主成分分析及其现代解释
4. 主成分分析及其现代解释 Principal Component Analysis and Its Modern Interpretations
无监督的学习方法
输入变量是 X ∈ R n X\in \mathbb{R}^{n} X∈Rn,输出变量是还原变量 S ∈ R k S\in \mathbb{R}^{k} S∈Rk。 S S S是通过某种映射 f f f从 X X X中计算出来的,该映射使特定的损失函数 L ( f ( X ) ) L(f(X)) L(f(X))最小。无监督学习中的损失函数旨在减少 “输入变量的分布量”。这意味着 f ( X ) f(X) f(X)的样本集中在一个比 X X X的样本小得多的体积中。在许多情况下,这是通过做无监督的降维来实现的,即通过选择小于 n n n的 k k k。另外,聚类,即 S S S由有限多的聚类中心组成,减少了输入分布的体积。
在所有无监督降维技术中,主成分分析(PCA)是最著名的一种。我们所说的无监督学习方法,是指在我们采用学习算法之前,数据不需要被标记(由监督者)。
PCA的成功是由于它的简单性和在许多现实世界数据分析任务中的广泛适用性。这可能是它有许多别名的原因,即离散的Karhunen-Loéve变换,Hotelling变换或适当的正交分解。它的核心假设是原始数据的分布集中在某个低维平面上,或者说,数据中的大部分方差可以通过其在这个平面上的投影方差来描述。
4.1 几何学解释
PCA的几何解释是,它通过将居中的数据投射到一个较低维度的子空间来降低维度,并用该子空间的适当的基来描述它。图4.1说明了这种解释。
我们可以将这一任务形式化如下。令 k < p k<p k<p(通常是 k ≪ p k\ll p k≪p)和 X = [ x 1 , … , x n ] ∈ \mathbf{X}=\left[\mathbf{x}_{1}, \ldots, \mathbf{x}_{n}\right] \in X=[x1,…,xn]∈ R p × n \mathbb{R}^{p \times n} Rp×n是居中的观察矩阵。回顾一下,居中的意思是 ∑ i x i = 0 \sum_{i} \mathbf{x}_{i}=0 ∑ixi=0。正交的 1 { }^{1} 1投影 π U : R p → R p \pi_{\mathcal{U}}: \mathbb{R}^{p} \rightarrow \mathbb{R}^{p} πU:Rp→Rp到 k k k维的子空间 U ⊂ R p \mathcal{U} \subset \mathbb{R}^{p} U⊂Rp。可以借助 U \mathcal{U} U的正交基来描述 R p \mathbb{R}^{p} Rp的子集。更确切地说,如果我们用矩阵 U k ∈ R p × k \mathbf{U}_{k} \in \mathbb{R}^{p \times k} Uk∈Rp×k来表示这个基(即具有正交列 U k ⊤ U k = I k \mathbf{U}_{k}^{\top} \mathbf{U}_{k}=\mathbf{I}_{k} Uk⊤Uk=Ik )的投影由以下公式给出
π U ( x ) = U k U k ⊤ x (4.1) \pi_{\mathcal{U}}(\mathbf{x})=\mathbf{U}_{k} \mathbf{U}_{k}^{\top} \mathbf{x}\tag{4.1} πU(x)=UkUk⊤x(4.1)
1 { }^{1} 1 如果不做过多说明,正交总是关于标准标量的乘积。

图 4.1: PCA的几何解释:找到一个 k k k维的子空间,以捕捉数据的大部分方差。第一个 P C \mathrm{PC} PC显示为红色,而第二个则显示为绿色。

因此,我们可以将任务表述为:找到一个矩阵 U k ∈ R p × k \mathbf{U}_{k} \in \mathbb{R}^{p \times k} Uk∈Rp×k,该矩阵具有标准正交的列,能使投影误差平方之和最小。
J ( U k ) = ∑ i = 1 n ∥ x i − U k U k ⊤ x i ∥ 2 2 (4.2) J\left(\mathbf{U}_{k}\right)=\sum_{i=1}^{n}\left\|\mathbf{x}_{i}-\mathbf{U}_{k} \mathbf{U}_{k}^{\top} \mathbf{x}_{i}\right\|_{2}^{2}\tag{4.2} J(Uk)=i=1∑n∥∥xi−UkUk⊤xi∥∥22(4.2)
根据下面的声明,这样的矩阵很容易找到 2 { }^{2} 2。
2 { }^{2} 2 我们之所以可以说这个矩阵很容易被找到,是因为在过去的几十年里,研究人员已经开发了高效可靠的算法来计算矩阵的奇异值分解。这并不意味着在一般情况下,这样的矩阵可以用手计算。
Theorem 4.1
令中心观测矩阵 X \mathbf{X} X的奇异值分解为
X = U D V ⊤ (4.3) \mathbf{X}=\mathbf{U D V}^{\top} \tag{4.3} X=UDV⊤(4.3)
有奇异值 d 1 ≥ ⋯ ≥ d n ≥ 0 d_{1} \geq \cdots \geq d_{n} \geq 0 d1≥⋯≥dn≥0。如果我们用 U k \mathbf{U}_{k} Uk 表示 U \mathbf{U} U的前 k k k列,那么 U k \mathbf{U}_{k} Uk可以最小化(4.2)。此外,减少的 k k k变量的经验协方差矩阵 S : = U k ⊤ X \mathbf{S}:=\mathbf{U}_{k}^{\top} \mathbf{X} S:=Uk⊤X是对角矩阵,也就是说,通过PCA提取的特征是不相关的。
Proof.
首先,令 Q k ∈ R p × k \mathbf{Q}_{k} \in \mathbb{R}^{p \times k} Qk∈Rp×k 有 Q k ⊤ Q k = I k \mathbf{Q}_{k}^{\top} \mathbf{Q}_{k}=\mathbf{I}_{k} Qk⊤Qk=Ik。需要注意的是,从 ∥ x i − Q k Q k ⊤ x i ∥ 2 2 = \left\|\mathbf{x}_{i}-\mathbf{Q}_{k} \mathbf{Q}_{k}^{\top} \mathbf{x}_{i}\right\|_{2}^{2}= ∥∥xi−QkQk⊤xi∥∥22= ∥ x i ∥ 2 2 − x i ⊤ Q k Q k ⊤ x i \left\|\mathbf{x}_{i}\right\|_{2}^{2}-\mathbf{x}_{i}^{\top} \mathbf{Q}_{k} \mathbf{Q}_{k}^{\top} \mathbf{x}_{i} ∥xi∥22−xi⊤QkQk⊤xi开始,最小化 J J J等价于 ∑ i x i ⊤ Q k Q k ⊤ x i \sum_{i} \mathbf{x}_{i}^{\top} \mathbf{Q}_{k} \mathbf{Q}_{k}^{\top} \mathbf{x}_{i} ∑ixi⊤QkQk⊤xi。然后我们有
∑ i = 1 n x i ⊤ Q k Q k ⊤ x i = tr ( Q k ⊤ X X ⊤ Q k ) = tr ( Q k ⊤ U D D ⊤ U ⊤ Q k ) = tr ( U ⊤ Q k Q k ⊤ U ⊤ [ d 1 2 ⋱ d n 2 ] ) \begin{aligned} \sum_{i=1}^{n} \mathbf{x}_{i}^{\top} \mathbf{Q}_{k} \mathbf{Q}_{k}^{\top} \mathbf{x}_{i} &=\operatorname{tr}\left(\mathbf{Q}_{k}^{\top} \mathbf{X} \mathbf{X}^{\top} \mathbf{Q}_{k}\right) \\ &=\operatorname{tr}\left(\mathbf{Q}_{k}^{\top} \mathbf{U D D}^{\top} \mathbf{U}^{\top} \mathbf{Q}_{k}\right) \\ &=\operatorname{tr}\left(\mathbf{U}^{\top} \mathbf{Q}_{k} \mathbf{Q}_{k}^{\top} \mathbf{U}^{\top}\left[\begin{array}{ccc} d_{1}^{2} & & \\ & \ddots & \\ & & d_{n}^{2} \end{array}\right]\right) \end{aligned} i=1∑nxi⊤QkQk⊤xi=tr(Qk⊤XX⊤Qk)=tr(Qk⊤UDD⊤U⊤Qk)=tr⎝⎛U⊤QkQk⊤U⊤⎣⎡d12⋱dn2⎦⎤⎠⎞
n × n n \times n n×n 矩阵 U ⊤ Q k Q k ⊤ U \mathbf{U}^{\top} \mathbf{Q}_{k} \mathbf{Q}_{k}^{\top} \mathbf{U} U⊤QkQk⊤U是一个秩为 k k k的投影矩阵,因此它的对角线项都在0和1之间。为了说明这一点,让 P \mathbf{P} P是一个正交投影矩阵。它的第 i i i个对角线条目是 e i ⊤ P e i \mathbf{e}_{i}^{\top} \mathbf{P e}_{i} ei⊤Pei,其中 e i \mathbf{e}_{i} ei是第 i i i个标准基向量。由于 P \mathbf{P} P是一个正交的投影矩阵,我们有
e i ⊤ P e i = e i ⊤ P 2 e i = ∥ P e i ∥ 2 . (4.4) \mathbf{e}_{i}^{\top} \mathbf{P e}_{i}=\mathbf{e}_{i}^{\top} \mathbf{P}^{2} \mathbf{e}_{i}=\left\|\mathbf{P e}_{i}\right\|^{2} . \tag{4.4} ei⊤Pei=ei⊤P2ei=∥Pei∥2.(4.4)
由于 P \mathbf{P} P 是正交投影, ( I − P ) (\mathbf{I}-\mathbf{P}) (I−P)是对正交补数的投影, R n \mathbb{R}^{n} Rn中的每个向量都可以写成投影空间中元素的唯一组合。特别是对于标准基向量来说,这一点是正确的,即
1 = ∥ e i ∥ 2 = ∥ P e i + ( I − P ) e i ∥ 2 = ∥ P e i ∥ 2 + ∥ ( I − P ) e i ∥ 2 + 2 ⟨ P e i , ( I − P ) e i ⟩ = ∥ P e i ∥ 2 + ∥ ( I − P ) e i ∥ 2 . (4.5) \begin{aligned} 1 &=\left\|\mathbf{e}_{i}\right\|^{2}=\left\|\mathbf{P e}_{i}+(\mathbf{I}-\mathbf{P}) \mathbf{e}_{i}\right\|^{2} \\ &=\left\|\mathbf{P e}_{i}\right\|^{2}+\left\|(\mathbf{I}-\mathbf{P}) \mathbf{e}_{i}\right\|^{2}+2\left\langle\mathbf{P e}_{i},(\mathbf{I}-\mathbf{P}) \mathbf{e}_{i}\right\rangle \\ &=\left\|\mathbf{P e}_{i}\right\|^{2}+\left\|(\mathbf{I}-\mathbf{P}) \mathbf{e}_{i}\right\|^{2} . \end{aligned} \tag{4.5} 1=∥ei∥2=∥Pei+(I−P)ei∥2=∥Pei∥2+∥(I−P)ei∥2+2⟨Pei,(I−P)ei⟩=∥Pei∥2+∥(I−P)ei∥2.(4.5)
由于 P e i \mathrm{Pe}_{i} Pei和 ( I − P ) e i (\mathbf{I}-\mathbf{P}) \mathrm{e}_{i} (I−P)ei是相互正交的,所以最后一个等式成立。 两个被加数 ∥ P e i ∥ 2 \left\|\mathbf{P e}_{i}\right\|^{2} ∥Pei∥2和 ∥ ( I − P ) e i ∥ 2 \left\|(\mathbf{I}-\mathbf{P}) \mathbf{e}_{i}\right\|^{2} ∥(I−P)ei∥2 都是正数,加起来为1。因此, ∥ P e i ∥ 2 \left\|\mathbf{P e}_{i}\right\|^{2} ∥Pei∥2 对于所有 i i i都位于 [ 0 , 1 ] [0,1] [0,1]区间内。此外, P \mathbf{P} P的迹,即所有对角线元素之和等于 k k k。因此,我们能达到的最大值是设置 Q k = U k \mathbf{Q}_{k}=\mathbf{U}_{k} Qk=Uk,因为此时这个投影是 U ⊤ U k U k ⊤ U = [ I k 0 0 0 ] \mathbf{U}^{\top} \mathbf{U}_{k} \mathbf{U}_{k}^{\top} \mathbf{U}=\left[\begin{array}{cc}\mathbf{I}_{k} & 0 \\ 0 & 0\end{array}\right] U⊤UkUk⊤U=[Ik000]。
要看到还原的变量 S : = U k ⊤ X \mathbf{S}:=\mathbf{U}_{k}^{\top} \mathbf{X} S:=Uk⊤X是不相关的,首先注意到由于 X \mathbf{X} X是居中的,所以 S \mathbf{S} S也是居中的,因此它的经验协方差矩阵为
cov ( S ) : = 1 n S S ⊤ = 1 n U k ⊤ X X ⊤ U k = 1 n [ d 1 2 ⋱ d k 2 ] (4.6) \operatorname{cov}(\mathbf{S}):=\frac{1}{n} \mathbf{S S}^{\top}=\frac{1}{n} \mathbf{U}_{k}^{\top} \mathbf{X X}^{\top} \mathbf{U}_{k}=\frac{1}{n}\left[\begin{array}{lll} d_{1}^{2} & & \\ & \ddots & \\ & & d_{k}^{2} \end{array}\right] \tag{4.6} cov(S):=n1SS⊤=n1Uk⊤XX⊤Uk=n1⎣⎡d12⋱dk2⎦⎤(4.6)
矩阵 S \mathbf{S} S的 ( i , j ) (i, j) (i,j)的条目称为第 i i i主成分(principal component) 的第 j j j得分,完整的矩阵被称为得分矩阵(score matrix) 。矩阵 U \mathbf{U} U也常被称为加载矩阵(loadings matrix)。 3 { }^{3} 3。
3 { }^{3} 3 加载矩阵的定义在文献中并不一致。有时,矩阵 L : = U D \mathbf{L}:=\mathbf{U D} L:=UD被称为loading matrix, U \mathbf{U} U被表示为主轴/方向的矩阵。
注意, S \mathbf{S} S可以直接通过 X \mathbf{X} X的SVD得到,因为
S = U k ⊤ U D V ⊤ = [ d 1 ⋱ d k ] V k ⊤ = D k V k ⊤ , (4.7) \mathbf{S}=\mathbf{U}_{k}^{\top} \mathbf{U D V}^{\top}=\left[\begin{array}{ccc} d_{1} & & \\ & \ddots & \\ & & d_{k} \end{array}\right] \mathbf{V}_{k}^{\top}=\mathbf{D}_{k} \mathbf{V}_{k}^{\top}, \tag{4.7} S=Uk⊤UDV⊤=⎣⎡d1⋱dk⎦⎤Vk⊤=DkVk⊤,(4.7)
其中 V k \mathbf{V}_{k} Vk代表 V \mathbf{V} V的前 k k k列。
虽然减少的变量可以通过 U k ⊤ X \mathbf{U}_{k}^{\top} \mathbf{X} Uk⊤X来计算,但在实际应用中这是不可行的,因为 U k \mathbf{U}_{k} Uk和 X \mathbf{X} X都是密集的(计算S需要 ( 2 p − 1 ) n k (2 p-1) n k (2p−1)nk次运算)。使用 D k V k ⊤ \mathbf{D}_{k} \mathbf{V}_{k}^{\top} DkVk⊤会容易很多, 因为 D k \mathbf{D}_{k} Dk是对角矩阵,而 V k ⊤ \mathbf{V}_{k}^{\top} Vk⊤只有 k k k行(计算 S \mathbf{S} S需要 n k n k nk次运算。(注, n n n为采样个数, k k k为投影后的子空间维度, p p p为原始空间维度)
4.2 统计学解释
除了最小化重建误差 J ( U k ) J\left(\mathbf{U}_{k}\right) J(Uk),如(4.2)所定义,PCA可以从统计学的角度来解释。如果 X ∈ R p X\in \mathbb{R}^{p} X∈Rp表示一个多维随机变量,PCA寻求一个正交变换到一个新的坐标系,即
Y = U ⊤ X (4.8) Y=\mathbf{U}^{\top} X \tag{4.8} Y=U⊤X(4.8)
与 U ⊤ U = I p \mathbf{U}^{\top} \mathbf{U}=I_{p} U⊤U=Ip,这样 Y Y Y的协方差矩阵是对角线的,而且各部分的方差都会减少,即 var ( Y 1 ) ≥ ⋯ ≥ var ( Y p ) \operatorname{var}\left(Y_{1}\right) \geq \cdots \geq \operatorname{var}\left(Y_{p}\right) var(Y1)≥⋯≥var(Yp)。
由于协方差矩阵 var ( X ) = E [ ( X − μ ) ( X − μ ) ⊤ ] \operatorname{var}(X)=\mathbb{E}\left[(X-\mu)(X-\mu)^{\top}\right] var(X)=E[(X−μ)(X−μ)⊤],其中 μ = E [ X ] \mu=\mathbb{E}[X] μ=E[X],是对称的正半自由度,它可以被对角化并由一个正交矩阵U排序。
D = U ⊤ var ( X ) U = E [ U ⊤ ( X − μ ) ( X − μ ) ⊤ U ] = E [ ( U ⊤ X − U ⊤ μ ) ( U ⊤ X − U ⊤ μ ) ⊤ ] = var ( Y ) (4.9) \begin{aligned} \mathbf{D} &=\mathbf{U}^{\top} \operatorname{var}(X) \mathbf{U}=\mathbb{E}\left[\mathbf{U}^{\top}(X-\mu)(X-\mu)^{\top} \mathbf{U}\right] \\ &=\mathbb{E}\left[\left(\mathbf{U}^{\top} X-\mathbf{U}^{\top} \mu\right)\left(\mathbf{U}^{\top} X-\mathbf{U}^{\top} \mu\right)^{\top}\right]=\operatorname{var}(Y) \end{aligned} \tag{4.9} D=U⊤var(X)U=E[U⊤(X−μ)(X−μ)⊤U]=E[(U⊤X−U⊤μ)(U⊤X−U⊤μ)⊤]=var(Y)(4.9)
是具有递减的正项的对角线项。如果我们考虑经验协方差矩阵,那么 U \mathbf{U} U由居中观测矩阵的SVD给出,作为 左奇异向量,参见(4.3)。
4.3 误差模型解释 (Error Model Interpretation)
把观察到的数据 X \mathbf{X} X看作是位于某个 k k k维子空间的一些干净数据 L \mathbf{L} L和一些额外的噪声 N \mathbf{N} N的叠加,即
X = L + N (4.10) \mathbf{X}=\mathbf{L}+\mathbf{N} \tag{4.10} X=L+N(4.10)
从形式上看,要求 L \mathbf{L} L的数据位于某个 k k k维的子空间中,相当于要求 L \mathbf{L} L的等级低于或等于 k k k。我们将在下文中看到,看待PCA的另一种方式是我们要恢复 L \mathbf{L} L,在噪声 N \mathbf{N} N(从各个项来看)是各自独立的高斯分布的情况下。其中噪声矩阵 N \mathbf{N} N的每个条目是根据均值为0、方差为1的高斯分布独立抽取的。在这种模型假设下,给定观测值 X \mathbf{X} X的最大似然估计 L \mathbf{L} L为,
L ^ = arg min rank L ≤ k ∥ X − L ∥ F . (4.11) \hat{\mathbf{L}}=\arg \min _{\text {rank } \mathbf{L} \leq k}\|\mathbf{X}-\mathbf{L}\|_{F} \text {. } \tag{4.11} L^=argrank L≤kmin∥X−L∥F. (4.11)
经典的PCA提供了这个问题的解决方案。
Theorem 4.2.
设 X = U D V ⊤ \mathbf{X}=\mathbf{U D V}^{\top} X=UDV⊤为观察矩阵 X \mathbf{X} X的奇异值分解,奇异值为 d 1 ≥ ⋯ ≥ d p ≥ 0 d_{1}\geq \cdots \geq d_{p} \geq 0 d1≥⋯≥dp≥0。如果我们用 U k \mathbf{U}_{k} Uk表示 U \mathbf{U} U的前 k k k列,用 V k \mathbf{V}_{k} Vk表示 V \mathbf{V} V的前 k k k列,那么 L ^ = U k diag ( d 1 , … , d k ) V k ⊤ \hat{\mathbf{L}}=\mathbf{U}_{k} \operatorname{diag}\left(d_{1}, \ldots, d_{k}\right) \mathbf{V}_{k}^{\top} L^=Ukdiag(d1,…,dk)Vk⊤ 最小化(4.11)。
Proof.
让 L \mathbf{L} L是(4.11)的最小化。请注意,矩阵 L \mathbf{L} L的秩低于或等于 k k k,当且仅当其列 l i \mathbf{l}_{i} li位于 k k k维的子空间中,例如 L \mathcal{L} L。现在每一列 I i \mathbf{I}_{i} Ii必须是 x i \mathbf{x}_{i} xi对 L \mathcal{L} L的投影,否则,我们可以在不增加 ∣ X − L ∥ F 2 = ∑ i ∣ x i − 1 i ∥ 2 |\mathbf{X}-\mathbf{L}\|_{F}^{2}=\sum_{i}\left|\mathbf{x}_{i}-1_{i}\right\|^{2} ∣X−L∥F2=∑i∣xi−1i∥2的情况下取代 L \mathbf{L} L矩阵的第 i i i列。因此
min r k L ≤ k ∥ X − L ∥ F 2 = min dim ( L ) = k ∑ i ∥ x i − π L ( x i ) ∥ 2 , (4.12) \min _{\mathrm{rkL} \leq k}\|\mathbf{X}-\mathbf{L}\|_{F}^{2}=\min _{\operatorname{dim}(\mathcal{L})=k} \sum_{i}\left\|\mathbf{x}_{i}-\pi_{\mathcal{L}}\left(\mathbf{x}_{i}\right)\right\|^{2}, \tag{4.12} rkL≤kmin∥X−L∥F2=dim(L)=kmini∑∥xi−πL(xi)∥2,(4.12)
从定理4.1可以看出, L \mathcal{L} L由 X \mathbf{X} X的前 k k k奇异向量 U k \mathbf{U}_{k} Uk所张成,因此最佳 k k k-秩近似值为
L ^ = U k U k ⊤ X = U k diag ( d 1 , … , d k ) V k ⊤ (4.13) \hat{\mathbf{L}}=\mathbf{U}_{k} \mathbf{U}_{k}^{\top} \mathbf{X}=\mathbf{U}_{k} \operatorname{diag}\left(d_{1}, \ldots, d_{k}\right) \mathbf{V}_{k}^{\top} \tag{4.13} L^=UkUk⊤X=Ukdiag(d1,…,dk)Vk⊤(4.13)
4.4 Relation to Autoencoders
PCA与一种特别简单的神经网络形式密切相关,即所谓的自动编码器。自动编码器的目的是在输入通过一个低维空间后尽可能好地重建输入,或者更正式地说。 p p p维随机变量的实现 x 1 , … , x n x_{1}, \ldots, x_{n} x1,…,xn首先通过函数 f f f被映射到低维空间 R k \mathbb{R}^{k} Rk,然后这些图像再次被映射到 R p \mathbb{R}^{p} Rp,试图最适合原始输入。
g ∘ f ( x i ) ≈ x i . (4.14) g \circ f\left(\mathbf{x}_{i}\right) \approx \mathbf{x}_{i} . \tag{4.14} g∘f(xi)≈xi.(4.14)
自动编码器试图为这项工作找到最佳的一对函数 ( f , g ) (f, g) (f,g),其想法是,有趣信息的合理部分包含在减少的数据 f ( x i ) f\left(\mathbf{x}_{i}\right) f(xi)中。现在让我们假设 f f f和 g g g是线性的,由矩阵 V ∈ R k × p \mathbf{V} \in \mathbb{R}^{k \times p} V∈Rk×p 与 W ∈ R p × k \mathbf{W} \in \mathbb{R}^{p \times k} W∈Rp×k 。那么 g ∘ f ( x i ) = W V x i g \circ f\left(\mathbf{x}_{i}\right)=\mathbf{W} \mathbf{V} \mathbf{x}_{i} g∘f(xi)=WVxi,如果我们通过平方距离之和来测量重建误差,即
J ( W , V ) = ∑ i = 1 n ∥ x i − W V x i ∥ 2 (4.15) J(\mathbf{W}, \mathbf{V})=\sum_{i=1}^{n}\left\|\mathbf{x}_{i}-\mathbf{W} \mathbf{V} \mathbf{x}_{i}\right\|^{2} \tag{4.15} J(W,V)=i=1∑n∥xi−WVxi∥2(4.15)
我们可以证明,最优的 V \mathbf{V} V只是由观察矩阵 X = [ x 1 , … , x n ] \mathbf{X}=\left[\mathbf{x}_{1}, \ldots, \mathbf{x}_{n}\right] X=[x1,…,xn]的前 k k k左奇异向量给出。
Theorem 4.3
设 U k \mathbf{U}_{k} Uk为观察矩阵 X \mathbf{X} X的前 k k k左奇异向量。那么 V = U k ⊤ \mathbf{V}=\mathbf{U}_{k}^{\top} V=Uk⊤和 W = U k \mathbf{W}=\mathbf{U}_{k} W=Uk使线性编码器的重建误差最小(4.15)。
Proof.
由于 V \mathbf{V} V和 W \mathbf{W} W的维数,平方矩阵 W V \mathbf{W} \mathbf{V} WV最多可以有 k k k的秩。所以,所有 W V x i \mathbf{W} \mathbf{V} \mathbf{x}_{i} WVxi位于一个 k k k维的子空间中,因此形成一个最多秩为 k k k的矩阵。我们在定理4.2中看到, L L L的最小值是由 V = U k ⊤ \mathbf{V}=\mathbf{U}_{k}^{\top} V=Uk⊤和 W = U k \mathbf{W}=\mathbf{U}_{k} W=Uk实现。
通过允许非线性函数,这种方法有了有趣的扩展。在实际应用中非常成功的是 f ( x ) : = σ ( V x ) f(\mathbf{x}):=\sigma(\mathbf{V} \mathbf{x}) f(x):=σ(Vx)形式的函数,其中 V \mathbf{V} V是上述情况下的矩阵, σ \sigma σ是一个激活函数,分量操作,对负参数为零,对正参数不做改变。在这种非线性设置中,所产生的优化问题没有封闭式的解决方案,我们需要优化技术,例如梯度下降法,来近似地获得一个最佳解决方案。
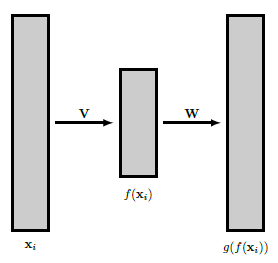
图4.2:一个简单的自动编码器,有 V ∈ R k × p , W ∈ R p × k , k < p \mathbf{V} \in \mathbb{R}^{k \times p}, \mathbf{W} \in \mathbb{R}^{p \times k}, k<p V∈Rk×p,W∈Rp×k,k<p。
4.5 PCA 实例
Task 1.
In this task, we will once again work with the MNIST training set as provided on Moodle. Choose three digit classes, e.g. 1,2 and 3 and load N = 1000 N=1000 N=1000 images from each of the classes to the workspace. Store the data in a floating point matrix X X X of shape ( 784 , 3 ∗ N ) (784,3 * \mathrm{~N}) (784,3∗ N) normalized to the number range [ 0 , 1 ] [0,1] [0,1]. Furthermore, generate a color label matrix C of dimensions ( 3 ∗ N , 3 ) (3 * N, 3) (3∗N,3) . Each row of C assigns an RGB color vector to the respective column of X X X as an indicator of the digit class. Choose [ 0 , 0 , 1 ] , [ 0 , 1 , 0 ] [0, 0,1],[0,1,0] [0,0,1],[0,1,0] and [ 1 , 0 , 0 ] [1,0,0] [1,0,0] for the three digit classes.
a) Compute the row-wise mean mu of X X X and subtract it from each column of X X X . Save the results as X c X_c Xc.
b) Use np. linalg.svd with full_matrices=False to compute the singular value decomposition [ U , S i g m a , V T ] [U , Sigma, VT ] [U,Sigma,VT] of X C X_{C} XC . Make sure the matrices are sorted in descending order with respect to the singular values.
c) Use reshape in order to convert mu and the first three columns of U to (28,28) -matrices. Plot the resulting images. What do you see?
d) Compute the matrix S = n p ⋅ dot ( n p ⋅ diag ( S i g m a ) , V T ) S=n p \cdot \operatorname{dot}(n p \cdot \operatorname{diag}( Sigma ), V T) S=np⋅dot(np⋅diag(Sigma),VT) . Note that this yields the same result as S = n p ⋅ dot ( U ⋅ T , X − C ) S=n p \cdot \operatorname{dot}\left(U \cdot T, X_{-} C\right) S=np⋅dot(U⋅T,X−C) . The S matrix contains the 3 ∗ N 3 *\mathrm{N} 3∗N scores for the principal components 1 to 784 . Create a 2D scatter plot with C as its color parameter in order to plot the scores for the first two principal components of the data.
import numpy as np
import matplotlib.pyplot as plt
import imageio
# define to image paths which to import
data_folder = './mnist/'
N = 1000
X = np.zeros((784, 3 * N))
for n in range(N):
# define the images' path
impath0 = data_folder + 'd1/d1_{}.png'.format(str(n + 1).zfill(4))
impath1 = data_folder + 'd2/d2_{}.png'.format(str(n + 1).zfill(4))
impath2 = data_folder + 'd3/d3_{}.png'.format(str(n + 1).zfill(4))
# import and convert to numpy array
I0 = np.array(imageio.imread(impath0)).astype(np.float64).reshape(784, ) / 255
I1 = np.array(imageio.imread(impath1)).astype(np.float64).reshape(784, ) / 255
I2 = np.array(imageio.imread(impath2)).astype(np.float64).reshape(784, ) / 255
X[:, n] = I0
X[:, n + N] = I1
X[:, n + 2 * N] = I2
C = np.zeros((3 * N, 3))
C[0:N, :] = [0, 0, 1]
C[N:2 * N, :] = [0, 1, 0]
C[2 * N:3 * N, :] = [1, 0, 0]
mu = np.mean(X, axis=1)
X_c = X - np.expand_dims(np.mean(X, axis=1), axis=1) \
\
# singular decomposition
[U, Sigma, VT] = np.linalg.svd(X_c, full_matrices=False)
# the resulting images
plt.figure(1)
plt.subplot(1, 4, 1)
plt.title('mu')
plt.imshow(mu[:, ].reshape(28, 28))
for n in range(3):
plt.subplot(1, 4, n + 2)
plt.title('U[:, {}]'.format(n))
plt.imshow(U[:, n].reshape(28, 28))
plt.show()
# calculate the projection
S = np.dot(np.diag(Sigma), VT) # Using Sigma*V.T is more efficient
idx_new = np.arange(3 * N).reshape(3, N).T.ravel()
plt.figure(2)
# using the first two features to scatter the points,
# the parameters are (feature 1, feature 2, color) of a specific point
plt.scatter(S[0, idx_new], S[1, idx_new], c=C[idx_new])
plt.show()
the outputs are,


Task 2.
In this task, we consider the problem of choosing the number of principal vectors. Assuming that X ∈ R p × N \mathbf{X} \in \mathbb{R}^{p \times N} X∈Rp×N is the centered data matrix and P = U k U k ⊤ \mathbf{P}=\mathbf{U}_{k} \mathbf{U}_{k}^{\top} P=UkUk⊤ is the projector onto the k -dimensional principal subspace, the dimension k k k is chosen such that the fraction of overall energy contained in the projection error does not exceed ϵ \epsilon ϵ , i.e.
∥ X − P X ∥ F 2 ∥ X ∥ F 2 = ∑ i = 1 M ∥ x i − P x i ∥ 2 ∑ i = 1 N ∥ x i ∥ 2 ≤ ϵ \frac{\|\mathbf{X}-\mathbf{P X}\|_{F}^{2}}{\|\mathbf{X}\|_{F}^{2}}=\frac{\sum_{i=1}^{M}\left\|\mathbf{x}_{i}-\mathbf{P} \mathbf{x}_{i}\right\|^{2}}{\sum_{i=1}^{N}\left\|\mathbf{x}_{i}\right\|^{2}} \leq \epsilon ∥X∥F2∥X−PX∥F2=∑i=1N∥xi∥2∑i=1M∥xi−Pxi∥2≤ϵ
where ϵ \epsilon ϵ is usually chosen to be between 0.01 and 0.2 .
The MIT VisTex database consists of a set of 167 RGB texture images of sizes (512,512,3) .
a) After preprocessing the entire image set (converting to normalized grayscale matrices), divide the images into non overlapping tiles of sizes (64,64) and create a centered data matrix X_c of size ( p , N ) (p, N) (p,N) from them, where p=64*64 and N=167 *(512 / 64) *(512 / 64) .
b) Compute the SVD of X_c and make sure the singular values are sorted in descending order.
c) Plot the fraction of signal energy contained in the projection error for the principal subspace dimensions 0 to p. How many principal vectors do you need to retain 80%, 90%, 95 % or 99 % of the original signal energy?
d) Discuss: Can you imagine a scenario, where signal energy is a bad measure of useful information?
import os, glob
import matplotlib.pyplot as plt
import imageio
import numpy as np
def rgb2gray(rgb):
r, g, b = rgb[:,:,0], rgb[:,:,1], rgb[:,:,2]
gray = 0.2989 * r + 0.5870 * g + 0.1140 * b
return gray
if __name__ == '__main__':
# define data directory
data_dir = 'VisTex_512_512'
# change to correct directory
files = glob.glob(data_dir+'/*.ppm')
# define number of files
img_N = len(files)
p = 64 * 64 # tiles size
N = np.uint16(167 * (512/64) * (512/64)) # Number of tiles
X = np.zeros((p, N))
for f in range(img_N):
img = imageio.imread(files[f])
img = rgb2gray(np.array(img)/255.0)
for k in range(0, 8):
for j in range(0, 8):
x_tmp = img[k*64:(k+1)*64, j*64:(j+1)*64].ravel()
X[:, np.uint16(f*(512/64)**2 + k*8 + j)] = x_tmp
# a) centered data matrix
mu = np.mean(X, axis=1)
X_c = X - np.expand_dims(mu, 1)
# b) the SVD of X_c
[U, Sigma, VT] = np.linalg.svd(X_c, full_matrices=False) # full_matrices?
[U_x, Sigma_x, VT_x] = np.linalg.svd(X, full_matrices=False)
# c) the preserved energy
'''
Remark : Sigma can be described the values which contains the energy of each subspace.
If we accumulate all sigma, then we can get the whole energy of the original matrix.
'''
p_steps = np.arange(p+1)
proj_error = np.array([(1.0 - np.sum(Sigma[:i]**2)/np.sum(Sigma**2))*100.0 for i in p_steps])
plt.plot(p_steps, proj_error)
plt.xlabel('Dimension'); plt.ylabel('Projection Error (%)')
plt.show()
print('Required dimension of subspace for Preservation of 80% of the energy:', np.sum(np.uint16(proj_error>=20))+1)
print('Required dimension of subspace for Preservation of 90% of the energy:', np.sum(np.uint16(proj_error>=10))+1)
print('Required dimension of subspace for Preservation of 95% of the energy:', np.sum(np.uint16(proj_error>=5))+1)
print('Required dimension of subspace for Preservation of 99% of the energy:', np.sum(np.uint16(proj_error>=1))+1)
proj_error_x = np.array([(1.0-np.sum(Sigma_x[:i]**2)/np.sum(Sigma_x**2))*100.0 for i in p_steps])
plt.plot(p_steps, proj_error_x)
plt.xlabel('Dimension'); plt.ylabel('Projection Error (%)')
plt.show()
print('Required dimension of subspace for Preservation of 80% of the energy:', np.sum(np.uint16(proj_error_x>=20))+1)
print('Required dimension of subspace for Preservation of 90% of the energy:', np.sum(np.uint16(proj_error_x>=10))+1)
print('Required dimension of subspace for Preservation of 95% of the energy:', np.sum(np.uint16(proj_error_x>=5))+1)
print('Required dimension of subspace for Preservation of 99% of the energy:', np.sum(np.uint16(proj_error_x>=1))+1)
Using the centered observation matrix:
Required dimension of subspace for Preservation of 80% of the energy: 98
Required dimension of subspace for Preservation of 90% of the energy: 335
Required dimension of subspace for Preservation of 95% of the energy: 694
Required dimension of subspace for Preservation of 99% of the energy: 1651
Without the centered observation matrix:
Required dimension of subspace for Preservation of 80% of the energy: 2
Required dimension of subspace for Preservation of 90% of the energy: 17
Required dimension of subspace for Preservation of 95% of the energy: 121
Required dimension of subspace for Preservation of 99% of the energy: 877
the outputs are,


d)
A typical situation that arises with machine learning on natural images is that lighting conditions vary heavily. Often, the overall brightness of a picture does not add any discriminative value to it. For instance, a face recognition system should not care about whether a picture was taken at day or at night. However, if the overall brighness varies over a set of images that is processed by PCA, the first principal components will mostly contain the brightness information.
s ^ = arg max s s.t. ∥ s ∥ = 1 s ⊤ Σ Σ ⊤ s = arg max s s.t. ∥ s ∥ = 1 ∣ ∣ s Σ ∣ ∣ 2 = arg max s s.t. ∥ s ∥ = 1 ∣ ∣ s diag ( σ 1 , 1 , . . . , σ p , p ) ∣ ∣ 2 \begin{aligned} \hat{\mathrm{s}} &=\underset{\mathrm{s} \text { s.t. }\|\mathrm{s}\|=1}{\argmax } \ \mathrm{s}^{\top} \Sigma \Sigma^{\top} \mathrm{s}\\ &= \underset{\mathrm{s} \text { s.t. }\|\mathrm{s}\|=1}{\argmax } \ ||\mathrm{s}\Sigma||^2 \\ &= \underset{\mathrm{s} \text { s.t. }\|\mathrm{s}\|=1}{\argmax } \ ||\mathrm{s} \operatorname{diag}(\sigma_{1,1}, ...,\sigma_{p,p})||^2 \\ \end{aligned} s^=s s.t. ∥s∥=1argmax s⊤ΣΣ⊤s=s s.t. ∥s∥=1argmax ∣∣sΣ∣∣2=s s.t. ∥s∥=1argmax ∣∣sdiag(σ1,1,...,σp,p)∣∣2
s ^ = arg max s s.t. ∥ s ∥ = 1 s ⊤ Σ Σ ⊤ s \hat{\mathrm{s}}=\underset{\mathrm{s} \text { s.t. }\|\mathrm{s}\|=1}{\argmax } \ \mathrm{s}^{\top} \Sigma \Sigma^{\top} \mathrm{s} s^=s s.t. ∥s∥=1argmax s⊤ΣΣ⊤s.