算法原理
Mean shift 算法是基于核密度估计的爬山算法,可用于聚类、图像分割等。
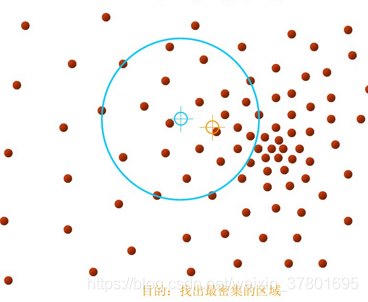
样本点集:上图中的实心点,n个样本点yi,i=1,2,…,n
区域圆心:蓝色空心圆x
感兴趣区域Sh:蓝色圆形区域,以x为圆心,h为半径的圆形内部。表达式为
Mean Shift向量:从蓝色空心圆到黄色空心圆的偏移向量,表达式为
三维高斯核概率密度分布如下图所示
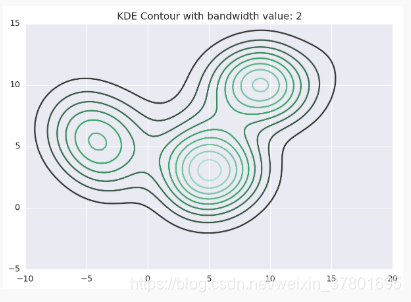
高斯核密度分布等高线图如下图所示
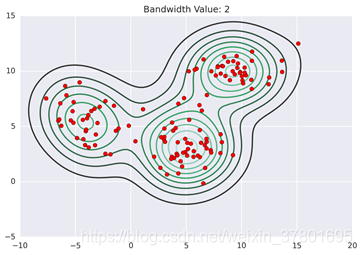
Mean Shift聚类的过程相当于爬山的过程,所有点都爬向最近的山顶,即等高线的中心,如下图所示
聚类中心的更新沿着概率密度梯度方向,更新后的中心位置为
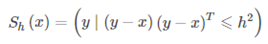
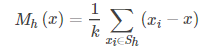

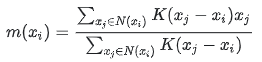
算法的优缺点
优点:
不需要给出类别个数,类别个数取决于数据分布
带宽的选择可以基于领域知识
缺点:
方法复杂度较高,O(N^2),不适合大规模数据集
写博客的目的是学习的总结和知识的共享,如有侵权,请与我联系,我将尽快处理
参考链接如下
https://blog.csdn.net/hjimce/article/details/45718593
https://spin.atomicobject.com/2015/05/26/mean-shift-clustering/
https://blog.csdn.net/liangzuojiayi/article/details/78152180
https://blog.csdn.net/unixtch/article/details/78556499