多示例学习(multi-instance learning)
本科毕业答辩结束!这个系列主要分享一些Miccai这一医学影像分析顶级会议上论文~
为什么讲这个?
看到了miccai2017年的一篇挺有意思的论文,所以查阅了相关研究资料,分享给大家。
什么是多示例学习?
这方面国内的大牛周志华是领域翘楚,大家有兴趣可以看看他之前的相关工作。下面的部分摘自他的一个survey性质的文章。
周志华survey
在多示例学习中,训练样本是由多个示例组成的包,包是有概念标记的,但示例本身却没有概念标记。如果一个包中至少包含一个正例,则该包是一个正包,否则即为反包。
与监督学习相比,MIL中的训练示例是没有概念标记的,这与监督学习中所有训练示例都有概念标记不同;与非监督学习相比,MIL中的训练包是有概念标记的,这与非监督学习的训练样本中没有任何概念标记也不同。
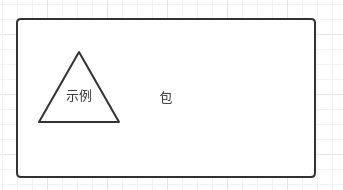
在以往的各种学习框架中,一个样本就是一个示例,即样本和示例是一一对应的关系;而在MIL中一个样本(即包)包含了多个示例,即样本和示例是一对多的对应关系。因此这是一种新的学习框架。
Miccai论文
那么Miccai论文是怎么应用这个多示例学习呢?先介绍整个论文是在干嘛?
论文是对Mammogram乳房X光照片进行分类用来计算机辅助检测乳腺癌,传统的做法依赖于ROI(Regions of Interest)的获取,即需要detection然后segementation最后再进行classification。这有两个缺点:
- 依赖于人为设计的特征,以及groundtruth
- 不是end-to-end
那么这篇论文是怎么解决的呢?
它是基于原始整个乳房X光图片进行分类。它将每个乳房X光照片的patch看做示例,将整个乳房X光照片看做a bag of instances即上面说的包。那么这个分类问题可以看做是标准的MIL问题。
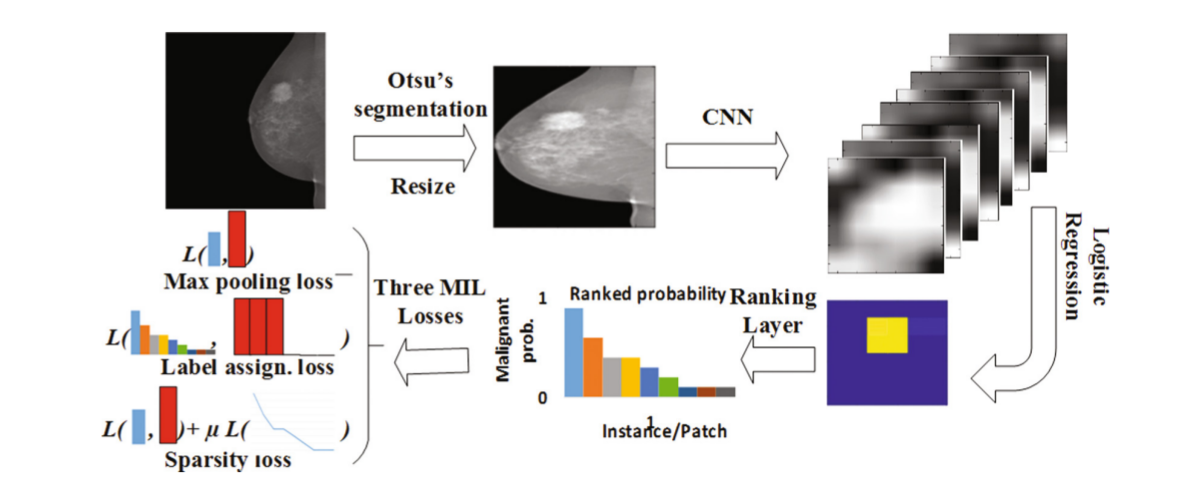
上图就是整个乳房X照片分类的流程图。
- 首先使用大津方法(类内方差最小,类间方差最大)来移除背景同时resize到227*227
- 使用AlexNet中的卷积层,提取它最后一个卷积层的特征。最后会得到6*6*256的feature map
- 对CNN中的feature map进行基于恶性(当确定为恶性是为1)不同patch之间权值共享的logistic regression,然后将response进行rank。
- 最后学习的损失由三种不同的模式进行计算,分别是max pooling loss, label assignment, sparsity loss.
Deep MIL细节
逻辑回归
对于一个原始图像
,我们可以得到经过多层卷积和池化后的一个很小的有着多通道(通道数为
)的feature map(F)。
代表原图
中一个patch如
的CNN特征。可以看下面的公式:
。
256个特征图经过logistic regression后会得到一个6x6的图,这个6x6图上的每个位置的值,对应了feature map相同位置的256个特征值经过逻辑回归后的值。最后其实这个6x6的图就是每个位置的评分值,评分的大小即每个位置恶性的概率。
Max Pooling-Based Multi-instance Learning
对于传统的MIL假设,如果存在一个示例为positive,那么包为positive;如果所有示例为negative,那么包才为negative。在这个问题中,如果存在恶性肿块,那么就为恶性,只有所有部分都为良性,才为良性。所以positive示例实际上对应的恶性,negative示例对应的为良性。所以对于negative示例,我们希望所有的示例的
都接近于0;对于positive示例,我们至少有一个示例接近与1。
对于基于最大池的学习,将得到6x6=36个概率值
进行降序排列,如下面公式
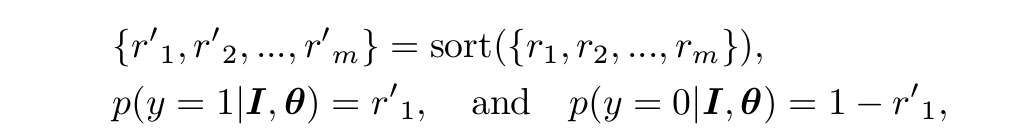
损失函数即为
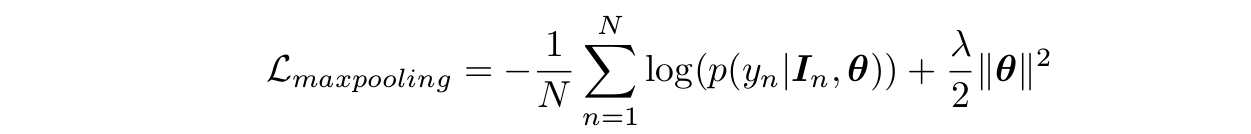
这种方法的缺点是只考虑了最大恶性概率的块,没有挖掘其他块的信息。可以看出它的损失函数与
都无关,它不会约束其他块的判断。
Label Assignment-Based Multi-instance Learning
为了更好的发挥deep MIL的力量,作者将传统的MIL假设变成一个label assignment问题。不仅只考虑第一个patch的良性还是恶性,而是考虑排序后的前k个, 认为前k个是恶性肿瘤块而后面都是正常部分。
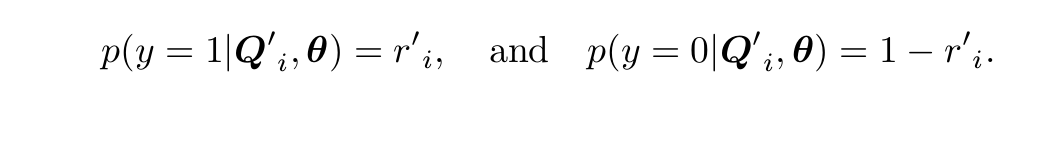
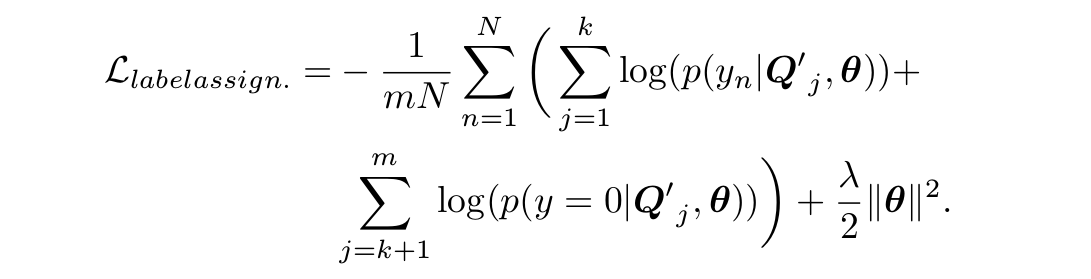
这个相比第一种方法就是挖掘了所有块的信息来训练模型,但是难以确定k的取值。
Sparse Multi-instance Learning
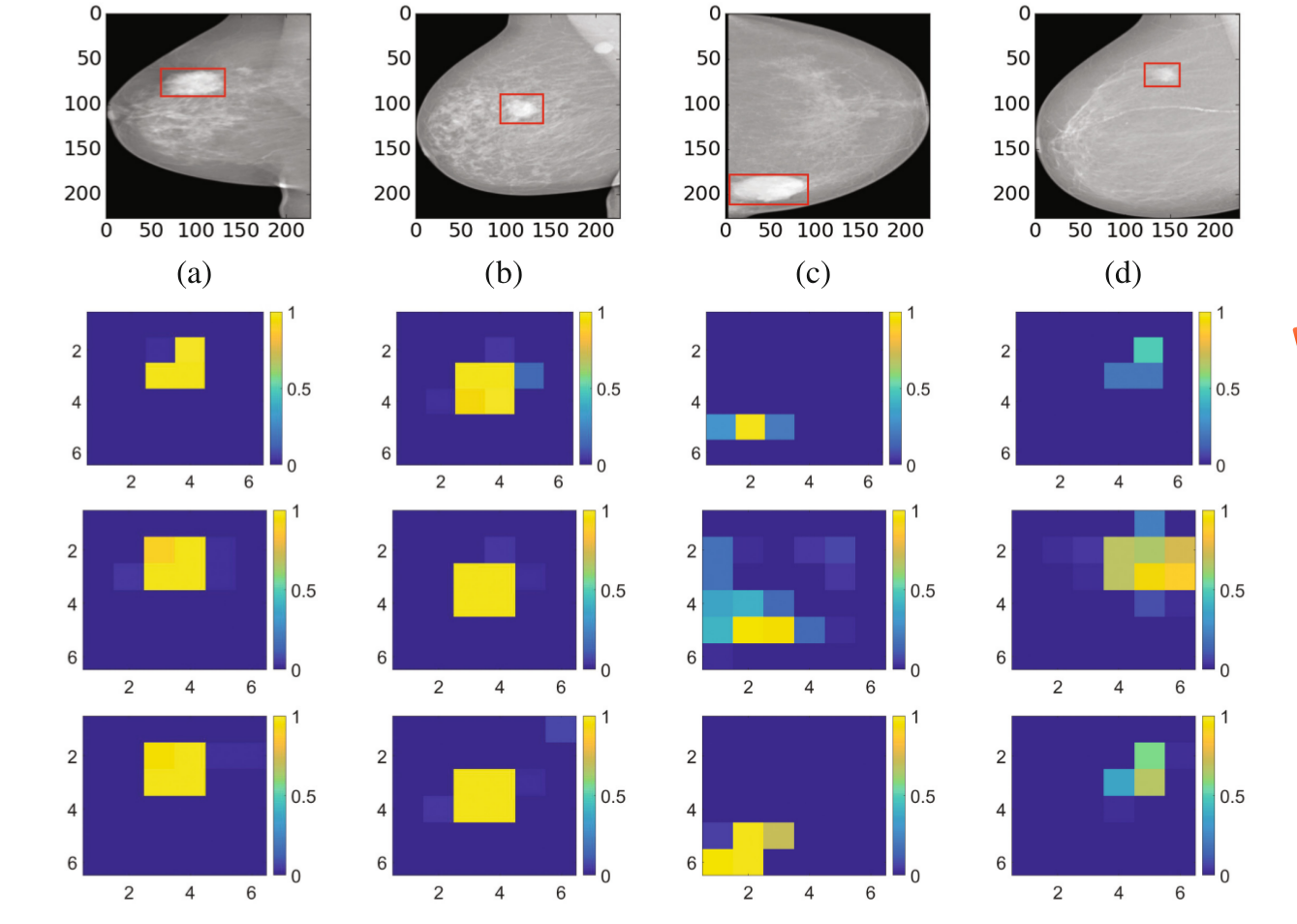
在说这个之前,作者对乳房X光照片进行了统计,统计了肿块区域大概占整个图像多少,看下图。
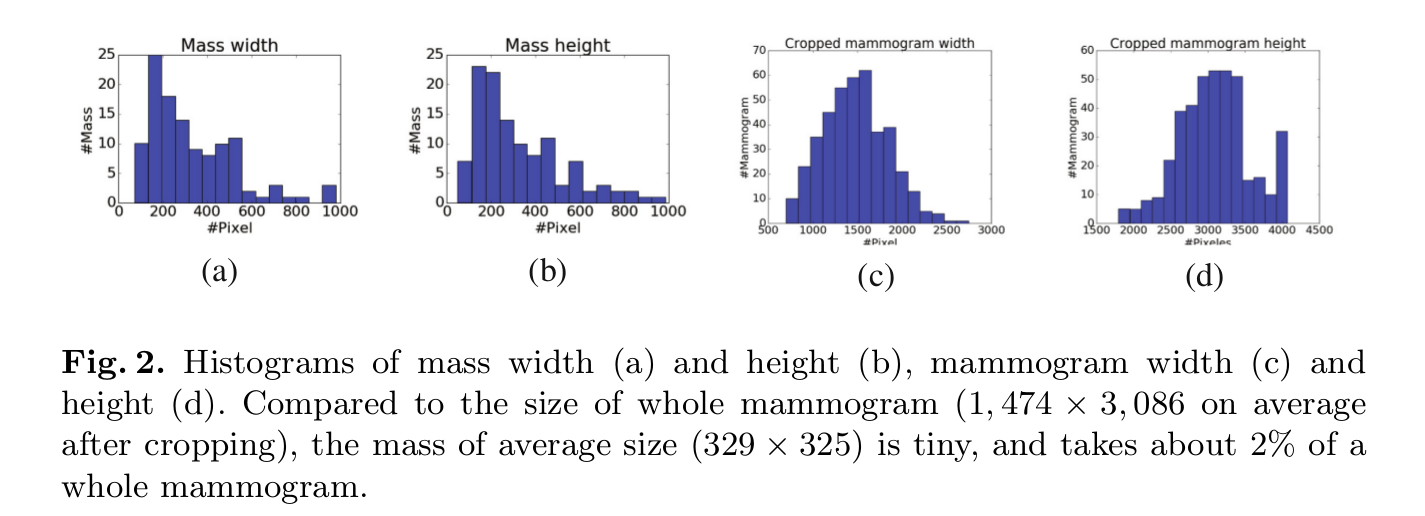
可以看出肿块区域大概占图像的2%,因此很多patch的那个
值要么为0,要么接近0。所以作者在第一种损失函数上加上了一个L1范数,
是稀疏因子,这个是稀疏假设和第一种方法的tradeoff,计算公式如下:
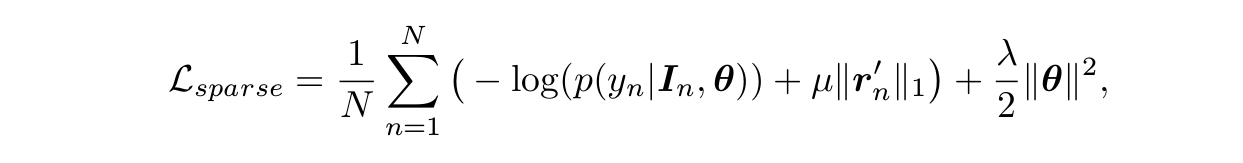
第三种方法,作者认为是第一种和第二种的tradeoff,效果可以看之间的图,最后得到的结果也是最好的。最后作者比较了和以往方法在数据集的准确率和AUC,结果就不用说了,提升了。。。