Mean Shift 算法通过更新质心的候选位置为 所选定区域 的偏移均值。 然后,这些候选者在后处理阶段被过滤以消除近似重复,从而形成最终质心集合。
算法流程
1、在指定的区域内计算偏移均值(如下图的黄色的圈);
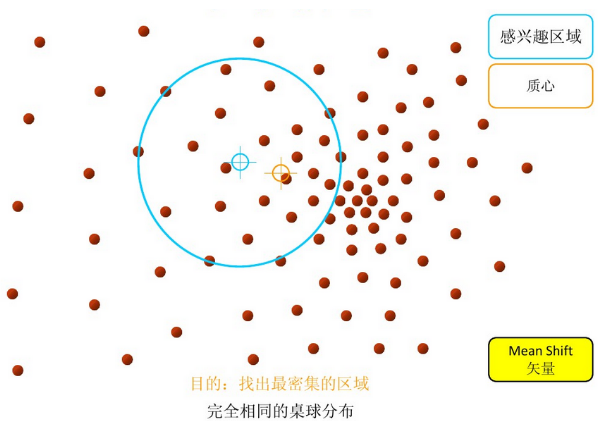
2、移动该点到偏移均值点处;
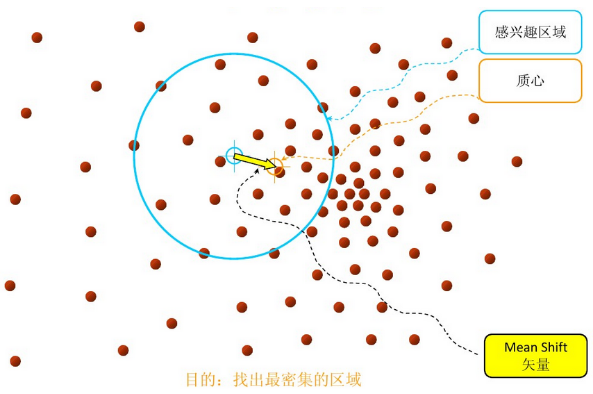
重复上述的过程(计算新的偏移均值,移动),直到满足了最终的条件,退出;
均值偏移向量
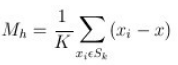
其中,
为上面图中的蓝色大圆,K 为蓝色大圆中包含的所有点的个数,计算出来的均值偏移向量即为上面第二个图中的黄色箭头;
上面的均值偏移向量是最简单的形式,还有许多改进过的均值偏移向量(引入了核函数等等);
sklearn中的参数
[class sklearn.cluster.MeanShift]
bandwidth=None: float,高斯核函数的带宽,如果没有给定,则使用sklearn.cluster.estimate_bandwidth 自动估计带宽;
seeds=None: array, shape=[n_samples, n_features],我理解的 seeds 是初始化的质心,如果为 None 并且 bin_seeding=True,就用 clustering.get_bin_seeds 计算得到;
bin_seeding=False: boolean,在没有设置 seeds 时起作用,如果 bin_seeding=True,就用 clustering.get_bin_seeds 计算得到质心,如果 bin_seeding=False,则设置所有点为质心;
min_bin_freq=1: int,clustering.get_bin_seeds 的参数,设置的最少质心个数;
以上三个参数要结合起来理解;
cluster_all=True: boolean,如果为 True,所有的点都会被聚类,包括不在任何核内的孤立点,其会选择一个离自己最近的核;如果为 False,孤立点的类标签为 -1;
n_jobs=1: int,多线程;
-1:使用所有的cpu;
1:不使用多线程;
-2:如果 n_jobs<0,(n_cpus + 1 + n_jobs)个cpu被使用,所以 n_jobs=-2 时,所有的cpu中只有一块不被使用;
示例代码
A demo of the mean-shift clustering algorithm
print(__doc__)
import numpy as np
from sklearn.cluster import MeanShift, estimate_bandwidth
from sklearn.datasets.samples_generator import make_blobs
# #############################################################################
# Generate sample data
centers = [[1, 1], [-1, -1], [1, -1]]
X, _ = make_blobs(n_samples=10000, centers=centers, cluster_std=0.6)
# #############################################################################
# Compute clustering with MeanShift
# The following bandwidth can be automatically detected using
bandwidth = estimate_bandwidth(X, quantile=0.2, n_samples=500)
ms = MeanShift(bandwidth=bandwidth, bin_seeding=True)
ms.fit(X)
labels = ms.labels_
cluster_centers = ms.cluster_centers_
labels_unique = np.unique(labels)
n_clusters_ = len(labels_unique)
print("number of estimated clusters : %d" % n_clusters_)
# #############################################################################
# Plot result
import matplotlib.pyplot as plt
from itertools import cycle
plt.figure(1)
plt.clf()
colors = cycle('bgrcmykbgrcmykbgrcmykbgrcmyk')
for k, col in zip(range(n_clusters_), colors):
my_members = labels == k
cluster_center = cluster_centers[k]
plt.plot(X[my_members, 0], X[my_members, 1], col + '.')
plt.plot(cluster_center[0], cluster_center[1], 'o', markerfacecolor=col,
markeredgecolor='k', markersize=14)
plt.title('Estimated number of clusters: %d' % n_clusters_)
plt.show()