Logistic 回归
目录
- logistics 概述
- 梯度上升算法
- 随机梯度上升算法
- 改进的随机梯度上升算法
一、logistics 概述
谈到“逻辑回归”,不得不说的就是 sigmoid 函数
函数图像:
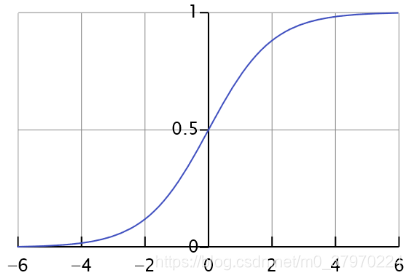
可以知道:
当z=0时,s(z)=0.5
当z→正无穷,s(z)趋于1
当z→负无穷,s(z)趋于0
二、梯度上升算法
与梯度下降算法一个道理,只不过梯度下降找的是最小值,所以加上了负号,而这边不需要负号
公式如下:
代码如下:
from numpy import *
from numpy.ma import exp, array, arange
import matplotlib.pyplot as plt
# 加载数据集
def loadDataSet():
dataMat = []
labelMat = []
fr = open('testSet.txt')
for line in fr.readlines():
lineArr = line.strip().split()
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
labelMat.append(int(lineArr[2]))
return dataMat, labelMat
# sigmoid公式
def sigmoid(inX):
return 1.0/(1+exp(-inX))
# 梯度上升算法
def gradAscent(dataMatIn, classLabels):
dataMatrix = mat(dataMatIn) # 转成矩阵
labelMat = mat(classLabels).transpose() # transpose()是转置,行向量转成列向量
m, n = shape(dataMatrix) # 100×3
alpha = 0.001 # 向目标移动的步长,其实就是learning rate(学习率)
maxCycles = 500 # 迭代次数
weights = ones((n, 1)) # 设置初始权重都为1
print(dataMatrix*weights)
for k in range(maxCycles): # heavy on matrix operations
h = sigmoid(dataMatrix*weights) # matrix mult
error = (labelMat - h) # vector subtraction
weights = weights + alpha * dataMatrix.transpose()*error # 解释:https://blog.csdn.net/kaka19880812/article/details/46993917
return weights
其中这步不好理解:
weights = weights + alpha * dataMatrix.transpose()*error
解释如下:

三、随机梯度上升算法
随机梯度上升算法与梯度上升算法在代码上很相似,但也有一些区别:
第一,后者的变量h和误差erro都是向量,而前者则全是数值
第二,前者没有矩阵的转换过程,所有变量的数据类型都是NumPy数组
代码如下:
# 随机梯度上升算法
def stocGradAscent0(dataMatrix, classLabels):
m, n = shape(dataMatrix)
alpha = 0.01
weights = ones(n)
for i in range(m):
h = sigmoid(sum(dataMatrix[i]*weights))
error = classLabels[i] - h
weights = weights + alpha * error * dataMatrix[i]
return weights
随机梯度上升算法计算复杂度相对较低,它是一个个样本进行迭代参数。
四、改进的梯度上升算法
改进的地方就是:
1、learning rate :先大后小,随迭代次数不断变化
2、随机选取样本,并非按顺序
代码:
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
m, n = shape(dataMatrix)
weights = ones(n)
for j in range(numIter):
dataIndex = list(range(m))
for i in range(m):
alpha = 4/(1.0+j+i)+0.0001 # apha decreases with iteration, does not
randIndex = int(random.uniform(0, len(dataIndex))) # go to 0 because of the constant
h = sigmoid(sum(dataMatrix[randIndex]*weights))
error = classLabels[randIndex] - h
weights = weights + alpha * error * dataMatrix[randIndex]
del(dataIndex[randIndex])
return weights