最近正在痛苦改论文中…还没投出去, 心情糟糕 所以不如再做一点笔记…
论文题目: Adaptive Sparse Convolutional Networks with Global Context Enhancement for Faster Object Detection on Drone Images
论文地址: 论文
代码地址: 代码
这是一篇CVPR2023的文章, 是无人机数据集的小目标检测. 文章针对小尺寸目标造成的上下文信息不足, 以及稀疏卷积在多尺度下mask比例难以控制的问题, 提出了一种新的方法以平衡精度与速度.
本篇博客在记录技术细节的同时, 也想分析一下写作.
0. Abstract
题目当中有三个关键词, 对应了本篇文章的三个关键点: Adaptive, Global和Faster. 作者针对小目标检测的稀疏卷积的问题, 做出了两个改进: 自适应mask比例, 和上下文增强.
第一句: 背景+意义. 强调UAV下的目标检测很重要, 速度也很重要.
第二句: 引出本篇论文的研究对象, 即稀疏卷积. 稀疏卷积可以平衡精度与速度.
第三句: 针对的问题: 现在稀疏卷积存在的问题: 小目标情况下上下文信息的不充分+不同尺度下mask比例难以控制.
第四句:本文propose了什么, 针对问题1是如何做的, 问题2是如何做的. 针对小目标上下文信息不充分, 将传统稀疏卷积的稀疏特征采样改成了一个可以学习全局信息的采样方式. 针对mask比例难以控制的问题, 提出了一个新的策略.

(这部分不用说的过于技术化, 也可以从道理上说明即可, 也就是, 是怎么做的, 尽量可解释地说出这样直观上为什么好. 这里只说替换成global context ones, 可以大体说是如何做的, 于是就能达到global的效果了).
第五句: 数据集+实验效果. 可以定性说, 也可以定量说.
1. Introduction
第一段: 背景+意义. 将摘要第一句展开即可.
第二段: 介绍一个大主题: 速度-精度平衡的目标检测, 从而引出稀疏卷积. 早期的工作(例如RetinaNet)中, detection head占了很大的计算量. 为了降低计算量, 一些算法用模型剪枝蒸馏或干脆改进模型结构. 然而前者会造成性能的下降, 而后者一般只适用于低分辨率输入.
第三段: 稀疏卷积的引出, 现存的问题. 稀疏卷积通过可学习的mask降低计算量. 因此对于稀疏卷积, 采样区域的选取尤为重要. 然而, 如Fig. 1所示, 对于通用目标检测, 前景的比例是比较大的, 然而无人机场景前景的比例比较小.
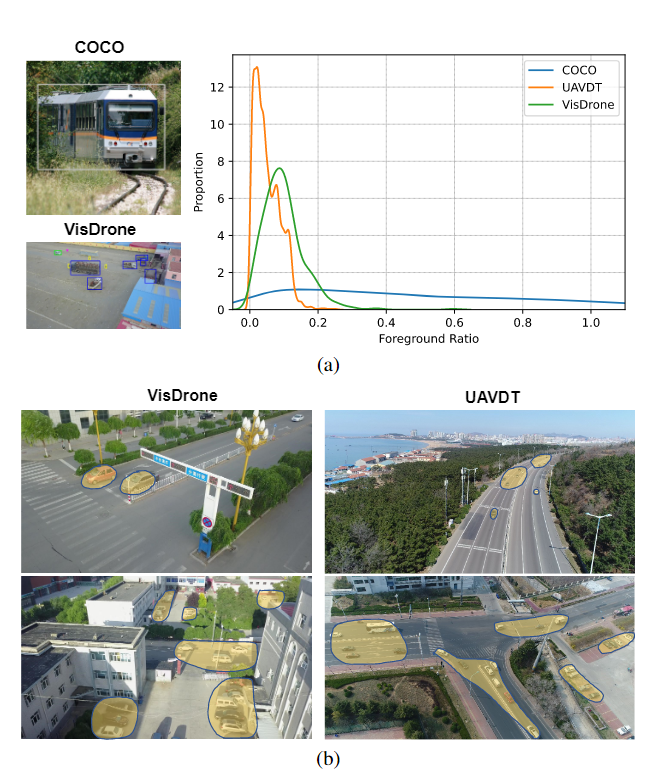
一般来讲, Fig. 1能够直观地叙述工作的Motivation的基础或突出的background.
之前的一些方法, 例如QueryDet, 也使用了稀疏卷积, 然而他们往往是增加了一些额外分支, 然后采用稀疏卷积降低计算量, 并没有对稀疏卷积如何应用于UAV做进一步的探索.
引言的中间部分, 主要说文章针对的问题, 别人是否解决. 如果别人也在解决, 有什么不足. 别人没解决, 是如何忽视的.
第四段: 这篇文章具体是如何做的. 本文就是按照摘要的那几句展开说了一下.
第五段: main contribution. 这部分分条列出:
- (总体) 本文提出了CEASC, 是针对稀疏卷积的改进
- (网络每一部分针对的问题, 做法) 本文提出了一个基于上下文的稀疏卷积层, 并且设计了一个自适应mask ratio的策略.
- (数据集效果)
(Optional)第六段: 论文剩余部分的组织
2. Related Work
Related Work的写法见仁见智.
- 可以按照范式分类. 比如目标检测, 可以按照one-shot, two-stage. MOT, 可以按照tracking-by-detection, joint detection and tracking.
- 当工作是多个任务的叠加, 可以按照任务来写. 例如QuoVadis是将MOT和trajectory prediction融合在一起, 则可以组织为A. MOT, B. trajectory prediction
- 如果可以避免和Introduction中高度重复, 可以按照针对的问题写. 这时就写别人是如何做的.
本文的思路偏于第2种. 由于整个文章的基调是UAV detection的efficiency-accuracy balance, 所以先介绍通用目标检测, 再介绍UAV目标检测, 再介绍以快速为主的目标检测方法.
3. Method
Method只要按照如何做的一步一步解就行了.
3.1. 上下文增强的稀疏卷积
3.1.1. 稀疏卷积
稀疏卷积解决的是detection head需要全图搜索而造成计算量过大的问题, 其采用一个mask筛选只需要卷积的前景区域. 具体地, 对于一个特征图 X ∈ R B × C × H × W X\in \mathbb{R}^{B\times C \times H \times W} X∈RB×C×H×W, 首先生成一个mask. 该mask是通过通道数为1的 3 × 3 3\times 3 3×3卷积层实现的. 于是得到新的feature S ∈ R B × 1 × H × W S\in \mathbb{R}^{B\times 1 \times H \times W} S∈RB×1×H×W. 我们将 S S S进行二值化, 得到mask矩阵 H ∈ { 0 , 1 } B × 1 × H × W H\in \{0, 1\}^{B\times 1 \times H \times W} H∈{ 0,1}B×1×H×W.
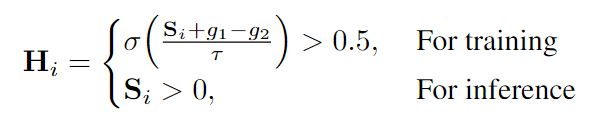
其中 g 1 , g 2 g_1, g_2 g1,g2为随机的gunbel噪声, τ \tau τ为一个参数, σ \sigma σ为sigmoid函数. H i H_i Hi的稀疏性是用1所占的比例来衡量的. 通常在已有的工作中比例大于 0.9 0.9 0.9.
3.1.2. 上下文增强
稀疏卷积没有关注背景信息. 为了解决这个问题, 作者又对特征图 X i X_i Xi, i i i表示FPN的层数, 额外进行一个全图的point-wise卷积(我的理解应该是1x1卷积), 得到 G i G_i Gi.
那么如何用 G i G_i Gi去补偿稀疏卷积丢掉的信息呢? 作者采用了一个group normalization的方式:
L i = S p a r s e C o n v ( X i ) F i = w × L i − m e a n [ G i ] s t d [ G i ] + b L_i = SparseConv(X_i) \\ F_i = w \times \frac{L_i - mean[G_i]}{std[G_i]} + b Li=SparseConv(Xi)Fi=w×std[Gi]Li−mean[Gi]+b
最终用残差连接作为最终的 F i F_i Fi:
F i + = G i F_i += G_i Fi+=Gi
这里有个疑问
- 作者说point-wise的卷积在多轮SC后会趋于稳定所以会降低计算量, 是因为特征图 X i X_i Xi的很少的元素才会被处理. 首先卷积操作是客观存在的, 每次推理都会经过, 所以不论数值上是否稳定, 计算量应该都是增加了的. 此外, 前面说稀疏卷积的mask比例都很大, 为什么还说是few elements?
在训练阶段, 为了进一步减少稀疏卷积的损失, 作者又增加了一个正常的Conv层作用于二值化mask H H H, 并且目标是缩小其与group norm后得到的 F F F的差距:
L n o r m = 1 4 L ∑ i = 1 L ∑ j = 1 4 ∣ ∣ C i , j × H i − F i , j ∣ ∣ \mathcal{L}_{norm}=\frac{1}{4L}\sum_{i=1}^L \sum_{j=1}^4||C_{i,j}\times H_i-F_{i,j}|| Lnorm=4L1i=1∑Lj=1∑4∣∣Ci,j×Hi−Fi,j∣∣
其中 j j j表示Sparse Conv layer的层索引.
3.2. 自适应的多层mask
前面说, mask ratio的阈值过高会导致计算量大, 过低会导致效果不行. 为了balance这两个, 需要一个动态的阈值.
那么如何动态呢, 作者采取的方式很直接. 只需要让输出的mask矩阵 H i H_i Hi的1的比例接近于真值就可以了. 比如, 对于FPN的第 i i i层, 假设真值为 C i ∈ R h i × w i × c i C_i\in\mathbb{R}^{h_i\times w_i\times c_i} Ci∈Rhi×wi×ci. 我们将feature map中前景的比例视为我们要优化的目标:
P i = P o s i t i v e ( C i ) h i w i P_i = \frac{Positive(C_i)}{h_iw_i} Pi=hiwiPositive(Ci)
于是损失函数为
L a m m = 1 L ∑ i ( P o s i t i v e ( H i ) N u m O f P i x e l s ( H i ) − P i ) 2 \mathcal{L}_{amm}=\frac{1}{L}\sum_i(\frac{Positive(H_i)}{NumOfPixels(H_i)}-P_i)^2 Lamm=L1i∑(NumOfPixels(Hi)Positive(Hi)−Pi)2
最终的loss为二者的线性和.
因此, 总体框图如下:

4. 实验
这篇文章的实验很充分, 包括各部分的消融实验, 以及计算量对比, 特征图可视化等.