参考论文解析:https://blog.csdn.net/Coralccccc/article/details/73956702
论文翻译:https://blog.csdn.net/u014264373/article/details/79581655
标题:Deep Multi-instance Networks with Sparse Label Assignment for Whole Mammogram Classification
来源:MICCAI 2017
作者:Wentao Zhu, Qi Lou, Yeeleng Scott Vang, and Xiaohui Xie
解决的问题:肿块分类
现有方法 : 多阶段集成。将mass classification分成3个模块:detection, segmentation, classification。
存在的问题:
① 除了每个模块自身的性能问题,这个框架需要单独训练每个模块。多阶段不能完全挖掘出深度神经网络的力量。
② 需要很多ground truth信息 : bbox for detection, segmentation map, mass label。标定这些GT信息,很耗人力。
③ 需要手工特征。
本文方法: end-to-end (端到端)+ multi-instance learning(MIL)
输入:乳腺图像,图像的标签(正常图像 Vs 恶性肿块图像)
输出:对于新的乳腺图像,判断它的标签
(ps. 此处正常图像包括:不含肿块图像&良性肿块图像)
本文方法具体介绍
一、MIL:
假设一个bag上有多个instance。一个instance被分类为positive,bag就被认为是positive;所有instance都被分类为negative,bag才被认为是negative。对应到乳腺图像分析上,将一个image分成多个patch。一个patch被分类为恶性肿块区域,image就被认为是恶性肿块图像;所有patch都被分类为正常乳腺组织,image就被认为是正常图像。于是,本文只考虑image上是恶性肿块概率最大的那个patch,它的良恶性就决定了整幅图像的性质。
如何利用MIL:它是基于原始整个乳房X光图片进行分类。它将每个乳房X光照片的patch看做示例,将整个乳房X光照片看做a bag of instances即上面说的包。那么这个分类问题可以看做是标准的MIL问题。

二、方法的整个过程(如图所示)
作为一个实例,整个乳房X线照片被视为一袋实例。 整体乳房X线照相分类问题可以被认为是一个标准的多实例学习问题。 因此,我们提出了三种不同的方案,即最大池 maxpooling,标签分配 label assignment和稀疏性sparsity,为整体进行深入的多实例学习乳房X线照片分类任务.
网络结构:多个卷积层,一个线性回归层,排序层,多实例损失层

1) 预处理,将乳腺区域分割出来。
- 首先使用大津方法(类内方差最小,类间方差最大)来移除背景同时resize到227*227
2)用CNN对图像提取特征。此处用的是AlexNet,提取的是它最后一个卷积层,也就是第五个卷积层的特征。由于AlexNet的输入大小限制,这里将图像resize成227*227的,经过Alex-net的5个卷积层后,得到256个6*6的feature map。
- 使用AlexNet中的卷积层,提取它最后一个卷积层的特征。最后会得到6*6*256的feature map
3) 对CNN中的feature map进行基于恶性(当确定为恶性是为1)不同patch之间权值共享的logistic regression来表示每个位置的恶性概率,然后将response进行rank。
对这些feature map做逻辑回归。256个feature map经过逻辑回归之后得到1个6*6的map。这个6*6 map上的每个位置,对应了feature map上相同位置的256个特征值。逻辑回归就是用这256个特征值给每个位置一个评分。评分的大小就是每个位置可能是恶性肿块的概率。此处逻辑回归的公式为:
Fi,j表示第i行第j列的256个特征值,与长度为256的权值向量a做点乘,再加偏置b,然后做sigmoid,得到[0,1]之间的一个数,作为位置(i,j)是恶性肿块的概率。权值向量a和偏置b是所有位置共享的。(ps. 此处有两个疑问:① 什么是[0,1],不应该是(0,1)吗? ② 此处的逻辑回归操作跟1*1卷积有什么不同。个人觉得没什么不同,那为什么不直接表达成1*1卷积呢?)
4)对这6*6=36个概率值r1,r2,...,rm从大到小排序,得到r1',r2',...,rm'
5)

将patch中最大的恶性肿块概率值r1'作为整幅图像是恶性肿块图像的概率,而1-r1'作为整幅图像是正常图像的概率。这个想法和MIL是契合的,我们关注概率最大的那一patch,该patch是positive的,整幅图像就positive;该patch是negative的,由于概率是从大到小排序,整幅图像就negative。
Inference阶段,如果这个最大的概率超过了一定的阈值,那么这幅图像就被认为是恶性肿块图像,否则就是正常图像。为了达到这个目标,损失函数该如何设计呢?
三、逻辑回归
对于一个原始图像I,我们可以得到经过多层卷积和池化后的一个很小的有着多通道(通道数为Nc)的feature map(F)。(F)i,j,:代表原图II中一个patch如Qi,j的CNN特征。可以看下面的公式: 我们的工作目标是预测整个乳房X线照片是否包含恶性肿块(BI-RADS ∈ {4,5,6}为阳性),这是一个标准的二元类分类问题。我们在F之后的所有像素位置上添加一个权重共享的逻辑回归,之后,采用sigmoid激活函数输出,那么特征空间像素(i,j)的恶性概率为
256个特征图经过logistic regression后会得到一个6x6的图,这个6x6图上的每个位置的值,对应了feature map相同位置的256个特征值经过逻辑回归后的值。最后其实这个6x6的图就是每个位置的评分值,评分的大小即每个位置恶性的概率。
四、损失函数
本文给出3种损失函数的计算方法,并给出比较。
损失函数常常是这种形式:ED (ω)是误差项,或是准确率的相反数;ER (ω)是正则化项,防止训练的过拟合。
1)最大值:Max Pooling-based Multi-instance Learning 基于最大池化多实例学习仅取得排名层中最大元素
对于传统的MIL假设,如果存在一个示例为positive,那么包为positive;如果所有示例为negative,那么包才为negative。在这个问题中,如果存在恶性肿块,那么就为恶性,只有所有部分都为良性,才为良性。所以positive示例实际上对应的恶性,negative示例对应的为良性。所以对于negative示例,我们希望所有的示例的riri都接近于0;对于positive示例,我们至少有一个示例接近与1。
对于基于最大池的学习,将得到6x6=36个概率值ri进行降序排列,整张图像 I的恶性可能性就是r排序中的第一位元素,如下面公式 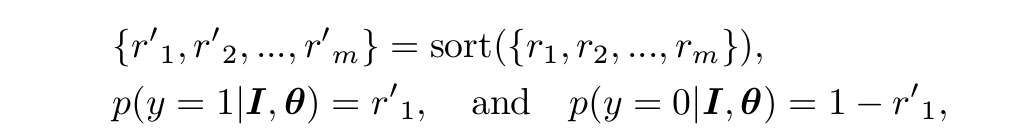
损失函数:基于交叉熵损失函数

其中N是乳房X线照片的总数,yn∈{0,1}是恶性肿瘤的真实标签,λ是控制模型复杂性的正规化器。
这个yn的真实标签是由上述概率求出来的,更倾向于后者,因为这篇文章做的是无标注的分类
通常,乳房X线照片数据集是不平衡的(例如,阳性的比例INbreast数据集的乳房X线照片约为20%)。 取而代之,我们介绍一个权重损失定义为:

其中,Wyn是训练集上yn的经验估计
我们只看ED (ω),这里是准确率的相反数。
当图像是恶性肿块图像,它被正确分类的概率就是它被认为是恶性肿块图像的概率,即为r1'。对于正常图像也同理可得。

对于这样的loss function,反复训练之后,将会出现:
对于正常图像,它被正确分类的概率是1-r1',经过训练,r1'越来越小。
因为r1'是最大值,r2',...,rm'也越来越小。于是正常图像上的所有patch被认为是恶性肿块的概率都越来越小,这就相当于给了图像中的每一个patch一个监督信号。这样在训练的过程中,就相当于将图像分成了一个个patch进行学习,大大增加了数据量。
对于恶性肿块图像,它被正确分类的概率是r1',经过训练,r1'越来越大。
因为r1'是最大值,r2',...,rm'并不会受到约束。于是可能存在一种情况,对于只有一个恶性肿块区域的图像,它的r1'=0.99,r2'=0.85,r2'也很大。这样虽然r2'对应的patch不是恶性肿块区域,它也被认为是恶性肿块区域,这就出现了监督信号的错误。
这种方法的缺点:只考虑了最大恶性可能的patch,并没有利用其他patch的信息。一个更加有效地框架应该增加与任务相关的先验,如整个乳房X线照片中的质量稀疏性,纳入一般多实例假设,并探索更多的训练patch。
2) 标签分配:Label Assignment-based Multi-instance Learning 基于标签分配的多实例学习利用所有元素,每个patch都分配标签。
我们将传统的多实例学习假设转换为标签设定问题。具体来说,提出了一个更高效的基于深度的多实例网络的标签分配
为了更好的发挥deep MIL的力量,作者将传统的MIL假设变成一个label assignment问题。不仅只考虑第一个patch的良性还是恶性,而是考虑排序后的前k个, 认为前k个是恶性肿瘤块而后面都是正常部分。
在多实例学习方案中,如果将每个实例(patch)Q i作为分类的一个数据点,则可以将多实例学习问题转换为标签分配问题。
第一种方法的问题是只考虑到最大概率的那个patch。对于正常图像,其它的patch虽然通过概率的大小排序有所约束;但是恶性肿块图像的其它patch都没被考虑到,导致了错误的监督信号的产生。
于是第二种方法想去考虑每一个patch,它不是对整幅图像赋予标签,而是给每个patch赋予标签。
对于正常图像,自然所有patch都是正常的,均赋予标签0;对于恶性肿块图像,本文认为其中有k个patch都是恶性肿块,而剩余的patch都是正常的。于是概率最大的k个patch的标签为1,其余patch标签为0。

loss function中是对一张图像上的所有patch的分类准确率进行加和。Q1',...Qm'是r1',…,rm'对应的patch。这样的话,每个patch都得到了考虑。但这里的问题是,这个k要怎么确定呢?要怎么知道每幅图像有多少个patch是肿块呢?答案是没办法确定,因为ground truth就只有整幅图像的标签。
在实验过程中,作者的做法是为k赋了一个常数值,所有图像的k都是一样的。这样肯定是不太好的,也有一些patch的监督信号是错的。但相比于第一种方法中,恶性肿块图像中大部分的patch得到了一个错误的监督信号,这里的情况已经有所改善了。

优点:基于标签分配的多实例学习的一个优点是它利用所有的patch来训练模型。 从本质上说,它是一种数据增强技术,当训练数据稀缺时,这是一种训练深度网络的有效技术。从稀疏性角度来看,基于标签分配的多实例学习的优化问题正是一个正数据点的k-稀疏问题,
缺点:这个相比第一种方法就是挖掘了所有块的信息来训练模型,但是难以确定k的取值。实验中,我们选择基于交叉验证的k
3)稀疏性: Sparse Multi-instance Learning 稀疏的多实例学习为排序层添加稀疏的元素约束
在说这个之前,作者对乳房X光照片进行了统计,统计了肿块区域大概占整个图像多少,看下图。 as a mass typically(特征斑块)===》我们进一步提出稀疏深度多实例网络这是基于最大池和基于标签分配的多目标优化之间的折衷多实例网络。
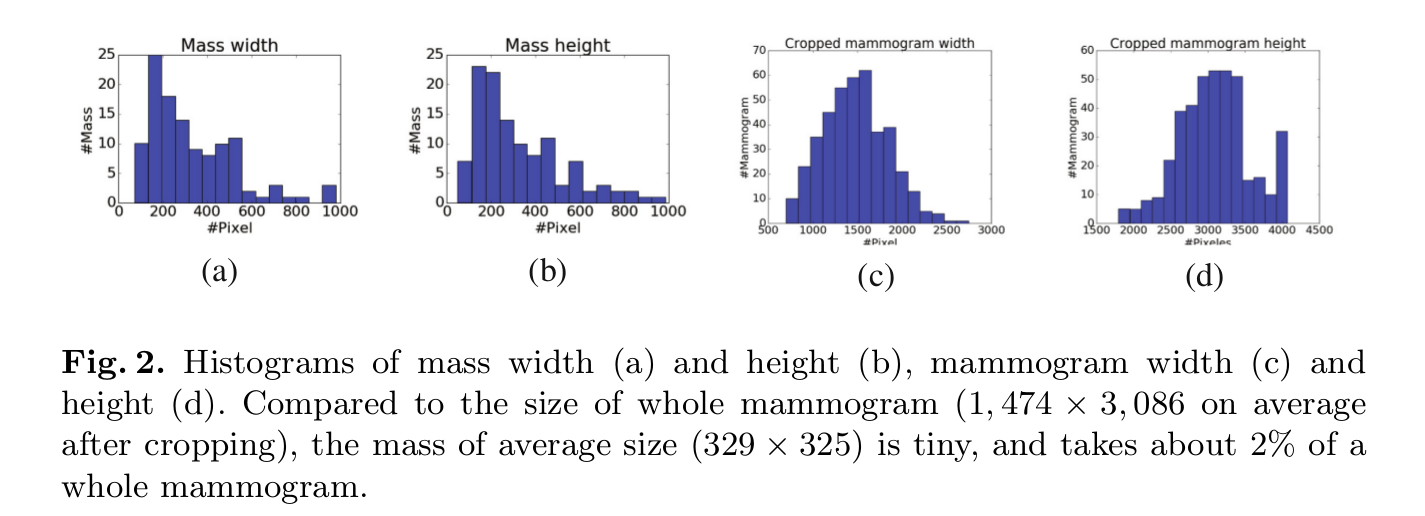
从质量分布来看,质量(mass)可以看出肿块区域大概占图像的2%,因此很多patch的那个r值要么为0,要么接近0。这意味着在整个乳房X线照片中mass区域相当稀疏,mass sparsity 转换到malignant mass sparsity,这意味着{r '1,r '2 …,r 'm }在整个乳房X线分类问题中是稀疏的。稀疏约束意味着我们期望部分patch r'i的恶性可能为0或接近0,同第二个假设标签分配一致
所以作者在第一种损失函数上加上了一个
|| · || 1表示 norm L1范数,μ是稀疏因子,这是稀缺之间假设和patch Q '1的重要性的权衡,计算公式如下

从基于标签分配的多实例学习的讨论来看,这种学习是一种精确的k-稀疏问题,可以转化为L 1约束.稀疏多实例学习在基于标签分配的多实例学习上的一个优点是,不需要为每个patch分配标签,而对于概率不太大或很小的补丁很难做到这一点。 稀疏多实例学习考虑r的整体统计特性
第三种方法,作者认为是第一种和第二种的tradeoff权衡,效果可以看之间的图,最后得到的结果也是最好的。最后作者比较了和以往方法在数据集的准确率和AUC,结果就不用说了,提升了。。。
本文提出了第三种方法,它综合了前两种方法的思路,也解决了它们各自的问题。相比方法一,方法三综合考虑了所有patch的信息,相比于方法二,方法三灵活地指出patch的个数。
可以发现,这个loss function跟第一种方法的差距就在 。与第一种方法相同的是,三用 考虑了最大概率的那个patch。那么它如何去考虑其他的patch呢?注意到一个先验知识,一幅图像中肿块是很少的,1块,2块,3块就算很多了,剩下的都是正常的乳腺组织。因此,在给每个patch赋予标签时,恶性肿块为1,正常为0,那么1的个数特别少,大部分都是0,因此这是一个稀疏问题。
于是加了 这一项,这是一个稀疏项。加了这一项之后,经过loss function去反复训练网络,那么最终得到的r就非常稀疏,r1',r2',...,rm'中只有几个有值,剩下的都是0。于是对于正常图像,它用 使得所有patch的概率值变小,并通过稀疏,使得大部分的概率接近于0,只有少数patch有较小的概率值,得到的都是正确的监督信号;对于恶性肿块图像,它用 使得最大概率值变大,同时通过稀疏,使得大部分patch的概率接近于0,只有少数patch有较大的概率值,这些较大的概率值就对应着恶性肿块区域,实现了数量的估计。
五、实验
对于预处理,我们首先使用Otsu的方法来分割乳房X线照片[18]和删除乳房X线照片的背景。为了接下来CNN的处理,我们将处理后的乳房X线照片调整为224×224。我们采用技术来增强我们的数据,对于每个训练时期,我们将乳房X线照片水平随机翻转,水平和垂直方向在乳房X线照片的0.1比例内转换,在45度内旋转,对于每个训练时期,我们将乳房X线照片水平随机翻转,水平和垂直方向在乳房X线照片的0.1比例内旋转,在45度内旋转,将50×50方框设为0。实验中,数据增加对我们训练深层网络至关重要。
对于CNN网络结构,我们使用AlexNet并删除完全连接层[13],通过CNN,尺寸为224×224的乳房X线照片变成了256个 6×6的featuremaps。然后我们使用第三部分中的步骤做多实例学习(MIL),我们使用Adam optimization ,从零开始训练的学习率为0.001,在Imagenet上预测,训练模型为最大池和基于标签分配的基于多示例学习的λ为
The λand µ for sparse multi-instance learning are 5×10 −6 and 1×10 −5 respectively。
对于基于标签分配深多实例的网络,我们选择K { 4,8,12,16 }基于验证集。

六.总结
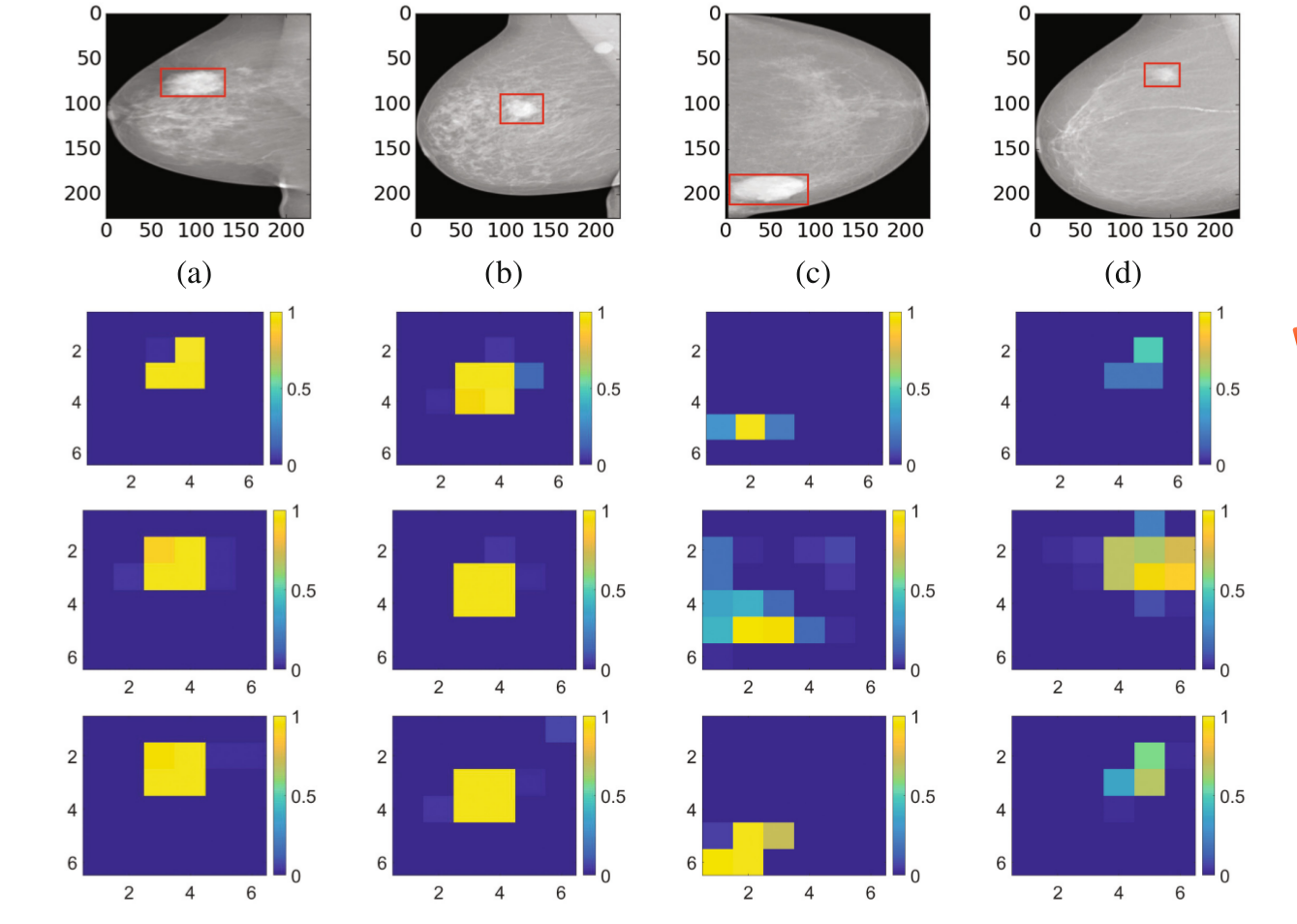
为了进一步了解我们的深度多实例网络,我们将图4中的四个乳房X线照片的线性回归层的响应可视化为测试集上的代表各个补丁的恶性概率的响应。

图4:在四个不同尺寸的乳房X线照片中显示预测恶性概率的实例/斑块。第一行是对乳房X线照片的大小调整。红色矩形框是来自数据集上注释的质量区域(mass regions)。从第二行到最后一行的彩色图像分别是从(a)到(d)的线性回归层的预测的恶性概率,其是斑块/实例的恶性概率。 基于最大池,基于标签分配,基于稀疏深度多实例网络分别位于第二行,第三行,第四行。(a),(c)和(d)中的最大的基于池的深度多实例网络丢失了一些恶性斑块。基于标签分配的深度多实例网络(d)中将斑块错分类为恶性。
从图4中我们可以看到深度多实例网络不仅学习了预测整个乳房X线照片,还可以预测整个乳房X线照片中的恶性斑块。我们的模型能够学习整个乳房X射线照片的质量区域,而不需要任何明确的boundingbox or segmentation ground truth 。(a),(c)和(d)中最大的基于池的深度多实例网络漏掉了一些恶性补丁。可能的原因是它只考虑训练中最大恶性概率的片段,并且对于所有的片都没有很好的学习。(d)中的基于标签分配的深度多实例网络错误地分类了一些补丁。可能的原因是,模型为所有乳房X线照片设置了一个常数k,这导致对于小质量的一些错误分类。我们工作的一个潜力就是这些深度多实例学习网络可以用来自动进行弱质量标注,这对于计算机辅助诊断是非常重要的。
七.讨论
在本文中,我们提出了对整个乳房X线照片分类的端到端训练的深度多实例网络。 与之前使用分割或检测注释的作品不同,我们直接进行基于整个乳房X线照片的质量分类。我们将一般多实例学习假设转换为排名后的标签分配问题。 由于质量的稀疏性,整个乳房X线照片分类采用稀疏多实例学习。实验结果表明,即使在训练中没有检测或分割注释,也比以前的工作有更强的性能。
在今后的工作中,有希望通过以下方式来扩展当前的工作:1)合并空间金字塔等多尺度建模,进一步改善整个乳房X线照片分类,2)自适应地估计基于标签分配的参数k多实例学习,3)采用深度多实例学习进行注释或提供潜在的恶性斑块来辅助诊断。
我们的方法应该普遍适用于需要领域专家知识和手工标记,或者感兴趣区域相对于整个图像小和/或稀疏的其他生物图像分析问题。我们的端到端深度多实例网络也适用于大型数据集,并且如果大型数据集可用,预计会有改进。