1 介绍
1.1 特点
- 一个非监督的机器学习算法
- 主要用于数据的降维,通过降维,可以发现便于人类理解的特征
- 其他应用:可视化;去噪
1.2 数学意义
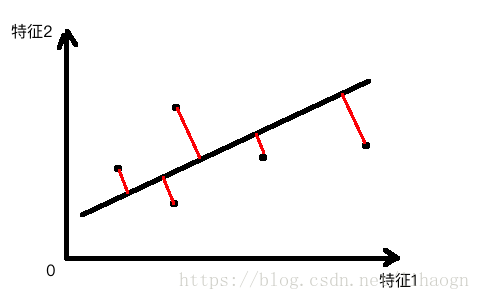
- 找到让样本间间距最大的轴
- 定义样本间间距,使用方差:
- 找到一个轴,使得样本空间的所有点映射到这个轴后,方差最大。
1.3 步骤
- 对所有样本进行demean处理,即将样本的均值归为0,则
- 求一个轴的方向 ,使得我们所有的样本映射到 以后,有 的值最大。
1.4 公式推导
1)
2)
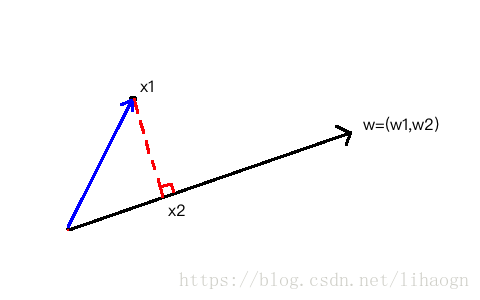
令
,有
3)目标:求 ,使 的值最大
2 梯度上升法求梯度
令 ,有
3 求前n个主成分
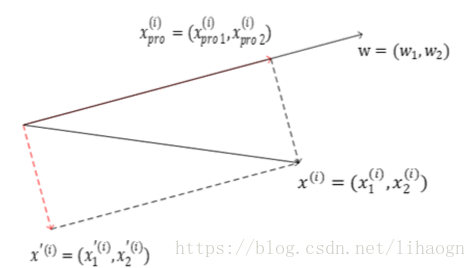
1)求出第一主成分后,如何求出下一主成分?
–> 数据进行改变,将数据在第一个主成分上的分量去掉,然后在新的数据上求第一主成分。
4 降维
降维可以使得数据处理时间减少,但会损失准确度。
1)高维数据向低维数据映射
前 k 个成分:
从 n 维映射到 k 维:
从 k 维还原成 n 维:(还原后会损失信息)
4 代码
1)PCA.py
import numpy as np
import matplotlib.pyplot as plt
class PCA:
def __init__(self, n_components):
""" 初始化PCA"""
assert n_components >= 1, "n_components must be valid."
self.n_components = n_components
# 获取的主成分矩阵
self.components_ = None
def fit(self, xx, eta=0.01, n_iters=1e4):
""" 获得数据集xx的前n个主成分"""
assert self.n_components <= xx.shape[1], "n_components must be greater than the feature num of xx."
def demean(xx):
return xx - np.mean(xx, axis=0)
def f(w, xx):
""" 函数f """
return np.sum((xx.dot(w) ** 2)) / len(xx)
def df(w, xx):
""" 函数f的梯度 """
return xx.T.dot(xx.dot(w)) * 2. / len(xx)
def direction(w):
""" 求w的单位向量"""
return w / np.linalg.norm(w)
def first_component(xx, initial_w, eta=0.01, n_iters=1e4, epsilon=1e-8):
w = direction(initial_w)
cur_iter = 0
while cur_iter < n_iters:
gradient = df(w, xx)
last_w = w
w = w + eta * gradient
w = direction(w) # 注意1:每次求一个单位方向
if (abs(f(w, xx) - f(last_w, xx)) < epsilon):
break
cur_iter += 1
return w
xx_pca = demean(xx)
self.components_ = np.empty(shape=(self.n_components, xx.shape[1]))
for i in range(self.n_components):
# 注意2:初始位置不能为0,不能从0向量开始
initial_w = np.random.random(xx_pca.shape[1])
w = first_component(xx_pca, initial_w, eta, n_iters)
self.components_[i, :] = w
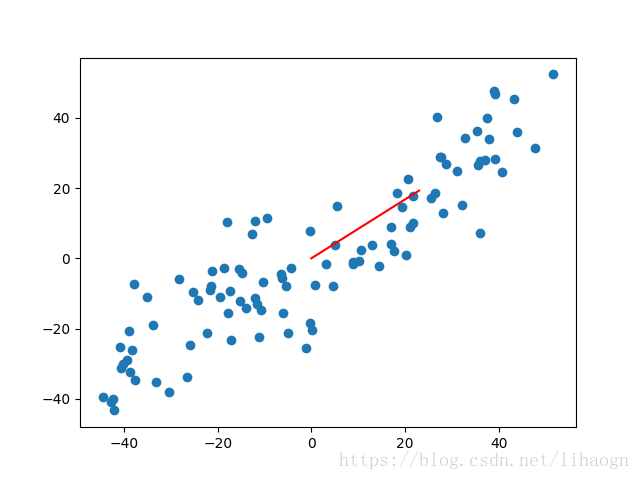
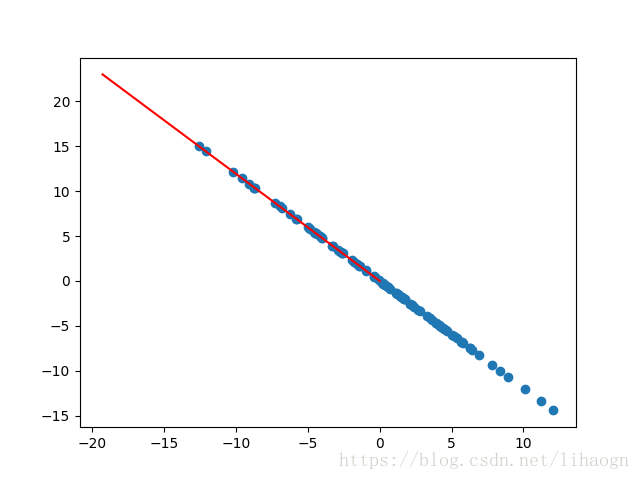
plt.scatter(xx_pca[:, 0], xx_pca[:, 1])
plt.plot([0, w[0] * 30], [0, w[1] * 30], color='r')
plt.show()
# 去除前一个主成分
xx_pca = xx_pca - xx_pca.dot(w).reshape(-1, 1) * w
# 注意3:不能使用StandardScaler标准化数据(归一化)
return self
def transform(self, xx):
""" 将给定的xx,映射到各个主成分分量中,降维 """
assert xx.shape[1] == self.components_.shape[1]
return xx.dot(self.components_.T)
def inverse_transform(self, xx):
""" 将给定的xx,反向映射回原来的特征空间"""
assert xx.shape[1] == self.components_.shape[0]
return xx.dot(self.components_)
def __repr__(self):
return "PCA(n_components=%d)" % self.n_components
2)测试代码:pca_test.py
import numpy as np
import matplotlib.pyplot as plt
from PCA_pro.PCA import PCA
# 1 准备数据
xx = np.empty((100, 2))
xx[:, 0] = np.random.uniform(0., 100., size=100)
xx[:, 1] = 0.75 * xx[:, 0] + 3. + np.random.normal(0, 10., size=100)
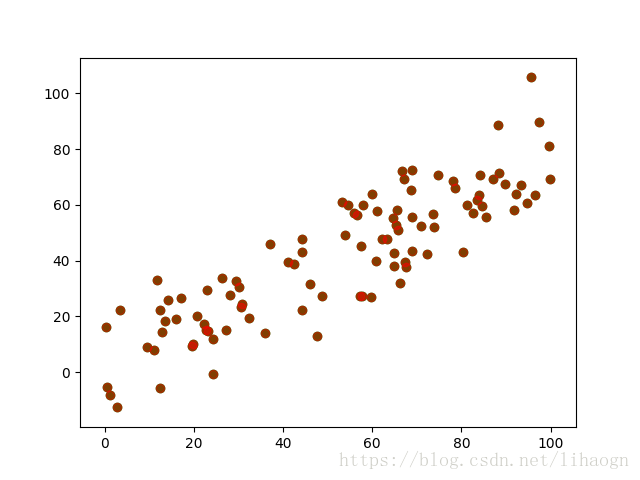
plt.scatter(xx[:, 0], xx[:, 1])
plt.show()
# 2 求主成分和其他成分
mpca2=PCA(2)
mpca2.fit(xx)
print(mpca2.components_)
# 3 降维
xx_reduction = mpca2.transform(xx)
print("xx_reduction.shape:", xx_reduction.shape)
# 恢复降维,损失了信息
xx_restore = mpca2.inverse_transform(xx_reduction)
print("xx_restore.shape", xx_restore.shape)
plt.scatter(xx[:, 0], xx[:, 1], color='g')
plt.scatter(xx_restore[:, 0], xx_restore[:, 1], color='r', alpha=0.5)
plt.show()
3)运行结果:
[[ 0.76608005 0.64274518]
[-0.64274259 0.76608221]]
xx_reduction.shape: (100, 2)
xx_restore.shape (100, 2)