论文地址:Data-Driven Sparse Structure Selection for Deep Neural Networks
代码地址:Pytorch,MXNet,Tensorflow
论文总结
本文是结构化裁剪模型的一种方法。其引入额外的尺度因子 λ \lambda λ来对不同维度的输出进行自适应训练(即Data-Driven的意思),通过对尺度因子进行稀疏化约束,得到可以安全裁剪的对象。
作者把本文方法认为是一次到底的,即不需要再retrain的,只裁剪对应尺度因子为0的结构。
尺度因子对应的结构可以是block,也可以是一组卷积group,甚至单个神经元neuron。

从论文的实验结果来看,其裁剪相对于原网络是有损失的,且裁剪出来的压缩率不高。
论文介绍
有观点提出,ResNet是很多浅层网络的指数集合,移除(某些)单个residual block对性能影响很小。所以作者也将裁剪的对象放在了block层面上。
损失函数部分,除了正常的网络损失,还需要对尺度因子 λ \lambda λ进行稀疏化约束,常见的方法为添加 L 1 L_1 L1正则化约束。在训练的时候,作者对优化方法APG进行了改进,不咋能见到这东西,就不讲了。
作者认为,与Network Slimming的裁剪方法相比,本文的方法更有效与通用。原因为:(1)使用额外的尺度因子比复用BN层参数更加普遍;这是因为① 有一些网络没有BN层参数,比如VGGNet和AlexNet;② 在使用预训练模型微调适应目标检测/语义分割任务时,BN层参数因为较小的batch size通常是固定不变的。(2)Network Slimming的优化是启发性的,需要多次迭代和再训练。而本文的方法通过额外的尺度因子直接将输出置零了,是一次端到端的训练即可完成的。所以,作者认为Network Slimming是本文的特例。
如论文总结的图所示,使用 λ \lambda λ在不同的输出后面,即可对不同的对象进行裁剪的自适应训练,对象可以为block、group、neuron。
论文实验
CIFAR数据集
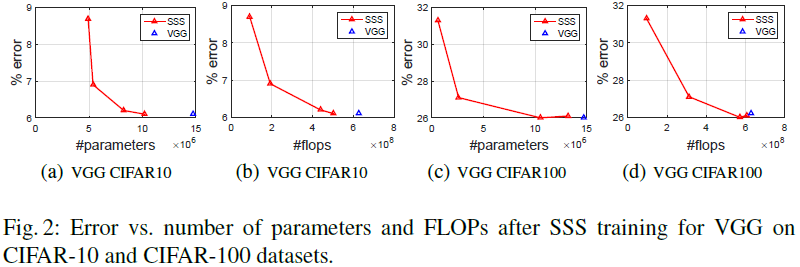
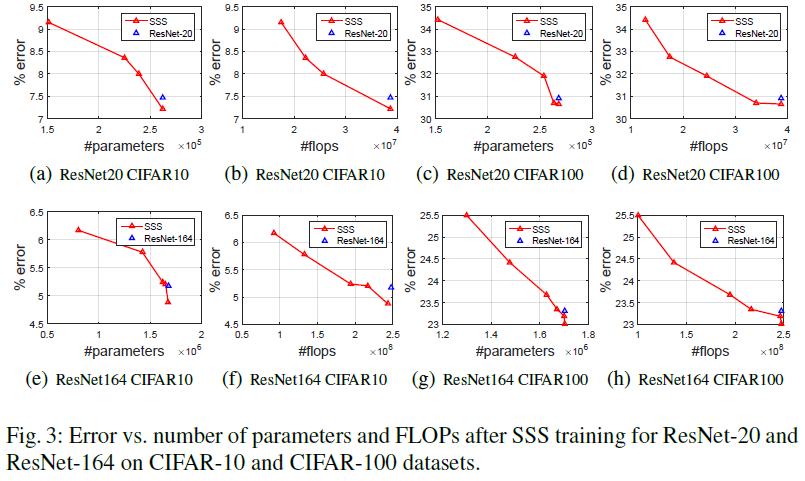
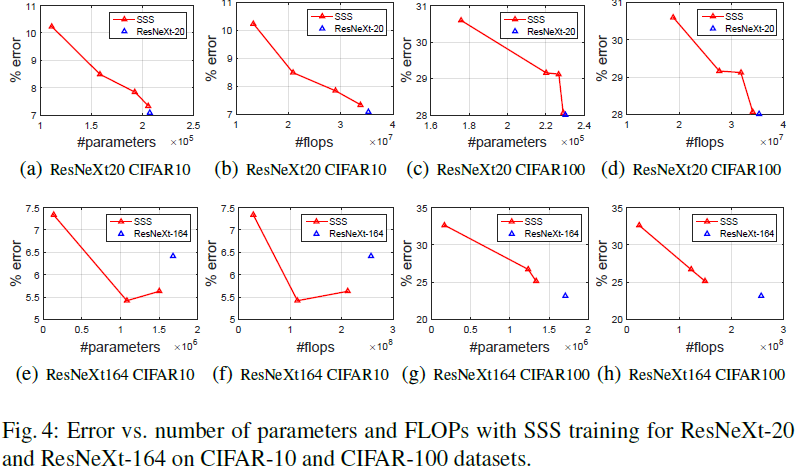
SSS为本文方法的简写,由下图在一些网络上的裁剪结果来说,其裁剪相对于原网络是有损失的,且裁剪出来的压缩率不高。

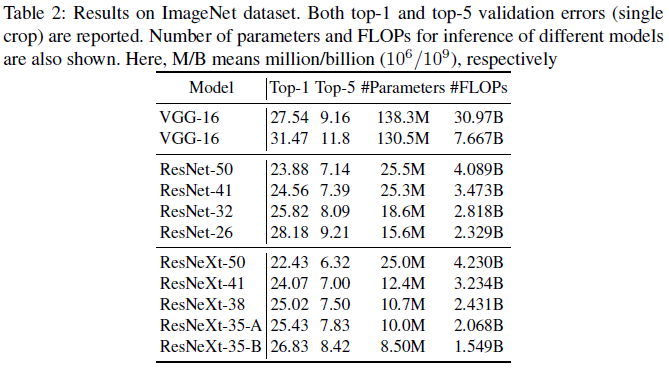
ImageNet