机器学习之KNN的总结
本片文章主要写了针对一个csv数据,目标是对其数据进行分类,怎样用knn实现
在此问题中将该问题分为三个步骤:
- 数据处理:对csv数据进行处理做出适合knn的数据集,包括划分测试集及训练集
- 数据拟合:对数据集数据进行拟合
- 数据预测及评价指标:对所训练得到的结果进行预测以及评价
-
数据处理
-
本实例中的数据集如下图所示:
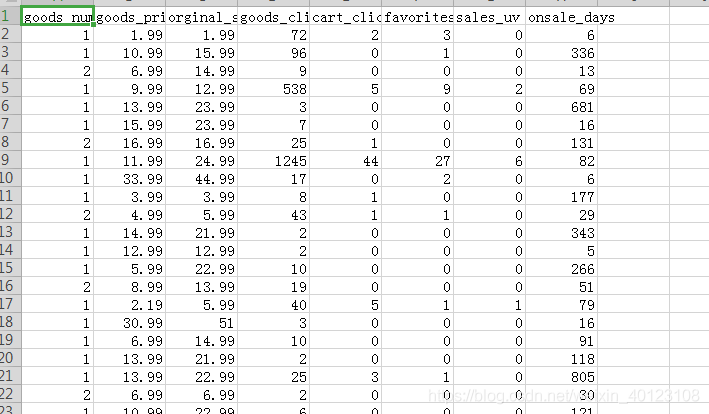
第一列为数据集的标签,第一行为数据集的title,首先要做的处理是将数据集的数据以及标签提取出来。即特征与标签类别# -*- coding: utf-8 -*- """ Created on Tue Nov 27 17:47:44 2018 @author: Administrator """ import csv from sklearn import neighbors knn = neighbors.KNeighborsClassifier()#(n_neighbors=10) from numpy import genfromtxt a = open('list.csv', 'r+') reader = csv.reader(a)#按行读取内容 headers = next(reader)#打印出为title那行 print(headers)

该title第一列为数字序列,后七列为特征名称,其次是提取标签以及数据
dataPath = r"list.csv"
featureList = genfromtxt(dataPath, skip_header=1,delimiter=',',usecols=(1,2,3,4,5,6,7))
#转化为txt,[genfromtxt用法](https://blog.csdn.net/weixin_40123108/article/details/84531460)得到后7列数据
labelList = genfromtxt(dataPath, skip_header=1,delimiter=',',usecols=(0))#得到标签
x= featureList[:]
print(len(x))
#print (x)
#print ("labelList")
y = labelList[:]
#print (y)
划分数据集及训练集
from sklearn.model_selection import train_test_split#分割数据集
X_train, X_test, y_train, y_test = train_test_split(
x, y, test_size=0.25)
print(X_train.shape)
print(X_test.shape)

**
- 数据拟合
**
knn = neighbors.KNeighborsClassifier()#(n_neighbors=10)knn参数用法
knn.fit(X_train,y_train)
**
- 数据预测及评价指标
**
y_predict = knn.predict(X_test)
#调用该对象的测试方法,主要接收一个参数:测试数据集
probility=knn.predict_proba(X_test)
#计算各测试样本基于概率的预测
score=knn.score(X_test,y_test,sample_weight=None)
#调用该对象的打分方法,计算出准确率
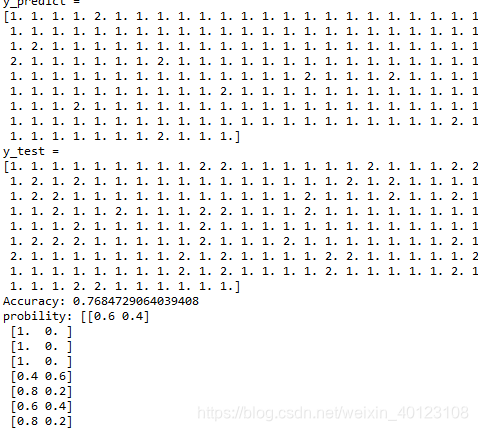
print('y_predict = ')
print(y_predict)
#输出测试的结果
print('y_test = ')
print(y_test)
#输出原始测试数据集的正确标签,以方便对比
print ('Accuracy:',score )
#输出准确率计算结果
print ('probility:',probility)