【李宏毅机器学习笔记】5、Logistic Regression
【李宏毅机器学习笔记】6、简短介绍Deep Learning
------------------------------------------------------------------------------------------------------
【李宏毅深度强化学习】视频地址:https://www.bilibili.com/video/av10590361?p=11
课件地址:http://speech.ee.ntu.edu.tw/~tlkagk/courses_ML17_2.html

-------------------------------------------------------------------------------------------------------
按照之前课程的内容,机器学习分为三步:
- 定义模型(function set)
- 找出损失函数
- 找出最好的function
所以Logistic Regression这里,还是以这三步来走。
Step 1: 定义Function Set

在上一篇笔记,给出了![]() ,如果这个概率大于0.5,则代表 x 属于
,如果这个概率大于0.5,则代表 x 属于 ,否则属于
。
同样,在上一篇笔记中,将![]() 由贝叶斯公式化为sigmoid function
由贝叶斯公式化为sigmoid function 。
这里以![]() 作为我们的模型(function set)。这个function set里由于不同的w和b就会形成不同的function。
作为我们的模型(function set)。这个function set里由于不同的w和b就会形成不同的function。

上图可以看出,Logistic Regression和Linear Regression的区别在于 :
- Logistic Regression多了sigmoid的步骤,所以最终的输出只会在 ( 0,1 ) 之间。
Step 2: Goodness of a Function

training data如图,有N个数据,分别是从到
。每个数据都对应一个label,表示 x 属于哪一类。
现在,将这些training data看成是从![]() 这个函数产生的。
这个函数产生的。
![]() 代表
代表![]() 在某一组参数 w和b 下,
在某一组参数 w和b 下,![]() 产生这些 training data 的几率。(这里是考虑的是二分类)
产生这些 training data 的几率。(这里是考虑的是二分类)
我们的目标就是,找到一组最好的参数 和
,这两个参数能使
![]() 达到最大值。
达到最大值。
举个最极端理想的例子,![]() 产生这些training data的几率是1,这就意味着给任意个数据 x,
产生这些training data的几率是1,这就意味着给任意个数据 x,![]() 都能得出 x 的正确分类(准确说
都能得出 x 的正确分类(准确说![]() 是输出概率,从这个概率找到正确的分类)。
是输出概率,从这个概率找到正确的分类)。

刚才说要找一组最好的参数 和
,使
![]() 达到最大值。这件事可以看成找一组最好的参数
达到最大值。这件事可以看成找一组最好的参数 和
,使
![]() 达到最小值(给
达到最小值(给![]() 加 ln 是为了计算更方便,不会对结果产生影响)。
加 ln 是为了计算更方便,不会对结果产生影响)。
给![]() 加 ln 后,根据ln 的特性,如图,原来相乘变相加。
加 ln 后,根据ln 的特性,如图,原来相乘变相加。
这时的公式虽然变成相加,但是还是没办法写成 累加的格式。
为了做到这一点,将属于Class 1 的 x 的目标值y^\hat都设为1,将属于Class 2 的 x 的目标值y^\hat都设为0。此时![]() 的每一项就可以替换成右边很长的式子,右边的式子就等价于左边的式子。如下:
的每一项就可以替换成右边很长的式子,右边的式子就等价于左边的式子。如下:

以第一项为例子,Class 1 的 x 的目标值 y^\hat 以1代进去,后面代进去变成0,所以右边的式子化简后和左边的式子是一样的。
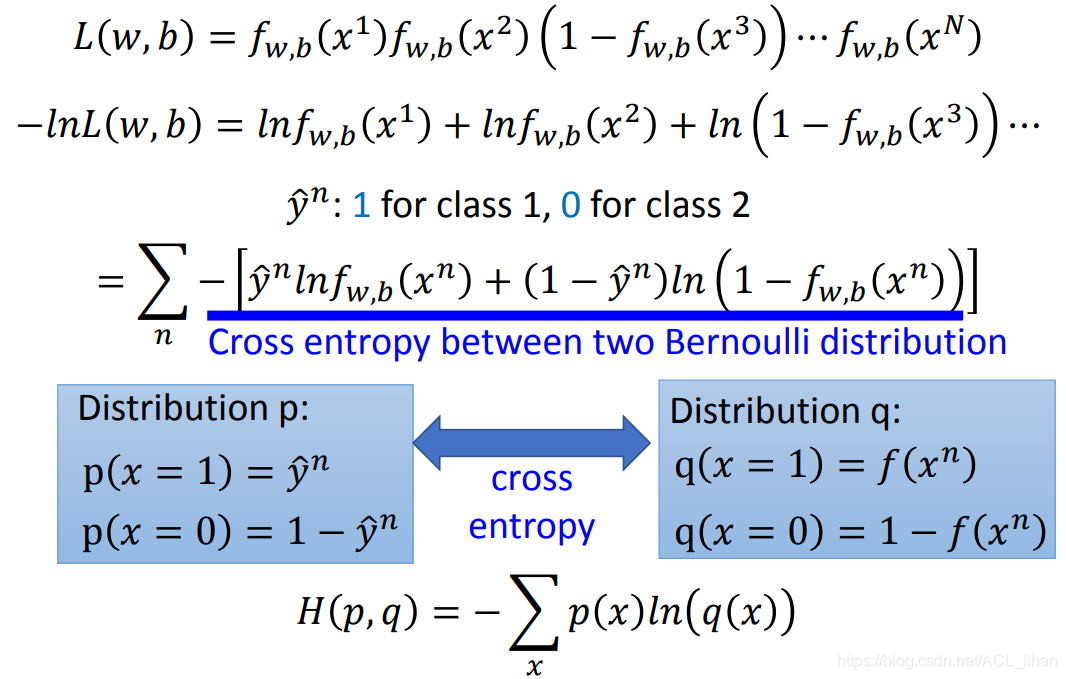
这时![]() 就能表示如图所示的
就能表示如图所示的 累加的格式。
画蓝线的部分就是两个伯努利分布之间的cross entropy 。如果两个分布一样的话,cross entropy就等于0。这式子可以看成是损失函数。
分布p看成training data,分布q是预测的结果。![]() 就是它们的 cross entropy 。
就是它们的 cross entropy 。

图中是Logistic Regression和Linear Regression的损失函数的对比。
Logistic Regression为什么不用和Linear Regression一样的损失函数的原因等下会讲。
Step 3: Find the best function


第三部就是gradient descent,去更新参数。
对![]() 求 w 的偏导,就是对画蓝线的两项(
求 w 的偏导,就是对画蓝线的两项(![]() 和
和![]() )求偏导。求导过程如上图所示。
)求偏导。求导过程如上图所示。

上图是求偏导后的整理过程。
最后算出来是![]() 。
。![]() 代表目标值,
代表目标值,![]() 代表预测的值。
代表预测的值。
现在做gradient descent取决于三个因素:
- learning rate

 ,这两项的差越大,代表预测值和目标值差距越大,所以update参数时更新得越大
,这两项的差越大,代表预测值和目标值差距越大,所以update参数时更新得越大- data中的某一个x 的某一个feature,


这里看第三步,可以看出Logistic Regression和Linear Regression的更新公式是一模一样的。
唯一不同的是,Logistic Regression的![]() 是0或1,
是0或1,![]() 是介于0到1之间。而Linear Regression的
是介于0到1之间。而Linear Regression的![]() 和
和![]() 可以是任意值。
可以是任意值。


文章刚才有说过一个问题,为什么 Logistic Regression 不用和 Linear Regression 一样的损失函数(Square Error)?
如图,Logistic Regression 使用并对 w 求偏导得到结果如图。
当![]() 时,不管
时,不管![]() 估值准确(输出值趋近1)还是不准确(输出值趋近0),最后结果都趋近0。
估值准确(输出值趋近1)还是不准确(输出值趋近0),最后结果都趋近0。
当![]() 时,不管
时,不管![]() 估值准确(输出值趋近0)还是不准确(输出值趋近1),最后结果都趋近0。
估值准确(输出值趋近0)还是不准确(输出值趋近1),最后结果都趋近0。
这样就会导致参数更新的速度超级慢。

黑色的是Cross Entropy,红色的是Square Error。可以看出用 Square Error 无论在哪个点,它算出来的gradient都很小,所以参数更新速度慢。
这里可能有人想用之前笔记讲过的方法,离最低点远就用大的learning rate,离最低点近就用小的learning rate。但在这里行不通。之前笔记说过gradient越大,说明此时离最低点越远。但现在无论在哪个点gradient都很小,所以没办法推测出它现在所处位置距离最低点远不远。
Discriminative 对比 Generative

Logistic Regression是一种Discriminative的方法。而上一篇笔记中,生成高斯分布的方法是Generative的方法。
它们的model(function set)都是![]() ,但Logistic Regression能直接找出w和b,而Generative model要通过算出
,但Logistic Regression能直接找出w和b,而Generative model要通过算出,
,
,才能得到w和b的值(具体看上篇笔记的内容)。
虽然这两个方法的model一样,但并不代表最后找出最好的function的 w和b 是一样的。

这是两种方法在分类神奇宝贝的例子中的表现。 图中是只有两个feature的例子,而所以不怎么看得出区别。而如果使用7个feature的话,Logistic Regression分类效果更好。
下面是一个例子,能更清楚两种方法的区别:

training data如图。现在给一个![]() ,以我们人类的直觉会判断它是Class 1的。但作为Generative model方法的Naive Bayes会判断它是属于哪一类呢?
,以我们人类的直觉会判断它是Class 1的。但作为Generative model方法的Naive Bayes会判断它是属于哪一类呢?

经过一系列计算后,发现使用Naive Bayes,它判断这个data属于Class 1的几率会低于0.5(即判断它属于Class 2)。
这是因为Naive Bayes会根据这些training data去生成一个分布,在那个分布里,![]() 是属于Class 2的。
是属于Class 2的。
就是说,Generative model会根据training data去生成一个分布(具体内容看上篇笔记),再做判断。而Discriminative则只会根据training data去做判断。
Generative model的优势

虽然Generative model生成的分布里,可能会出现和training data不一样的data,导致分类结果不对。
但并不是说Generative不如Discriminative。Generative在以下情况还是有优势的:
- Discriminative model是看着training data做训练,所以一般training data越多,它的error越小。而Generative model所需的training data不用太多,因为Generative model会根据training data自己去脑补一个有着更多data的分布。
- 因为Generative model根据training data去生成分布,再根据这个分布做判断。所以比起直接根据training data做判断的Discriminative model,Generative model会少受noisy(即有些data的label是错的)的影响。
- Discriminative model直接求后验概率,而Generative model将后验概率
 拆成算先验
拆成算先验 和最大似然。而先验和类相关的概率可以用不同的data来进行估计。
和最大似然。而先验和类相关的概率可以用不同的data来进行估计。
Multi-class Classification

、
、
三个类都有参数 w 和 b 。
把、
、
经过softmax函数,得到 x 属于
、
、
、的概率。
softmax函数做的就是,把、
、
分别取exp ,然后求和。求和后再除以
、
、
就得到 x 属于
、
、
、的概率。

估出来的值 、
、
和 目标值
\hat、
\hat、
\hat 计算Cross Entropy。然后更新参数使估值向目标值靠近。
Limitation of Logistic Regression

如右下图所示,使用Logistic Regression能分开图中的红蓝点两个种类吗?

答案是不能。所以要使用Feature Transformation(特征转换)
Feature Transformation(特征转换)

将左图的四个点,计算各自和点[0,0],点[1,1]的距离,变成右图的样子,这时就可以找到一条分界线对它们进行分类。
但是并不是所有问题都能顺利找到转换的方法,而且转换的过程是有人工进行干预。
所以下面介绍一种不用人工干预的方法,就是Cascading logistic regression models。
Cascading logistic regression models

输入一个点,坐标为(,
),分别乘上各自的weight后,两者相加,形成
,再经过sigmoid函数输出
。
同理。 这一步就完成了feature transformation。
得到、
后,在乘上各自的weight后,两者相加,形成
,再经过sigmoid函数输出 y 。这时就完成分类。
这么说有点抽象,下面举个具体例子:

调整两个Logistic Regression model的参数,以达到以下目的:输入坐标(,
),输出的坐标(
、
)。 如右图所示。
比如原来左下角的点坐标是(0,0),经过转换后变为(0.27,0.27)

最后转换结果如图所示,这时再用一个Logistic Regression就可以把两个类区分开。
可以看到,把多个Logistic Regression叠在一起就解决原来一个Logistic Regression解决不了的问题。
Deep Learning

前面的 Logistic Regression model 的输出,作为后面 Logistic Regression model 的输入,同样它的输出又可以作为再后面的Logistic Regression model的输入。
这样的话,每一个Logistic Regression model 就是一个神经元(Neuron),这些神经元串起来,就形成一个网络,这就是神经网络(Neural Network)。
