目录
1 knn算法原理
k近邻法(k-nearest neighbor)是一种基本分类与回归方法。k值的选择、距离的度量及分类决策规则是k近邻法的三个基本元素。
k近邻法不具有显式的学习过程,也就是没有一个学习好的模型。
1.1 knn分类
k近邻法的输入为实例的特征向量,对应于特征空间的点;输出为实例的类别,可以取多类。k近邻法假设给定一个训练数据集,其中的实例类别已经给出。分类时,对新的实例,根据其k个最近邻的训练实例的类别,通过多数表决等方式来进行预测。

k近邻法的特殊情况是k=1的情形,称为最近邻算法。
1.2 knn回归
当做回归时,k近邻法的输入为实例的特征向量,对应于特征空间的点;输出为实例的真实值,为连续值。回归时,对新的实例,根据其k个最近邻的训练实例的取值,通过求平均值等方式来进行预测。
1.3 knn三要素
1.3.1 距离度量
特征空间中两个实例点的距离是两个实例点的相似程度的反映。k近邻模型一般使用的距离是欧式距离,但也可以是其他距离。
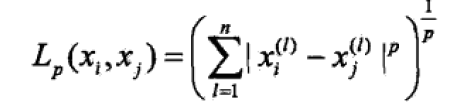
当p=2时,称为欧式距离,p=1时,称为曼哈顿距离。
1.3.2 k值的选择
k值的选择会对k近邻法的结果产生很大影响。如果选择较小的k值,就相当于用较小的邻域中的训练实例进行预测,意味着整体模型会变得复杂,容易产生过拟合。如果选择较大的k值,就相当于用较大的邻域中的训练实例进行预测,意味着整体的模型会变的简单。
在应用中,k值一般取一个比较小的数值,通常采用交叉验证法来选取最优的k值。
1.3.3 分类决策规则或回归规则
k近邻法中的分类决策规则往往是多数表决,回归规则往往是求平均值。多数表决等价于经验风险最小化。
1.4 k近邻法的实现:kd树
实现k近邻法时,主要考虑的问题是如何对训练数据进行快速k近邻搜索。为了提高k近邻搜索的效率,可以考虑特殊的结构存储训练数据,以减少计算距离的次数。具体方法很多,最常用的方法是kd树。
1.5 算法的优缺点
- 优点:精度高,对异常值不敏感,无数据输入假定
- 缺点:计算复杂度高,空间复杂度高
- 适用数据范围:数值型和标称型
2 python实现
书上的例3.1 如图所示。

import numpy as np
x1=np.array([1,1])
x2=np.array([5,1])
x3=np.array([4,4])
def distance(x,y,p=2):
if p==1:
dis=np.abs(x-y)
dist=dis.sum()
return dist
else:
dis=np.abs(x-y)**p
dis_sum=dis.sum()
dist=pow(dis_sum,1.0/p)
return dist
res=distance(x1,x2,1) #x1与x2的曼哈顿距离
print(res)
res=distance(x1,x3,1) #x1与x3的曼哈顿距离
print(res)
res=distance(x1,x2) #x1与x2的欧式距离
print(res)
res=distance(x1,x3) #x1与x3的欧式距离
print(res)
print(round(res,2))
res=distance(x1,x3,3) #x1与x3的l3距离
print(res)
print(round(res,2))
res=distance(x1,x3,4) #x1与x3的l4距离
print(res)
print(round(res,2))3 案例分析
3.1 knn分类案例
3.1.1 使用knn算法改进约会网站的配对效果
分析步骤如下:
(1) 收集数据:提供文本文件。
(2) 准备数据:使用Python解析文本文件。
(3) 分析数据:使用Matplotlib画二维扩散图。
(4) 训练算法:此步骤不适用于k-近邻算法。
(5) 测试算法:使用海伦提供的部分数据作为测试样本。
测试样本和非测试样本的区别在于:测试样本是已经完成分类的数据,如果预测分类
与实际类别不同,则标记为一个错误。
(6) 使用算法:产生简单的命令行程序,然后海伦可以输入一些特征数据以判断对方是否
为自己喜欢的类型。
数据存在文本文件中,每个样本数据占据一行,总共有1000行。海伦的样本主要包含以下3种特征:
-
每年获得的飞行常客里程数;
-
玩视频游戏所耗时间百分比;
-
每周消费的冰淇淋公升数。
(1)将文本记录转换为Numpy的解析程序
def file2matrix(filename):
fr=open(filename)
arrayOnlines=fr.readlines()
numberOfLines=len(arrayOnlines)
returnMat=np.zeros((numberOfLines,3))
classLabelVector=[]
index=0
for line in arrayOnlines:
line=line.strip()
listFromLine=line.split('\t')
returnMat[index,:]=listFromLine[0:3]
classLabelVector.append(int(listFromLine[-1]))
index+=1
return returnMat,classLabelVector
(2)分析数据:使用matplotlib画图
datingDataMat,datingLabels=file2matrix('datingTestSet2.txt')
print("datingDataMat:\n",datingDataMat)
print("datingLabels:\n",datingLabels)
import matplotlib.pyplot as plt
fig=plt.figure()
ax=fig.add_subplot(111)
ax.scatter(datingDataMat[:,0],datingDataMat[:,1],15.0*np.array(datingLabels),15.0*np.array(datingLabels))
plt.show()(3)准备数据:归一化数值
我们很容易发现,上面方程中数字差值最大的属性对计算结果的影响最大,也就是说,每年获取的飞行常客里程数对于计算结果的影响将远远大于表2-3中其他两个特征——玩视频游戏的和每周消费冰淇淋公升数——的影响。而产生这种现象的唯一原因,仅仅是因为飞行常客里程数远大于其他特征值。但海伦认为这三种特征是同等重要的,因此作为三个等权重的特征之一,飞行常客里程数并不应该如此严重地影响到计算结果。
def autoNorm(dataSet):
minVals=dataSet.min(0)
maxVals=dataSet.max(0)
ranges=maxVals-minVals
normDataSet=zeros(shape(dataSet))
m=dataSet.shape[0]
normDataSet=dataSet-minVals
normDataSet=normDataSet/ranges
return normDataSet,ranges,minVals
(3)分类器针对约会网站的测试代码
def datingClassTest():
hoRatio=0.1
datingDataMat, datingLabels = file2matrix('datingTestSet2.txt')
normMat, ranges, minVals = autoNorm(datingDataMat)
m=normMat.shape[0]
numTestVecs=int(m*hoRatio)
errorCount=0.0
for i in range(numTestVecs):
classifierResult=classfy0(normMat[i,:],normMat[numTestVecs:m,:],
datingLabels[numTestVecs:m],3)
print("the classifier came back with:%d,the real answer is:%d"
%(classifierResult,datingLabels[i]))
if classifierResult!=datingLabels[i]:
errorCount+=1.0
print("the total error rate is:%f"%(errorCount/float(numTestVecs)))(4)约会网站预测函数
def classifyPerson():
resultList=['not at all','in small doses','in large doses']
percentTats=float(input("percentage of time spent playing video games?"))
ffMiles=float(input("frequent filter miles earned per year?"))
iceCream=float(input("liters of ice cream consumed per year?"))
datingDataMat,datingLabels=file2matrix('datingTestSet2.txt')
normMat, ranges, minVals = autoNorm(datingDataMat)
inArr=np.array([ffMiles,percentTats,iceCream])
classifierResult=classfy0((inArr-minVals)/ranges,normMat,datingLabels,3)
print("You will probably like this person:",resultList[classifierResult-1])3.2 knn回归案例
(1)数据读取
import pandas as pd
features = ['accommodates','bedrooms','bathrooms','beds','price','minimum_nights','maximum_nights','number_of_reviews']
dc_listings = pd.read_csv('listings.csv')
dc_listings = dc_listings[features]
print(dc_listings.shape)
dc_listings.head()(2)数据特征:
- accommodates: 可以容纳的旅客
- bedrooms: 卧室的数量
- bathrooms: 厕所的数量
- beds: 床的数量
- price: 每晚的费用
- minimum_nights: 客人最少租了几天
- maximum_nights: 客人最多租了几天
- number_of_reviews: 评论的数量
(3)如果我有一个3个房间的房子,能租多少钱呢?K代表我们的候选对象个数,也就是找和我房间数量最相近的其他房子的价格
(4)距离的定义

假设我们的房子有3个房间
import numpy as np
our_acc_value = 3
dc_listings['distance'] = np.abs(dc_listings.accommodates - our_acc_value)
dc_listings.distance.value_counts().sort_index()(5)训练集和测试集
dc_listings.drop('distance',axis=1)
train_df = dc_listings.copy().iloc[:2792]
test_df = dc_listings.copy().iloc[2792:](6)基于单变量预测价格
def predict_price(new_listing_value,feature_column):
temp_df = train_df
temp_df['distance'] = np.abs(dc_listings[feature_column] - new_listing_value)
temp_df = temp_df.sort_values('distance')
knn_5 = temp_df.price.iloc[:5]
predicted_price = knn_5.mean()
return(predicted_price)
test_df['predicted_price'] = test_df.accommodates.apply(predict_price,feature_column='accommodates')(6)评估模型
test_df['squared_error'] = (test_df['predicted_price'] - test_df['price'])**(2)
mse = test_df['squared_error'].mean()
rmse = mse ** (1/2)
rmse(7)使用sklearnk来完成knn
from sklearn.neighbors import KNeighborsRegressor
cols = ['accommodates','bedrooms']
knn = KNeighborsRegressor()
knn.fit(norm_train_df[cols], norm_train_df['price'])
two_features_predictions = knn.predict(norm_test_df[cols])from sklearn.metrics import mean_squared_error
two_features_mse = mean_squared_error(norm_test_df['price'], two_features_predictions)
two_features_rmse = two_features_mse ** (1/2)
print(two_features_rmse)4 参考文献
[1] 李航. 统计学习方法[M]. 清华大学出版社, 2012.
[2] 周志华. 机器学习 : = Machine learning[M]. 清华大学出版社, 2016.
[3] 哈林顿李锐. 机器学习实战 : Machine learning in action[M]. 人民邮电出版社, 2013.