建立在顺序神经网络基础上的尝试,如递归神经网络(RNNS)、卷积神经网络(CNNS)和自我注意网络,在各种推荐场景中都取得了令人振奋的结果(Hidasi和Karatzoglou 2018;Yuan等人)。2019年;Yan等人。2019年;Sun等人。2019年;张等人。(2018年)。基本范式是基于行为序列使用各种顺序模块将用户的历史交互编码到向量中,行为序列是通过按时间顺序对她/他的过去行为进行排序而获得的。
在本文中,我们的目标是探索具有超长用户行为序列的顺序推荐。
行为序列中的挑战:
- 响应时间要快,但是序列长,之前的改进也会导致复杂度高
- 建模时注重短期兴趣
- 确定下一个推荐,很难确定长期和短期兴趣的权重
为了解决上述局限性,我们提出了一种新颖的 基于动态记忆的自我关注网络,被称为 DMAN,对长行为序列数据进行建模。它提供了 标准的自注意网络,以有效地捕捉用户建模的长期依赖性。为了提高模型
效率,DMAN将整个用户行为序列截断为几个连续的子序列,并优化了 的模型序列。具体来说,就是推导出一个循环注意网络,利用模型之间的关联性。相邻序列进行短期兴趣建模。同时,引入另一个注意力网络来测量 超越连续序列的依赖性,以实现长期 基于动态记忆的兴趣建模,在相邻序列前保留用户行为。最后。两个方面的利益通过神经门控网络自适应整合,进行联合推荐。为了提高 记忆保真度,我们进一步开发了一种动态的记忆 网络,有效地更新内存块序列 由顺序使用辅助重建损失。综上所述,本文的主要贡献如下。
- 提出了一种基于动态记忆的注意力网络dman,用于对长行为序列进行显式、自适应的用户建模,并支持高效推理。
- 我们推导出一种动态记忆网络,将用户的长期兴趣按顺序动态抽象为外部记忆序列。
The Proposed DMAN Model

短期兴趣:
问题:以前的短期会缺失重要的上下文信息。
为了解决这一局限性,我们将rnn中的递归概念引入到自我注意网络中,并构建一个序列级的递归注意网络,使信息在相邻序列之间流动。特别地,我们使用为最后一个序列计算的隐藏状态作为下一个序列建模的附加上下文。
隐藏层计算:
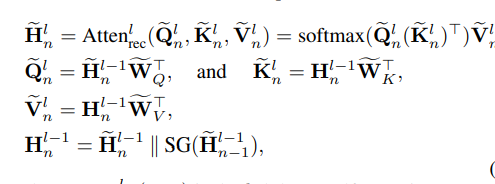

使用最后一个隐藏层状态来表示短期兴趣
长期兴趣:
我们维护一个外部存储矩阵M∈R m×D,以明确存储用户的长期偏好,其中m是存储插槽的数量。 每个用户都与一个内存关联。 理想情况下,内存可以与短期兴趣模型互补,以捕获相邻序列之外的依存关系。
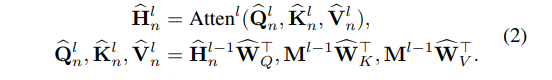
整体架构
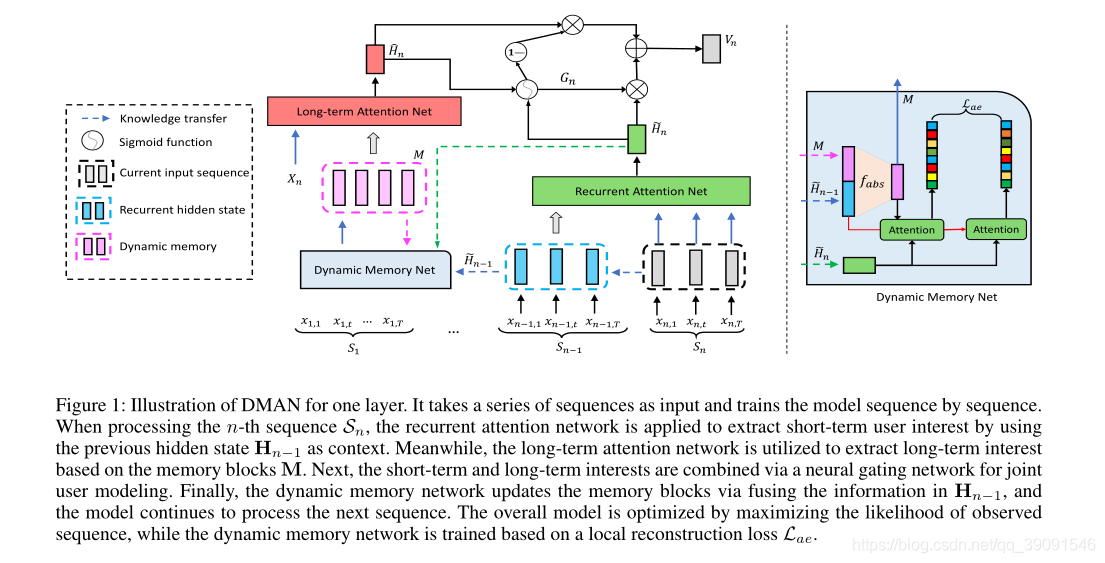
一层的dman插图。它以一系列序列作为输入,逐个训练模型序列。在处理随后的序列Sn时,应用递归注意力网络,以先前的隐含状态Hn−1为上下文,提取用户的短期兴趣。同时,利用长期关注网络提取基于记忆块M的长期兴趣。然后,通过神经门控网络将短期兴趣和长期兴趣结合起来,进行联合用户建模。最后,动态存储网络通过融合Hn−1中的信息来更新存储块,模型继续处理下一序列。通过最大化观测序列的似然度来优化整体模型,而动态记忆网络则基于局部重构损失来训练。
Neural Gating Network
获得短期和长期兴趣嵌入之后,下一个目标是将它们结合起来以进行综合建模。 考虑到用户的未来意图可能会受到早期行为的影响,而短期和长期利益可能会随着时间的流逝而对下一项目的预测产生不同的影响(Ma et al.2019),我们应用神经门控网络自适应地控制 这两个兴趣嵌入。
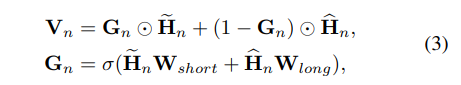
Dynamic Memory Network
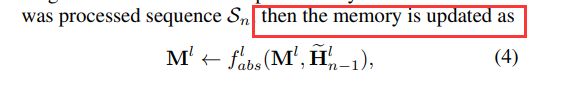
担心会丢失与目标项目不同的其他记忆丢失。所以设计一个损失函数

这个地方对于这两个损失函数的部分没有很清楚

尽可能多的提取主要的主要意图

这个是定义两个变量:primary capsules 和 interest capsules,对他俩的相关性进行计算
这里介绍的是公式4中的F
实验部分主要说的是自注意力的重要性