PCA是非常重要的统计方法,其实际应用非常广泛,但是很多讲解太过于公式化,很难让初学者消化,本文将从一个实际例子出发,并对数学公式原理及推导过程作出详细解释,即使你的数学基础比较差,在看完这篇博客之后,相信你会对PCA会有一个透彻的认知。
PCA的思想就是将n维特征映射到k维上(k<n),这k维是重新构造出来的全新维度特征,而不是简单的从n维特征去除n-k维特征,这k维就是主成分。
1.导读
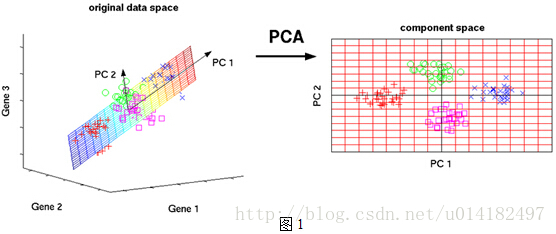
如图所示,在三维坐标系中,四种颜色的标记界限并不直观,但是在重新定义的二维坐标系中,四种颜色标记界限非常直观,这就是一个典型的PCA,在降维的同时最大程度的保留了数据的特征,为后续的分析提供更直观的支持。
上图PCA过程中有两步非常重要,一是寻找差异最明显的PC1、PC2坐标系所在的平面,二是如何把Gene1、Gene2、Gene3坐标系中的点映射到PC1、PC2的坐标系中。这也是所有PCA非常重要的两步,一是寻找差异最明显坐标系的新维度,二是把之前多维坐标系中的点映射到新维度的坐标系中。
2.PCA步骤
废话不多说,我们首先来看一下PCA的步骤,一步步的去理解。
1.对数据中心化
2.求特征的协方差矩阵
3.求协方差矩阵的特征值和特征向量
4.取最大的k个特征值所对应的特征向量
5.将样本点投影到选取的特征向量上
看到这里呢,可能很多人不理解,而且有些数学概念不清楚,这都没关系,通过下面的例子你再看这五个步骤你会发现原来如此。
3.PCA实例
现在假设有一组数据如下:
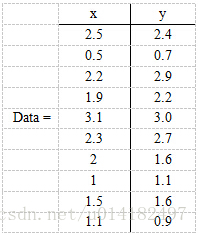
行代表了样例,列代表维度,这里有10个样例,每个样例两个维度。我们如何用一个维度来表示这10个样例。这个可以理解为在直角坐标系的中的十个点,如何找到一个直线,这个直线就是全新的维度,是主成分。让10个样例映射到这个直线上,得到的划分最明显。
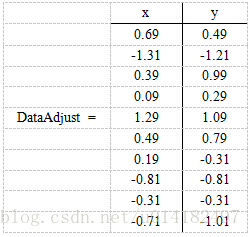
第一步:数据中心化。中心化指的是中心化是指数据集中的各项数据减去数据集的均值,中心化的目的是提高训练速度。我们分别求x和y的平均值,然后对于所有的样例,都减去对应的均值。这里x的均值是1.81,y的均值是1.91,那么第一个样例减去均值后即为(0.69,0.49),同理得到
第二步:求特征的协方差矩阵。这里简单的介绍下协方差矩阵,大家都知道方差是用来度量单个变量 “ 自身变异”大小的总体参数,方差越大表明该变量的变异越大。方差一般是用来描述一维数据的,但是我们尝尝面对多维的数据集,比如这个实例目前就是二维的,这时候我们就可以用协方差来度量两个变量之间 互相影响大小的参数。如果结果是正,说明两个变量是正相关。如果结果为负,说明两个变量是负相关。协方差的绝对值越大,则二个变量相互影响越大 ,反之则越小。协方差矩阵代表了样本集在不同维度之间的方差,我们可以理解为协方差矩阵就是来度量各个维度偏离其均值的程度,也就是不同维度之间互相影响的相关性,首先我们来对比一下方差和协方差公式来加深理解:
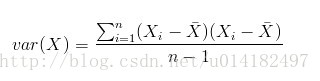
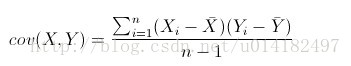
接下来看一下方差矩阵的表示,我这里没找到二维协方差矩阵的表示,用三维协方差矩阵表示一下:
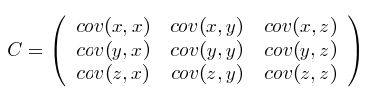
二维和更多维的同理,这里求的协方差矩阵为:
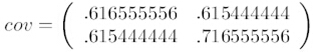
第三步:求协方差矩阵的特征值和特征向量。
通过上一步,我们已经建立起每个维度之间互相影响相关性的矩阵,绝对值高表示相关度高,绝对值低表示相关性低。我们理想的一维(也就是最终的直线)应该与更多相关性高的方向垂直,这样可以找到一条直线,使二维中的点最大程度的投影在不同的区域,虽然维度降低,但是每个点之间的区分依然非常明显。这是PCA最关键的地方,比较抽象,但是想明白了就觉得很简单。那么我们如何去确定相关性高的方向呢?我们可以用协方差的特征值和特征向量来计算准确的方向。其实协方差的特征向量表示样本集的相关性集中分布在这些方向,而特征值就;反映了样本集在该方向上的相关性大小。PCA正是基于这一点,寻找区分最明显的方向,防止降维使样本集区分不开的状况。
特征值和特征向量的计算公式在这里就不详细介绍,因为占用空间比较多,不懂得可以看一下这篇博客:特征值和特征向量
经过计算,我们得到协方差的特征值和特征向量如下:
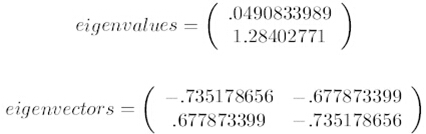
第四步:取最大的k个特征值所对应的特征向量。将特征值按照从大到小的顺序排序,选择其中最大的k个,然后将其对应的k个特征向量分别作为列向量组成特征向量矩阵。
这里特征值只有两个,我们选择其中最大的那个,这里是1.28402771,对应的特征向量是(-0.677873399, -0.735178656)T。这里特征向量的方向也就是我们最终理想直线的方向。
第五步:将样本点投影到选取的特征向量上。将样本点投影到选取的特征向量上。假设样例数为m,特征数为n,减去均值后的样本矩阵为DataAdjust(m*n),协方差矩阵是n*n,选取的k个特征向量组成的矩阵为EigenVectors(n*k)。那么投影后的数据FinalData为FinalData(10*1) = DataAdjust(10*2矩阵) x 特征向量(-0.677873399,-0.735178656)T,得到的结果是
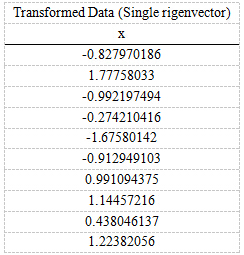
这样,就将原始样例的2维特征变成了1维,这1维就是原始特征在1维上的投影。现在大家回头看第二部分的PCA步骤大纲是不是柳暗花明?