目的:本文是对韩松博士ICLR 2017论文 DSD:Dense-sparse-dense training for deep neural networks的详细解析。
论文地址:https://arxiv.org/pdf/1607.04381.pdf
代码地址:https://songhan.github.io/DSD.
目录
一、摘要
贡献点:
1.1 全新模型
提出了一个全新的DSD的训练流程,来使网络得到更好的训练。先Dense训练,获得一个网络权重;然后spars将网络剪枝,然后继续dense训练。从而获得更好的性能。
1.2 提升模型准确率
实验显示DSD在CNN,RNN,LSTM等图像分类、图像识别,语音识别等模型上都取得了很好的效果。
- 将GoogleNet的Top1 accuracy提升了 1.1%
- VGG-16提升了4.3%
- ResNet-18提升了1.2%
- ResNet-50提升了1.1%
1.3. 易于实施
DSD易于实施,只在S阶段引入一个超参数,其他阶段也更易实现。
二、方法
2.1 区别
与dropout的区别
虽然都是在训练过程中有prune(剪枝)操作,但是DSD是有一定依据来选择去掉哪些connection,而dropout是随机去掉
与模型压缩的区别
DSD的目的是提升准确率,不能带来模型的精简。
2.2 算法流程


D:将网络正常训练,获得相应的权重
S:将网络剪枝,将小于某值的权重去掉,然后继续训练。
D:将剪枝的权重恢复为0,重新训练网络。
2.3 相应权重的变化

(a)上图为权重的直方图。我们看到第一次Dense训练之后,权重分布都有,且在各处分布
(b)将绝对值小于某值的权重删除掉,我们看到某绝对值一下的权重都没有了
(c)进行sparse训练,我们看到边缘变得平滑。
(d)恢复剪枝的权重,全部置为0。则0值有一个高峰。
(e)再次进行训练,权重各处都有分布。
2.4 具体流程及解释
Initial Dense Training
即普通神经网络的训练方法,但此步的目的是1.学出权重的值 2.学出哪些权重更重要(绝对值越大则权重越重要)。
Sparse Training
按比例将小于某绝对值权重值的值置为0。
进行剪枝的数学推导:
![]()
假定我们有一个loss,loss受到权重值的影响,是权重值的函数。
权重值变化会带来Loss值的变化:
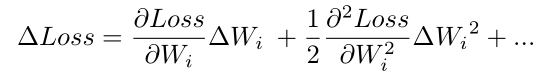
所以权重值越小,则置为0带来的权重的变化越小,Loss值的变化也越小。
Final Dense Training
恢复被剪枝的权重置为0,重新训练。
三、实验

各个数据集上均带来了性能的提升。DSD取得了最好的效果(字体颜色加深)。
- Abs .Imp.为绝对提升,即与baseline的对比,
- Rel .Imp.是相对的提升,与剪枝之后的神经网络进行对比得到的提升。(此处存疑,但是基本认为是与刚刚剪枝之后,没有进行sparse训练的对比)

- LLR 为降低学习率,网络收敛更慢但是得到的局部极小值更好。
- 我们可以看出DSD取得了最小的Error。

分别在VGG,ResNet,NeuralTalk数据集上,均取得了很好的效果。





四、讨论与原理
DSD带来了准确率的提升,作者进行了下面这些讨论:
跳过了鞍点(Saddle Point)

鞍点:鞍点(Saddle point)在微分方程中,沿着某一方向是稳定的,另一条方向是不稳定的奇点,叫做鞍点。在矩阵中,一个数在所在行中是最大值,在所在列中是最小值,则被称为鞍点。在物理上要广泛一些,指在一个方向是极大值,另一个方向是极小值的点。
鞍点梯度接近于0,模型接近于收敛。但是剪枝的过程跳过了这些点。
更好的局部极小值(Better Minima)
低权重置为0就获得了更好的局部极小值。(对此作者没有具体解释)
正则化与稀疏训练
稀疏的正则化将模型拉到了更低的维度,因此可以对于噪声更加鲁棒。
鲁棒的再次初始化
普通的模型只初始化一次,但是DSD进行了两次(或更多)的权值初始化。这里作者给出了一个猜想,作者采用的是0值初始化的方法,其他的初始化方法值得尝试。
打破了对称性(Symmetry)
剪枝能破坏权值的对称性,所以获得更好的训练。(此处不明意义,作者未给出详尽解释,我对于symmetry的理解不够好。贴出原文)
Break Symmetry: The permutation symmetry of the hidden units makes the weights symmetrical,thus prone to co-adaptation in training. In DSD, pruning the weights breaks the symmetry of the hidden units associated with the weights, and the weights are asymmetrical in the final dense phase.