- 主成分分析(Principal Component Analysis,PCA)是一种常用的无监督学习方法
- 利用正交变换把由
线性相关变量表示的观测数据 转换为 少数几个由线性无关变量表示的数据,线性无关的变量 称为 主成分
- 主成分的个数
通常小于原始变量的个数,所以PCA属于降维方法
- 主要用于发现数据中的
基本结构,即数据中变量之间的关系,是数据分析的有力工具,也用于其他机器学习方法的前处理
- PCA属于
多元统计分析的经典方法
1. 总体主成分分析
第一轴选取方差最大的轴 y1
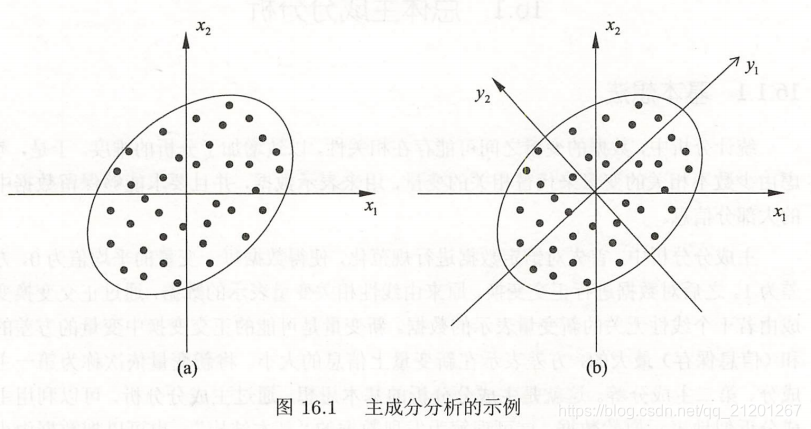
主成分分析 的主要目的是降维,所以一般选择 k(
k≪m)个主成分(线性无关变量)来代替m个原有变量(线性相关变量),使问题得以简化,并能保留原有变量的大部分信息(原有变量的方差)。
在实际问题中,不同变量可能有不同的量纲,直接求主成分有时会产生不合理的结果。
为了消除这个影响,常常对各个随机变量实施规范化,使其均值为0,方差为1。
主成分分析的结果可以用于其他机器学习方法的输入。
- 将样本点投影到以主成分为坐标轴的空间中,然后应用聚类算法,就可以对样本点进行聚类
定义:
假设
xxx 为
m 维随机变量,均值为
μ,协方差矩阵为
Σ
随机变量
xxx 到
m 维随机变量
yyy 的线性变换
yi=αiTxxx=k=1∑mαkixk,i=1,2,...,m
其中
αiT=(α1i,α2i,...,αmi)
如果该线性变换满足以下条件,称之为总体主成分:
-
αiTαi=1,i=1,2,...,m
-
cov(yi,yj)=0(i=j)
-
y1 是
xxx 的所有线性变换中
方差最大的,
y2 是与
y1 不相关的
xxx 的所有线性变换中方差最大的,以此类推,
y1,y2,...,ym 称为第一主成分…第
m 主成分
假设
xxx 是
m 维随机变量,其协方差矩阵
Σ 的特征值分别是
λ1≥λ2≥...≥λm≥0,特征值对应的单位特征向量分别是
α1,α2,...,αm,则
xxx 的第
i 主成分可写作:
yi=αiTxxx=k=1∑mαkixk,i=1,2,...,m
并且,
xxx 的第
i 主成分的方差是协方差矩阵
Σ 的第
i 个特征值,即:
var(yi)=αiTΣαi=λi
主成分性质:
-
主成分
yyy 的协方差矩阵是对角矩阵
cov(yyy)=Λ=diag(λ1,λ2,...,λm)
-
主成分
yyy 的方差之和等于随机变量
xxx 的方差之和
i=1∑mλi=i=1∑mσii
其中
σii 是
xi 的方差,即协方差矩阵
Σ 的对角线元素
-
主成分
yk 与变量
xi 的 相关系数
ρ(yk,xi) 称为因子负荷量(factor loading),它表示第
k 个主成分
yk 与变量
xi 的相关关系,即
yk 对
xi 的贡献程度
ρ(yk,xi)=σii
λk
αik,k,i=1,2,...,m
2. 样本主成分分析
是基于样本协方差矩阵的主成分分析
给定样本矩阵
X

X 的样本协方差矩阵
S=[sij]m×n,sij=n−11k=1∑m(xik−xˉi)(xjk−xˉj)i=1,2,...,m,j=1,2,...,m,其中xˉi=n1k=1∑nxik
给定样本
X,考虑
xxx 到
yyy 的线性变换
yyy=ATxxx

如果满足以下条件,称之为样本主成分:
- 样本第一主成分
y1=α1Txxx 是在
α1Tα1=1 条件下,使得
α1Txxxj(j=1,2,...,n) 的样本方差
α1TSα1 最大的
xxx 的线性变换,以此类推。
- 样本第
i 主成分
yi=αiTxxx 是在
αiTαi=1 和
αiTxxxj 与
αkTxxxj(k<i,j=1,2,...,n)的样本协方差
αkTSαi=0 条件下,使得
αiTxxxj(j=1,2,...,n) 的样本方差
αiTSαi 最大的
xxx 的线性变换
3. 主成分分析方法
3.1 相关矩阵的特征值分解算法
- 针对
m×n 样本矩阵
X ,求样本
相关矩阵
R=n−11XXT
- 再求样本
相关矩阵的
k 个特征值和对应单位特征向量,构造正交矩阵
V=(v1,v2,...,vk)
-
V 的每一列对应一个主成分,得到
k×n 样本
主成分矩阵
Y=VTX
3.2 矩阵奇异值分解算法
- 针对
m×n 样本矩阵
X ,
X′=n−1
1XT
- 对矩阵
X 进行
截断奇异值分解,保留
k 个奇异值、奇异向量
得到
X′=USVT
-
V 的每一列对应一个主成分,得到
k×n 样本
主成分矩阵
Y=VTX
