这篇文章主要讲的是深度学习网络篇中轻量化网络之一的MobileNet和MobileNet v2。在深度学习中轻量化网络有很多方法, 比如说卷积核分解、使用bottleneck结构、用低精度浮点数保存模型、冗余卷积核剪枝和哈弗曼编码等等。MobileNet的主要是在卷积核分解方面做文章,友情提示:MobileNet不是模型压缩技术,而是一种网络形式的优化。下面就进入我们今天的正题——MobileNet & MobileNet v2。
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications——MobileNet论文地址
MobileNetV2: Inverted Residuals and Linear Bottlenecks——MobileNet v2论文地址
MobileNet主要从以下四个方面来介绍:
- MobileNet改变的卷积结构
- MobileNet的网络结构
- 两个超参——宽度因子和分辨率因子
- 更多的实验环节
MobileNet改变的卷积结构
首先声明,并不是从这篇文章开始对卷积进行优化的,在此之前有很多大佬们都对卷积结构进行过优化,比如说我们下面要补充的这篇文章——Factorized Convolutional Neural Networks (论文地址)。至于为什么MobileNet有更多的关注,个人猜测可能效果要更好一些。
先补充一下关于Factorized Convolutional的东西,这样我们理解MobileNet的卷积结构会更轻松。
Factorized Convolutional Neural Networks:因式分解卷积神经网络
我们先来看最最普通的卷积,输入图像(长x宽x通道数):
,输出图像(长x宽x通道数):
,卷积核大小(3D卷积:长x宽x通道数x数量):
。
它的卷积过程如下图:

经过Factorized Convolutional优化过的bases卷积,输入输出同上,卷积操作被分为两步(这是这篇文章中因式分解卷积的精髓),第一步是将通道分离开来,对于单通道进行3D卷积,生成b个通道数的Feature Map;第二步是将M个b通道数的Feature Map进行卷积数量为N个、卷积大小为1x1xM的卷积操作;
它的卷积过程如下图:

Factorized Convolutional还有其他方法优化的卷积,比如说基于bases的stacked的卷积结构和拓扑连接等等。有兴趣的伙伴们可以去看论文的原文或者博客,吼吼吼!
看过了Factorized Convolutional以后,我们来看一下MobileNet里面卷积结构。输入和输出同上,卷积同样分为两步,第一步是深度卷积(depthwise convolution),即对输入图像进行数量为M大小为kxkx1的2D卷积;第二步是点态卷积(pointwise convolution),即进行数量为N个大小为1x1xM的卷积进行卷积;
它的卷积过程如下图:

我们可以用比率来比较优化后和优化前的计算量:
显而易见,N的取值在几百左右,k的取值在个位数,且都是正值,所以优化效果还是很明显的。我们可以这样来算一笔账:对于输入Feature Map为14x14x128,输出Feature Map为7x7X256,卷积核大小为3x3和1x1,Factorized conv中b=3,计算量分别如下:
| 卷积类型 | 计算量 | 优化效果 |
|---|---|---|
| conv | 3x3x128x14x14x256=57802752 | - |
| Factorized conv (bases) | (3x3+256)x3x128x14x14=19944960 | 34.51% |
| MobileNet conv | (3x3+256)x128x14x14=6648320 | 11.50% |
MobileNet的网络结构
先来看一下MobileNet的卷积模块,将【普通卷积3x3+BN+Relu】拆分成【深度卷积3x3+BN+Relu】+【点态卷积1x1+BN+Relu】,如下图:


上图中需要说明几个地方:
- 在之前的网络中下采样我们用的方式是pooling,而在MobileNet中下采样采用的是步长为2的卷积实现下采样,即Conv/s2;(思考——为什么卷积可以代替池化做下采样?原因:准确来说步长>1的卷积可以代替平均池化做下采样,对于图像或者Feature Map的矩阵形式来说,下采样的原理就是将原始图像nxn窗口内的图像变成一个像素,所以步长>1的卷积和池化的目的相同)
- 论文中提到的Shallow MobileNet是将上图中的【5 x Conv】的那一组卷积操作删掉形成的,在后面的实验中也可以看到MobileNet和Shallow MobileNet的比较;
两个超参——宽度因子和分辨率因子
作者还介绍了两个简单的全局参数:宽度因子(Width Multiplier: Thinner Models) 和 分辨率因子(Resolution Multiplier: Reduced representation)。
宽度因子(Width Multiplier: Thinner Models)
将原输入通道M压缩为
,将原输出通道N压缩为
,其中,
,常取值为1 , 0.75, 0.5, 0.25;则计算量为:
分辨率因子(Resolution Multiplier: Reduced representation)
将原输入图像的大小压缩为
,其中,
,常见的压缩后的图像大小:224,192,160,128;则计算量为:
同时对MobileNet进行宽度因子和分辨率因子的调整,则计算量为:
更多的实验环节
实验一:模型的选择
首先比较的就是Narrow MobileNet( ) 和Shallow MobileNet(去掉5组的卷积模块),准确率和计算量如Table 5所示:

实验二:模型的收缩参数(即两个因子)
先比较的收缩参数是宽度因子 ,输入图像大小都为224,如Table 6所示:

再比较的收缩参数是分辨率因子 , 取值都为1,如Table 7所示:
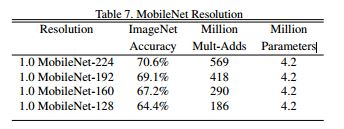
在论文中还有更多关于MobileNet的实验,包括收缩参数、细粒度识别、大规模的地理校正、物体检测、人脸识别等等;有兴趣仔细研究的小伙伴们可以回去翻看原论文~
接下来就是我们的MobileNet的好伙伴MobileNet v2啦,从名字就可以看出这是对MobileNet的升级版,主要是将MobileNet的思想应用在了Shortcut connection上了。(个人观点:MobileNet实际上就是对残差结构的轻量化,哈哈哈)MobileNet在图像分类、物体检测、语义分割等等方面都有很不错的表现,具体的可以参考一下原论文。
MobileNet v2主要改进的两点:
- Linear Bottlenecks
- Inverted Residuals
下期预告:在网络的轻量化方面有很多网络都在尝试和付出努力,下一篇是轻量化网络——ShuffleNet。shuffleNet主要研究如何在轻量化网络的基础上提高性能,重点有两个:就是通道混洗和点态卷积群。详情请见下次分享:深度学习网络篇——SuffleNet & ShuffleNet v2。
| 这是我们2018年的最后一篇文章啦,感谢各位小伙伴们在2018年的关注和支持!也很感恩老师师兄师姐和小伙伴们对我们的无私帮助!还请各位大家在2019年持续关注!我们会努力分享,祈愿大家共同进步! |
| ps:祝各位小伙伴们新年快乐!2019年没有bug!!!冲冲冲!!! |