一 问题描述
Logistic回归常用于探索疾病的危险因素。从马各项症状指标预测马是否死亡,在规模较大的马场,这种方法能够及时有效对存活可能性大的马进行治疗。
二 数据准备
马病症数据集来自UCI(http://archive.ics.uci.edu/ml/datasets/Horse+Colic)。包含368个样本和28个特征。
样本中有30%的缺失值,用0填充。
三 算法原理
定义目标函数为
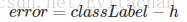
要求error的绝对值最小。

激活函数
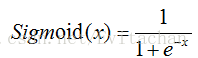

当x=0时,Sigmoid函数值为0.5,随着x增大,函数值逼近1,随着x减小,函数值逼近0。为实现Logistic回归,我们在每一个特征上都乘上回归系数,然后将求和的结果带入Sigmoid函数,得到范围在0~1之间的取值,大于0.5是1类,小于0.5是0类。
三 模型建立
1. 随机梯度上升算法
输入训练数据集矩阵,标签和迭代次数,遍历每个样本,不断调整回归系数。
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
m,n = shape(dataMatrix)
weights = ones(n) #initialize to all ones
for j in range(numIter):
dataIndex = list(range(m))
for i in range(m):
alpha = 4/(1.0+j+i)+0.0001 #apha decreases with iteration, does not
randIndex = int(random.uniform(0,len(dataIndex)))#go to 0 because of the constant
h = sigmoid(sum(dataMatrix[randIndex]*weights))
error = classLabels[randIndex] - h
weights = weights + alpha * error * dataMatrix[randIndex]
del(dataIndex[randIndex])
return weights
2. 分类器
输入为待分类样本和回归系数,计算sigmoid函数值,大于0.5为第1类,小于0.5为第0类。
def classifyVector(inX, weights):
prob = sigmoid(sum(inX*weights))
if prob > 0.5: return 1.0
else: return 0.0
3. 测试器
colicTest()函数中,先训练“horseColicTraining.txt”数据集中的数据得到回归系数,再遍历“horseColicTest.txt”测试集中每一个样本,调用分类器函数,得到分类结果,比较分类结果和实际结果,如果不同,错误数+1,遍历结束后,错误数/总样本数就是错误率。multiTest()函数调用colicTest()函数10次,并求平均错误率。
def colicTest():
frTrain = open('horseColicTraining.txt'); frTest = open('horseColicTest.txt')
trainingSet = []; trainingLabels = []
for line in frTrain.readlines():
currLine = line.strip().split('\t')
lineArr =[]
for i in range(21):
lineArr.append(float(currLine[i]))
trainingSet.append(lineArr)
trainingLabels.append(float(currLine[5]))
trainWeights = stocGradAscent1(array(trainingSet), trainingLabels, 1000)
errorCount = 0; numTestVec = 0.0
for line in frTest.readlines():
numTestVec += 1.0
currLine = line.strip().split('\t')
lineArr =[]
for i in range(5):
lineArr.append(float(currLine[i]))
if int(classifyVector(array(lineArr), trainWeights))!= int(currLine[21]):
errorCount += 1
errorRate = (float(errorCount)/numTestVec)
print ("the error rate of this test is: %f" % errorRate)
return errorRate
def multiTest():
numTests = 10; errorSum=0.0
for k in range(numTests):
errorSum += colicTest()
print ("after %d iterations the average error rate is: %f" % (numTests, errorSum/float(numTests)))

四 总结
此次采用书上提供的Logistic回归算法,通过疝气病症预测病马的死亡率,由于对缺失的30%数据都用0代替,所以最后错误率不低于30%,预测结果比较差。于是借用之前已经处理过的Titanic数据集重新进行了训练和测试,最后结果比较理想。Titanic数据集测试结果如下。
