主成分分析(PCA,Principal Component Analysis)
1、理论
1)概要
PCA(主成分分析)是机器学习中一种数据降维算法,具体地为一个样本的特征通常用一个n维向量表示,PCA通过对数据进行正交线性变换将其映射到一个新的空间中且维度不变,经过变换后任意两个维度线性无关,且在第一维方差最大,第二维次之,以此类推最后一维方差最小。最后根据一定的标准取前面k维达到降维的目的。
PCA算法最后的目标是对高维数据进行降维,但是在前面的正交线性变换则实现了对数据的去噪,使得数据中隐含的模式更加清晰的凸显出来,便于后续基于特征的机器学习算法的学习收敛。
2)推导
详细的理论推导可以参见知乎:https://zhuanlan.zhihu.com/p/21580949,循序渐进写的非常仔细
2、算法
假设样本集中,有m个样本,每个样本特征维数为n。
1)将所有样本的特征列向量组合起来构成一个n行m列的样本集特征矩阵X。
2)将X的每一行进行零均值化,即减去这一行的均值,具体地为求所有样本在这一维的特征的平均值,然后这一行所有值减去该均值。
3)求X的协方差矩阵
![]()
4)求出协方差矩阵的特征值及对应的特征向量
扫描二维码关注公众号,回复:
4415503 查看本文章

5) 将特征值按降序排序,同时特征向量对应的特征向量也对应排列,然后取取前k行组成矩阵P(注意这里的特征向量经过转置再排列)
6)Y=PX即为降维到k维后的数据
3、python实现
#-*- coding:utf-8-*-
from numpy import *
import numpy as np
import os
import matplotlib.pyplot as plt
#机器学习实战读取数据
def loadDataSet(filename,delim = "\t"):
fr = open(filename)
stringArr = [line.strip().split(delim) for line in fr.readlines()]
datArr = [map(float, line) for line in stringArr]
return np.mat(datArr)
#PCA实现函数
def PCA(dataMat,k):
newData,meanVals=zeroMean(dataMat)
covMat=np.cov(newData,rowvar=0)
eigVals,eigVects=np.linalg.eig(np.mat(covMat))
eigValIndice=np.argsort(eigVals)
n_eigValIndice=eigValIndice[-1:-(k+1):-1]
n_eigVect=eigVects[:,n_eigValIndice]
lowDataMat=newData*n_eigVect
reconMat=(lowDataMat*n_eigVect.T)+meanVals
return lowDataMat,reconMat
data=loadDataSet("./testSet.txt")
lowdataMat,reconMat=PCA(data,2)
fig1 = plt.figure()
fig2=plt.figure()
ax = fig1.add_subplot(111)
ay=fig2.add_subplot(111)
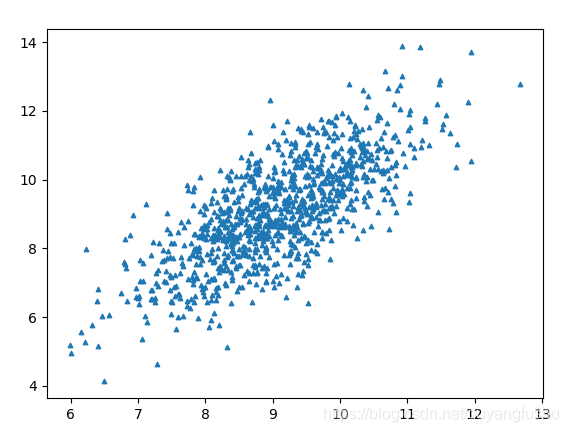
ax.scatter(data[:,0].flatten().A[0], data[:,1].flatten().A[0], marker='^', s = 10 )
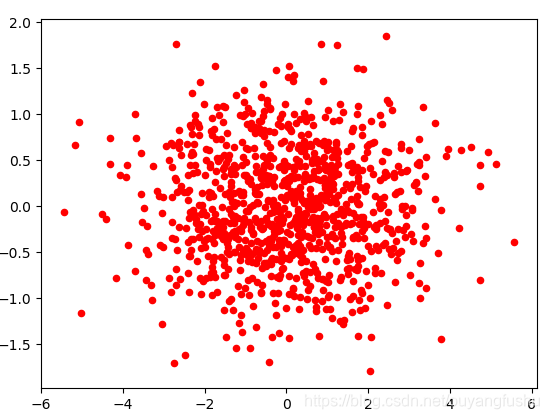
ay.scatter(lowdataMat[:,0].flatten().A[0], lowdataMat[:,1].flatten().A[0],marker='o', s = 20 , c ='red' )
plt.show()