MobileNet: Efficient Convolutional Neural Networks for Mobile Vision Applicatons
论文地址: https://arxiv.org/abs/1704.04861.
这篇论文介绍了一种应用在移动设备和嵌入式上的网络结构—MobileNet。MobileNet利用depthwise separable convolution 来构建轻量级深度神经网络。作者引入了两个简单的全局超参来有效地平衡延迟度和准确度。这两个超参允许使用者根据需要来选择合适大小的模型。
1. Introduction
自从AlexNet赢得ImageNet挑战赛以来,卷积网络在计算机视觉领域已经无所不在。但是伴随着模型精度的提升是计算量,存储空间以及能耗方面的巨大开销,对于移动或嵌入式都是难以接受的。
这篇论文介绍了一种高效的网络结构以及两个超参数,以此来搭建一个小型、低延迟的模型。作者进一步深入的研究了depthwise separable convolutions后设计出此网络结构,depthwise separable convolutions的本质是冗余信息更少的稀疏化表达。在此基础上引入了模型设计的两个超参数:width multiplier 和 resolution multiplier。作者也通过了多种的实验证明了 MobileNet 高效性。
2. Prior work
之前的一些模型小型化工作将焦点放在如何缩小模型的尺寸上,而不是提升速度(缩小延迟性)。
因此,在小型化方面常用的手段有:
(1)卷积核分解,使用 和 的卷积核代替 的卷积核;
(2)使用bottleneck结构,以SqueezeNet为代表;
(3)以低精度浮点数保存,例如Deep Compression;
(4)冗余卷积核剪枝及哈弗曼编码。
MobileNet 主要基于depthwise separable convolutions来减少模型前面几层的计算量。
3. MobileNet Architecture
3.1 Depthwise Separable Convolution
MobileNet主要基于 depthwise separable convolution,它把一个标准的卷积拆分成:一个 depthwise convolution 和 一个 的 pointwise 卷积。Depthwise 卷积在每个输入通道上使用一个滤波器。Pointwise 卷积然后使用一个 的卷积来结合 depthwise 卷积的输出。这种拆分极大地降低了计算量和模型大小。下图展示了标准卷积如何拆分为 depthwise 卷积和 pointwise 卷积。

一个标准3D卷积的输入为 大小的特征映射 ,输出为 的特征映射 , 是正方形输入特征映射的高和宽。 是输入通道的个数。 是正方形输出特征映射的高和宽, 是输出通道的个数。标准卷积可用卷积核 参数化表示, 大小为 , 是正方形卷积核的大小, 是输入通道数, 是输出通道数。
这样,一个 stride=1, padding=1 的标准3D卷积输出的特征映射计算如下:
计算成本为:
计算成本取决于输入通道数
,输出通道数
,卷积核大小
和输入大小
。
Depthwise separable convolution 由两层组成:depthwise 卷积和 pointwise 卷积。Depthwise 卷积在每个输入通道上都应用 一个 filter. 然后使用 pointwise 卷积( 卷积)来线性地结合 depthwise 层的输出。MobileNet 在这两个层中均使用了批归一化和ReLU激活函数。
参考上图:我们会首先使用一组二维的卷积核,也就是卷积核的通道数为1,每次只处理一个输入通道的,这一组二维卷积核的数量是和输入通道数相同的。在使用逐个通道卷积处理之后,再使用3D的 卷积核来处理之前输出的特征图,将最终输出通道数变为一个指定的数量。
对于每个输入通道,一个 filter 的 depthwise 卷积可写作如下形式:
是 大小为
的 depthwise 卷积核,
中第
个 filter 应用在
中第
个通道上,来产生输出特征映射
的第
个通道。
这样,depthwise 卷积的计算成本是:
Depthwise 卷积比起标准3D卷积来说,非常的高效。
接下来我们需要一个
的 pointwise 卷积层来线性地结合 depthwise 卷积层的输出。它们共同构成了 Depthwise Separable Convolution. 其总成本为:
左边为depthwise 卷积的成本,右边为 pointwise 卷积的成本。
Depthwise 方式的卷积相比于标准3D卷积计算量为:
举一个具体的例子,给定输入图像的为3通道的
的图像,VGG16网络的第3个卷积层conv2_1输入的是尺寸为112的特征图,通道数为64,卷积核尺寸为3,卷积核个数为128,传统卷积运算量就是:
而 Depthwise Separable Convolution计算量是:
二者相比较,可得
3.2 Network Structure and Training
标准3D卷积常见的使用方式如下图左侧所示,Depthwise卷积的使用方式如下图右边所示。把 depthwise 卷积和 pointwise 卷积分开来算,MobileNet 有28层。

从图中可以看出,Depthwise的卷积和后面的 pointwise 卷积被当成了两个独立的模块,都在输出结果的部分加入了Batch Normalization和ReLU非线性激活。
Depthwise separable convolution 结合 的卷积方式代替传统卷积不仅在理论上会更高效,而且由于大量使用 的卷积,可以直接使用高度优化的数学库来完成这个操作。以Caffe为例,如果要使用这些数学库,要首先使用im2col的方式来对数据进行重新排布,从而确保满足此类数学库的输入形式;但是 方式的卷积不需要这种预处理。
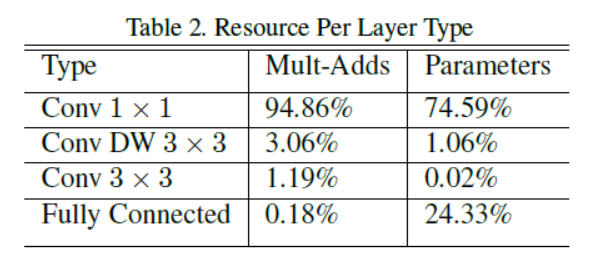
如下图,MobileNet 花费了95%的计算时间在 卷积上, 卷积使用了75%的参数,全连接层使用了几乎所有的额外参数。
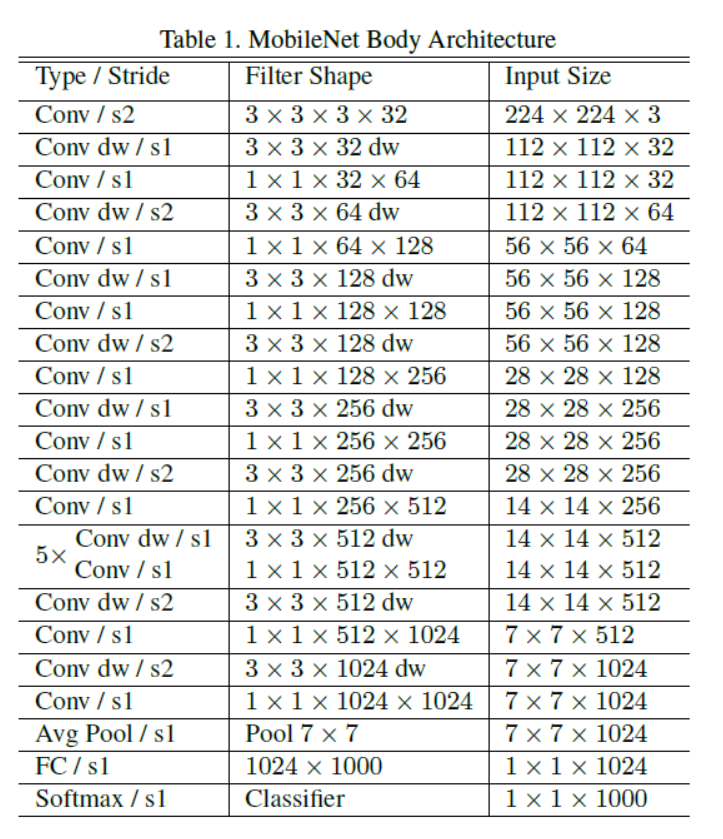
MobileNet 网络结构为:
3.3 Width Multiplier: Thinner Models
尽管MobileNet 在计算量和模型尺寸方面有很明显的优势,但在一些要求极其苛刻的场合和应用上,可能要求模型更小更快。
作者因此引入了一个超参数width multiplier,
,
通常设为1, 0.75, 0.5 和 0.25。
为 baseline MobileNet,
为 reduced MobileNet。参数
用于细化网络的各层。对于给定的某层,它的输入通道
就变为了
,输出通道
变为了
。Depthwise Separable Convolution 的计算量就是:
Width multiplier 可以有效地降低计算量和参数个数至 倍。
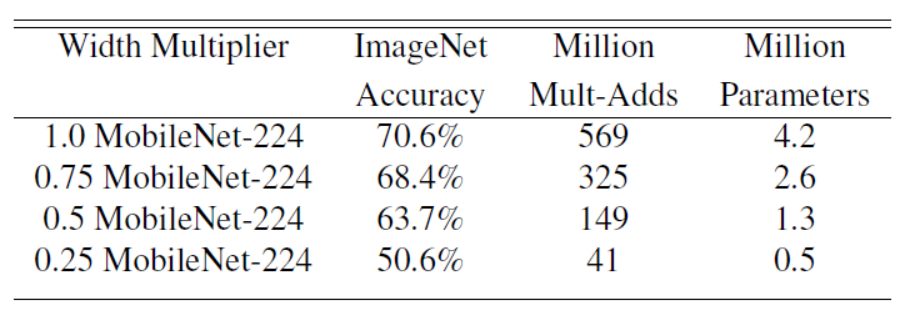
通过下图可以看出使用 系数进行网络参数的约减时,在ImageNet上的准确率,为准确率、参数数量和计算量之间的权衡提供了参考(每一个项中最前面的数字表示α的取值)。
3.4 Resolution Multiplier: Reduced Representation
第二个用于降低计算量的超参数是 resolution multiplier
. 它的值
, 是作用于每一层输入尺寸的约减因子,简单来说就是将输入数据以及由此在每一个模块产生的特征图都变小了,结合 width multipler
,depthwise 卷积结合
的 pointwise 卷积核计算量为:
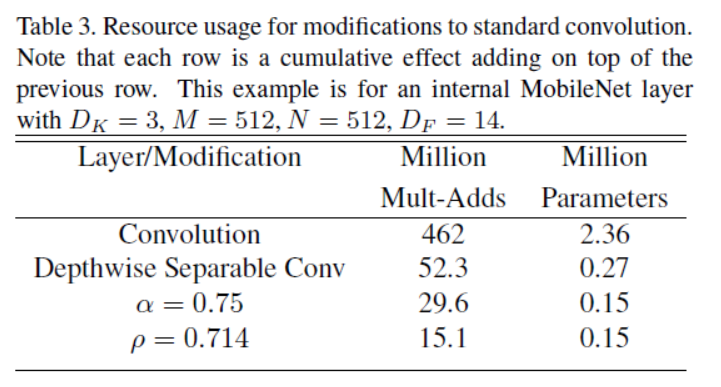
下图显示了随着网络结构的收缩,每层参数个数和计算量的变化:
4. Experiments
略,详见论文。
博客引用
本论文部分内容有参考 https://blog.csdn.net/t800ghb/article/details/78879612.