在目标检测中,为了与NMS兼容,一个好的检测器应该能够预测具有较高分类得分和精确位置的box。然而,如果所有的训练样本都被同等处理,两个头部之间就会出现错位:类别得分最高的位置通常不是回归对象边界的最佳位置。这种失调会降低检测器的性能,特别是在高IoU指标下。soft label assignment是通过加权损失以软标签的方式处理训练样本,试图增强cls和reg头之间的一致性。
今天介绍的这篇论文是从loss权重入手,提出了DW label assignment,更加细粒度的构建Wneg,Wpos,从而帮助网络更好的提高cls与iou的一致性。
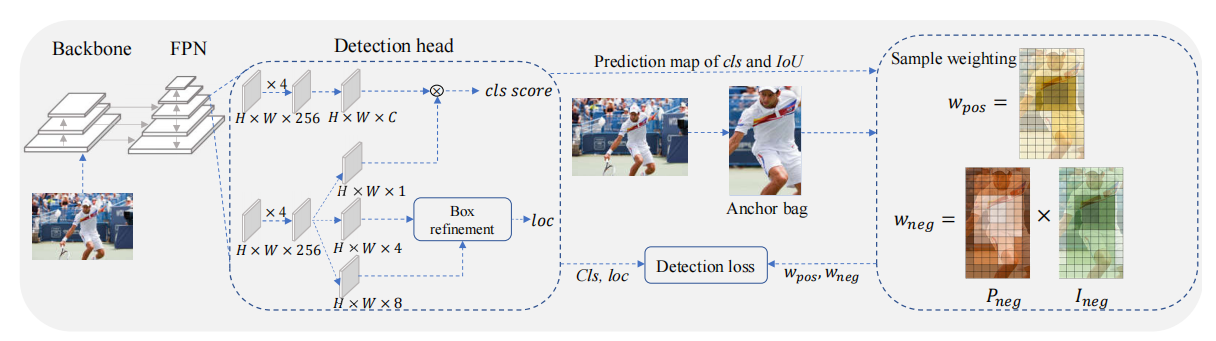
Motivation and Framework
该论文的思路比较简单,作者认为cls高的anchor,iou也应该高,而iou低的anchor,其cls也应随之变低,这样保持cls与iou高度一致,经过NMS后输出的box能够具备最优IOU。而之前的论文,都在强调正样本点在loss中的权重,通过Wpos在iou与cls中分别加权,影响得分,但是正样本点存在iou较低的情况,因此,作者认为需要更加细粒度的设计Wneg,降低这些正样本点的cls得分。
为此作者设计了Positive Weighting Function,Negative Weighting Function,Box Refinement,以及正样本选择的方法。
Proposed Method
1.Positive Weighting Function
高cls得分和高IoU是pos预测框的充分必要条件。这意味着同时满足这两个条件的锚点在测试过程中更有可能被定义为pos预测框,因此它们在训练过程中应该具备更高价值。从这个角度来看,Wpos应该与IoU和cls的排名得分呈正相关,作者首先定义一致性度量,公式如下所示:
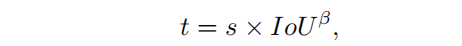
其中S表示cls得分,IOU表示预测的reg与GT的IOU, β \beta β用来平衡两者,鼓励不同anchor之间Wpos的差异。
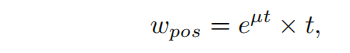
其中,µ是一个控制不同pos权重的相对间隙的超参数。
p_loc = torch.exp(-reg_loss*5)
p_cls = (cls_score * objectness)[:, gt_labels]
p_pos = p_cls * p_loc
p_pos_weight = (torch.exp(5*p_pos) * p_pos * center_prior_weights) / \
(torch.exp(3*p_pos) * p_pos * \
center_prior_weights).sum(0, keepdim=True).clamp(min=EPS)
代码如上,reg_loss是iou的loss,reg_loss=1-iou,p_loc是e为底的指数,当reg_loss趋于0时(即iou趋于1),p_loc趋向于1,表示该anchor回归的好, β \beta β设置为5。p_pos即论文中的t,p_pos_weight是Wpos,center_prior_weights表示正样本点,代码中对每个类别设置了高斯核,并将instance的gt带入,这个每个anchor可以获得得分,越靠近GT中心的分数越高并呈高斯衰减,但高斯核是常数,无法学习。center_prior_weights在GT内部的anchor都会有得分,与fcos不同的是,center_prior_weights是soft的。此外,代码还对Wpos做了归一化的操作,(torch.exp(3*p_pos) * p_pos * center_prior_weights).sum(0, keepdim=True),对每个gt进行求和(原因未知,可能适当提高Wpos效果更好)。
2.Negative Weighting Function
作者认为虽然Wpos可以强制锚点具有高的cls分数和大的IoUs,但Wpos无法区分anchor的不一致程度。为了提供更多鉴别监督信息,作者提出Probability of being a Negative Sample和Importance Conditioned on being a Negative Sample更细粒度的给出Wneg。
-
Probability of being a Negative Sample
具有较高cls得分的box可能会因为IOU变成误检,coco采用了0.5~0.95的IOU区间来估计AP,因此Pneg应该满足以下规则。
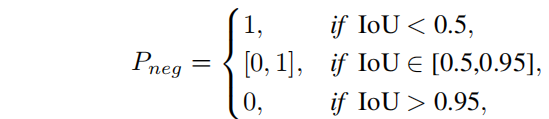
任何单调递减函数都适用于Pneg,为了简单,作者将Pneg的func采用如下公式,
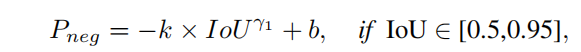
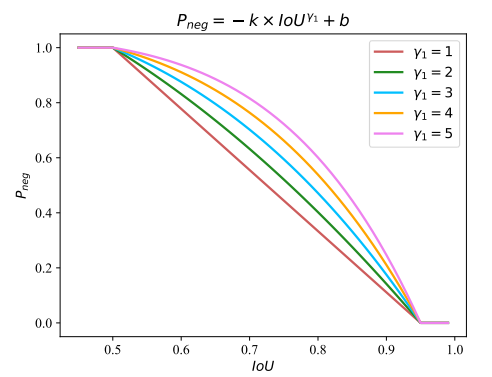
该公式通过(0.5,1)和(0.95,0)两个点,即当IOU<0.5是,Pneg=1,IOU>0.95,Pneg=0.如下图所示。
-
Importance Conditioned on being a Negative Sample
排名得分较高的neg预测框比排名得分较低的neg预测框更重要,因为它们是网络优化的困难样例。因此,用Ineg表示的neg样本的重要性应该关于cls得分的函数,Ineg公式如下
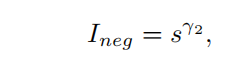
其中 γ 2 \gamma^2 γ2表示应该基于多少优先考虑因素,最终Wneg如下公式所示,Wneg=Ineg * Pneg
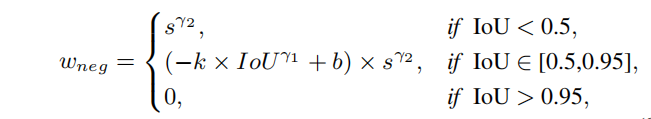
具体代码如下,t表示的公式是上图公式的第二行,其中k,b分别为1.33, γ 2 = 2 \gamma2=2 γ2=2,需要对每个GT进行normalize,将所有anchor与该GT的iou通过t算出x_,找到x_最小与最大值t1,t2,将x_归一化得y,目的是加大x_之间的间隔,更均匀的分布于0-1之间。最后在乘上 s γ 2 s^{\gamma2} sγ2。
alpha = 2
t = lambda x: 1/(0.5**alpha-1)*x**alpha - 1/(0.5**alpha-1)
if num_gts > 0:
def normalize(x):
x_ = t(x)
t1 = x_.min()
t2 = min(1., x_.max())
y = (x_ - t1 + EPS ) / (t2 - t1 + EPS )
y[x<0.5] = 1
return y
for instance_idx in range(num_gts):
idxs = inside_gt_bbox_mask[:, instance_idx]
if idxs.any():
neg_metrics[idxs, instance_idx] = normalize(ious[idxs, instance_idx])
foreground_idxs = torch.nonzero(neg_metrics != -1, as_tuple=True)
p_neg_weight[foreground_idxs[0],
gt_labels[foreground_idxs[1]]] = neg_metrics[foreground_idxs]
p_neg_weight = p_neg_weight.detach()
neg_avg_factor = (1 - p_neg_weight).sum()
p_neg_weight = p_neg_weight * joint_conf ** 2
neg_loss = p_neg_weight * F.binary_cross_entropy(joint_conf, torch.zeros_like(joint_conf), reduction='none')
neg_loss = neg_loss.sum()
3.Box Refinement
为了更好的回归框坐标,作者设计了一个可学习预测模块为每条边生成偏移点,利用偏移点精修坐标。代码中,reg_feat是回归特征,利用reg_offset卷积生成reg_offset特征,尺寸为(b,h,w,8),与bbox_pred_d组成4个偏移点,并将decoded_bbox_preds与reg_offset送入deform_sampling。deform_sampling是可变形卷积,但是可变形卷积的weight是常数,所以这里只起到差值作用。
def deform_sampling(self, feat, offset):
## 这里其实只是一个双线差值操作,没有参数可以优化,为了使feat沿着offset方向偏移。
##参数x为输入:形状为(N,Cin,Hin,Win);offset为可变形卷积的输入坐标偏移:形状为 (N,2∗Hf∗Wf,Hout,Wout);weight为卷积核参数:形状为(Cout,Cin,Hf,Wf)
b, c, h, w = feat.shape
weight = feat.new_ones(c, 1, 1, 1)
y = deform_conv2d(feat, offset, weight, 1, 0, 1, c, c)
return y
if self.with_reg_refine:
reg_dist = bbox_pred.permute(0, 2, 3, 1).reshape(-1, 4)
points = self.prior_generator.single_level_grid_priors((h,w), self.strides.index(stride), dtype=x.dtype, device=x.device)
points = points.repeat(b, 1)
decoded_bbox_preds = distance2bbox(points, reg_dist).reshape(b, h, w, 4).permute(0, 3, 1, 2)
reg_offset = self.reg_offset(reg_feat)
bbox_pred_d = bbox_pred / stride
reg_offset = torch.stack([reg_offset[:,0], reg_offset[:,1] - bbox_pred_d[:, 0],\
reg_offset[:,2] - bbox_pred_d[:, 1], reg_offset[:,3],
reg_offset[:,4], reg_offset[:,5] + bbox_pred_d[:, 2],
reg_offset[:,6] + bbox_pred_d[:, 3], reg_offset[:,7],], 1)
bbox_pred = self.deform_sampling(decoded_bbox_preds.contiguous(), reg_offset.contiguous())
bbox_pred = F.relu(bbox2distance(points, bbox_pred.permute(0, 2, 3, 1).reshape(-1, 4)).reshape(b, h, w, 4).permute(0, 3, 1, 2).contiguous())
Ablation study
