上一篇中已经分析了详情页的url规则,并且对items.py文件进行了编写,定义了我们需要提取的字段,本篇将具体的items字段提取出来
这里主要是涉及到选择器的一些用法,如果不是很熟,可以参考:scrapy选择器的使用
依旧是在lagou_c.py文件中编写代码
首先是导入LagouItem类,因为两个__init__.py文件的存在,所在的文件夹可以作为python包来使用
from lagou.items import LagouItem
编写parse_item()函数(同样为了详细解释,又是一波注释风暴):
def parse_item(self, response): item = LagouItem() #生成一个item对象 item['url'] = response.url #这个response是详情页面的response,因为本次我们只对详情页面使用了回调函数,所以可以这样理解 item['name'] = response.css('.name::text').extract_first() #用css选择器选择职位名称,因为结果是个列表,所以使用extract_first()提取第一个 item['salary'] = response.css('.salary::text').extract_first() #用css选择器选择薪水,但是这个是一个string类型,后续可以进行优化 location = response.xpath('//*[@class="job_request"]//span[2]/text()').extract_first() #使用xpath进行提取,span[2]代表多个平行span标签选择第二个 item['location'] = self.remove_splash(location) #得到的文本带有/,还有多余的空格,使用remove_splash函数进行清除,当然这个函数需要自己定义 work_exp = response.xpath('//*[@class="job_request"]//span[3]/text()').extract_first() #获取工作经验要求 item['work_exp'] = self.remove_splash(work_exp) #使用remove_splash对数据清洗 edu_background = response.xpath('//*[@class="job_request"]//span[4]/text()').extract_first() #获取学历要求 item['edu_background'] = self.remove_splash(edu_background) item['type'] = response.xpath('//*[@class="job_request"]//span[5]/text()').extract_first() #获取职位类型,全职or兼职 tags = response.css('.labels::text').extract() #tags是一个列表类型,直接使用extract()进行提取,而不使用extract_first() item['tags'] = ','.join(tags) #join函数是python内置函数,作用是把一个序列拼接起来,这里是用逗号把所有的tags标签拼接起来构成一个新的列表 item['release_time'] = response.css('.publish_time::text').extract_first() #获取发布时间,实际上这个发布时间存在很多种情况,有具体日期,也有几天前这种,后续进行优化 advantage = response.css('.job-advantage p::text').extract() #职位诱惑 item['advantage'] = '\n'.join(advantage) #用join进行拼接 job_desc = response.css('.job_bt p::text').extract() #获取职位描述 item['job_desc'] = '\n'.join(job_desc) work_addr = response.css('.work_addr a::text').extract()[:-1] #这个工作地址列表提取出来后,需要把最后一项去掉,最后一项是地图。。 item['work_addr'] = ''.join(work_addr) item['company'] = response.css('.job_company img::attr(alt)').extract_first() #获取公司名称 yield item
编写remove_splash()函数,这个函数传入一个值,然后对值中的/替换为空,最后将首尾的空格去掉
def remove_splash(self,value): return value.replace(r'/','').strip()
这样我们就把需要提取的字段都提取了出来,再次运行爬虫scrapy crawl lagou_c,控制台就可以得到类似如下的输出了
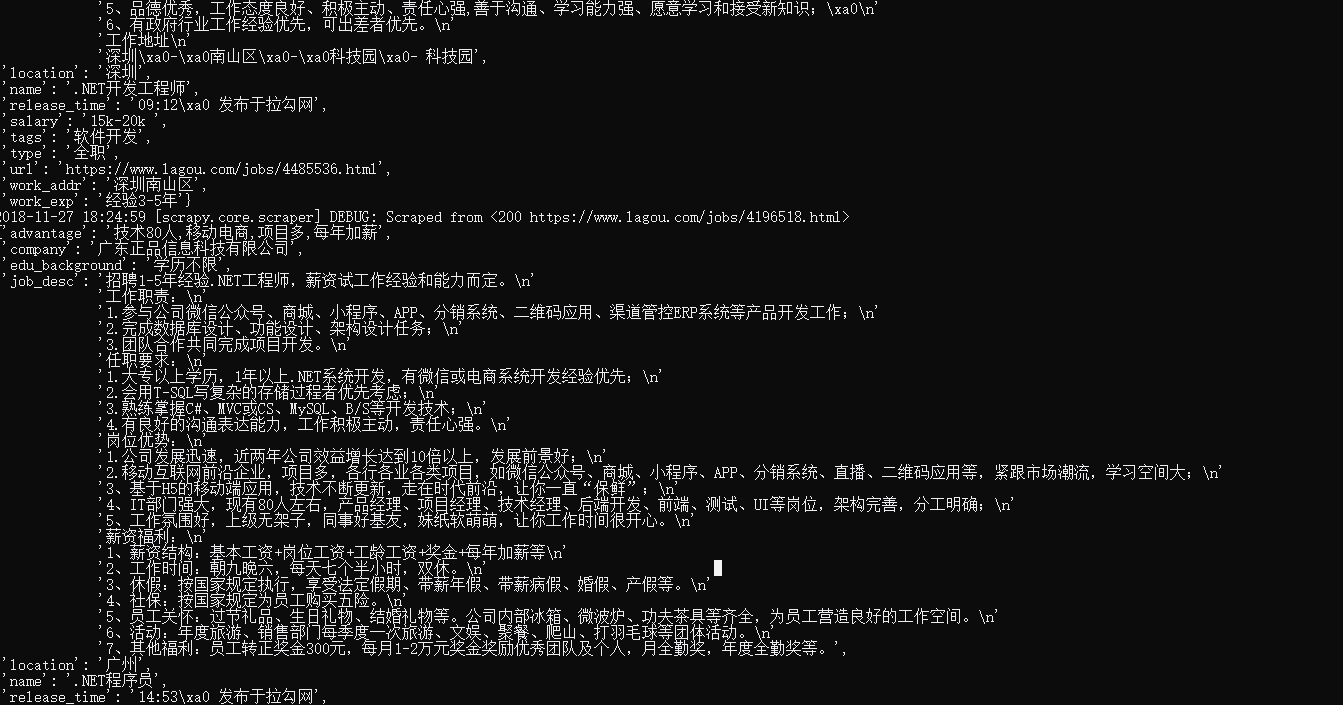
但是这抓取速度实在有点太吓人了。。。很怕被封了IP,要么限制下载速度,要么使用代理,我这里先使用限制下载速度这种措施
在settings.py文件中,取消DOWNLOAD_DELAY的注释修改为DOWNLOAD_DELAY = 1。
我们启动爬虫都是用命令行的方式来实现的,每次输入命令有点麻烦,这里我们修改一下
在根目录下建立一个main.py文件(说了那么多次根目录,其实就是进入项目文件夹后的第一个目录),代码如下:
from scrapy import cmdline cmdline.execute('scrapy crawl lagou_c'.split())
使用这种方式得到的结果是相同的
