1、简介
强化学习的任务对应一个四元组:
- X:当前状态
- A:可采取的动作总体集合
- P:各个转移状态的概率值
- R:奖赏函数
整体的过程是,对于当前状态X,从动作集合A中选择一个动作,作用在X上,使得X按照概率转移函数P转移到另外一种状态,然后环境根据奖赏函数R对动作进行反馈。
强化学习在某种意义上可看作具有延迟标记信息的监督学习,它与监督学习不同,监督学习每个样本会有对应的标签,强化学习没有标签,而是执行完动作之后,通过反馈来判断执行动作是否正确。
2、两个基本概念:
2.1长期累积奖赏的计算方式
在强化学习任务中,目的就是找到使长期累积奖赏最大化的策略,而长期累积奖赏有多重计算方式,常用的有两种:T步累积奖赏和 折扣累积奖赏。
2.1.1 T步累积奖赏
E表示对所有随机变量求期望,T步累积奖赏也就是求T次执行策略的均值。
2.1.2 折扣累积奖赏
也就是说每一次执行,之前的策略权重会以 进行衰减。
2.2 探索与利用
探索是我要从多个策略中,找到最优的执行方案,这需要多次随机的执行策略,而利用就是按照当前已经得到的信息,选择最优的执行方案以达到最大化奖赏。探索和利用是矛盾的,如果仅仅是探索,那么可以比较完整的得到每个策略优劣情况,但是会失去很多次执行最优方案的机会,而利用则是每次都会执行最优方案,就会对各个策略的把握不够全面,可能执行的并不是最优的策略,所以强化学习的算法一般要找到一个平衡点,平衡这两个方面。
3 两个平衡探索与利用的算法
3.1 贪心
就是
是(0,1)之间的数,以
的概率进行探索,以1-
的概率进行利用,当数据的概率比较不确定时,会采用比较大的
,比较多的去探索,当数据比较确定事就可以采用一个比较小的
。其中计算奖赏的方式采用增量更新的方法,当第n次尝试获得奖赏
后,平均奖赏
更新为(其中k表示所有的可执行策略,每一个
都用增量更新的方法维护一个平均奖赏值):
3.2 Softmax
利用softmax函数去挑选执行策略,softmax函数经过指数变换之后,可以让平均奖赏比较大的执行策略有比较高的被采纳可能,同时也保证了平均奖赏低的策略还有一定被采纳的可能。对数映射然后将概率归一化的函数可以表示为:
其中 称为温度,它对平均概率进行缩放,当 比较小时,会放大平均奖赏的差异,倾向于选取最优的策略,当 比较大时,会缩小平均奖赏的差异,倾向于探索。
4、有模型学习
有模型学习就是当强化学习任务中的四元组 均已知,这种模型的关键就是构造状态转移的概率函数P和奖赏函数R。有模型学习分为两个步骤,一个是策略评估,得到采取当前策略中的各个动作所能得到的奖赏,二是策略改进,根据策略评估的结果选择最优的动作。这两个步骤不停的迭代更新直到收敛,得到最优的策略。
4、1 策略评估
对于每个状态x,T步累积奖赏公式为:
表示在x状态下,实施 策略后所带来的的累积奖赏,A可进行的操作的总体集合,a是A中其中一个操作, 表示在x状态下,选择a操作的概率, 表示在x状态下,采用a操作,x从x状态到x’状态的概率。后面的部分则是以增量的形式求当前的奖赏。
同理,对于 折扣累积奖赏:
只有当P和R已经才能进行全概率展开。V成为状态值函数,它计算了从x状态出发,执行策略所带来的的总体奖赏,而V去掉前部分 ,不再以全概率的形式计算总体结果,而是假定发生了某一个操作a,则变成了Q,状态动作值函数:
4、2 策略改进
值迭代更新当前的Q函数(因为
会发生改变,所以每一次重新计算新的状态动作值函数),选出奖赏最大的操作,即:
然后进行策略迭代,就是对于每个状态x,选择最大奖赏的策略a为操作,当前一个策略与当前策略相同时,就找到了最优策略。
事实上,每次先进行值迭代,再进行策略迭代,会比较耗时,其实可以先将值迭代至收敛,或者是奖赏变化小于设定的阈值,再进行策略迭代选择策略。
5、免模型学习
当转移概率P和奖赏函数R未知的时候,不能用有模型学习,甚至难以知道环境中有多少种状态,这时候需要免模型学习。
5、1 蒙特卡罗
5.1.1 同策略蒙特卡罗法
当P和R未知,甚至有多少种状态也未知时,只能从某一状态出发,通过不断探索,得到不同的状态和所能获得的奖赏,蒙特卡罗法从某一状态出发,使用某种策略采样,记录新的状态和所获得的奖赏,多次采样得到多条轨迹,在对累积奖赏求平均,得到最后的状态动作值函数。
根据蒙特卡罗的算法,我们需要采样出多条不同的轨迹,但是很多时候策略的选择是固定,这时候用 贪心的算法,以一定的概率( )选取最优操作,一定的概率 随机选择操作,得到多条轨迹。
被评估的策略和被改进的策略都是 贪心的算法,所以称为同策略,但是采用 贪心的算法只是为了进行模型评估,实际上最后改进和使用的应该是非 贪心的算法,异策略的蒙特卡罗法就是一种评估和改进的策略不同的算法。
5.1.2 异策略蒙特卡罗法
异策略的蒙特卡罗法是评估和改进的策略不同的算法,评估的策略采用 贪心的算法,而改进的策略采用非 贪心的算法,要了解异策略算法,首先要了解一个采样的概念:重要性采样。
重要性采样(importance sampling)
当函数的f的概率分布函数p可知的情况下,函数f的期望可以表示为:
而当我们不知道概率分布函数p时,或者说获得满足分布p的样本不容易得到时,我们可以引入另一个分布q(x)能比较好的生成样本,通过这些样本去得到满足p(x)分布的f(x)函数的期望。具体做法是:
引入可以方便生成样本的q(x):
另 ,其中w(x)称为importance weight:
就把问题转化为求g(x)在q(x)下的期望。那么就可以通过生成满足q(x)的g(x)样本去估计f(x)的期望,即:
这里不需要知道p(x)和q(x)的具体函数,只要在满足q(x)分布下对f(x)进行采样,然后乘以p(x)和q(x)的比例就可以估计f(x)在p(x)下的的期望。
异策略蒙特卡罗流程
利用上述的重要性采样方法,现在我们可以得到的是
贪心的算法
,而我们希望改进的策略是非
贪心的算法
,根据上述,我们只需要找到
和
的比值即可。如果
为确定性策略,那么它每次都会选择最优操作,最优策略为1,而对于
,它是以
的概率随机采样,这时候选中最优策略的概率是
,以
的概率去选最优,这时候选中最优的策略是
。所以总体来说,当采样操作
与确定性策略
相同时,概率是
,不同时概率是
。所以整体的流程图如下:(西瓜书386页)

5、2 时序差分
时序差分的方法就是动态规划的蒙特卡罗法,蒙特卡罗法每次都要进行采样,然后采用批处理的方式计算累积奖赏的期望,其实可以采用动态的规划的方式计算,降低运算复杂度。
只要加上增量部分 就可以用动态规划的方式得到下一个奖赏,经常会把 写成系数 ,把 设为值比较小的正数,当 比较大时候越靠后的奖赏越重要。
类似的, 折扣累积奖赏也可以写成增量的形式:
整体的流程:

5、3 值函数近似
前面讨论的情况是在有限状态下的,如果状态在多维的连续空间下,有无穷个状态,前面的算法就不再适用,这时候要用值函数近似的方法,通过参数和模型对状态向量建模,拟合采样得出的奖赏,简单的情况例如线性函数:
通过最小二乘误差让学习的值函数你和真实的值函数:
对 求偏导可以得到更新规则:
我们不知道真实的值函数 ,可以用时序差分的方法得到, ,更新规则变为:
时序差分的过程中,需要使用状态-动作值函数Q获得策略,而不是单纯的V,一般的做法是给操作编号拼接在状态向量后面,即: ,或者对a进行独热编码,拼接在x后面。整体的算法流程:

5、4 模仿学习
5.4.1 直接模仿学习
类似于迁移学习,当决策的搜索空间巨大时,直接模仿人类专家的操作,在人类操作的操作上再对策略进行学习,得到更好的策略。
5.4.2 逆强化学习
在很多任务中,设计奖赏函数可能相当困难,通过范例反推奖赏函数有助于解决问题。

6、AlphaGo原理浅析
AlphaGo的方法是一个强化学习的方法,它分为策略网络(policy network)和价值网络(value network),策略网络通过蒙特卡罗的方法对执行操作进行采样,结果通过价值网络进行评估,价值网络用卷积神经网络cnn对执行后的局面提取特征,得出一个胜率的评估,价值网络得出结果后反作用到策略网络上,重复迭代得到比较好的执行策略。
价值网络
价值网络用于评估执行后的策略优劣,通过CNN在19*19的棋盘上进行特征提取,结合人的先验知识提取特征,主要包括棋子颜色,轮次,气,打吃,被打吃,征子等,将特征叠加在一起形成19*19*48的输出,对最后的输赢进行学习,得到一个输赢的概率。
策略网络
策略网络主要使用蒙特拉罗树搜索的方法,跟人的思考方法类似,模拟未来棋局,然后选择在模拟中选择次数最多的走法。
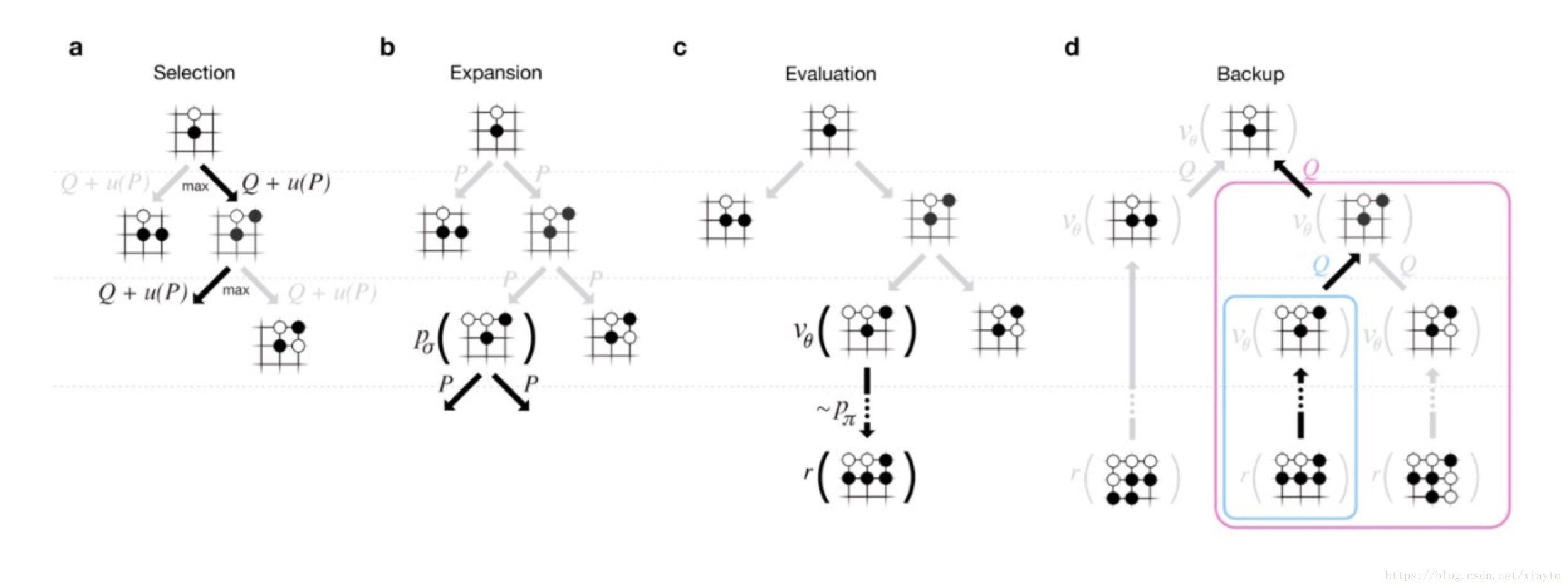
两个网络迭代更新训练出比较好的策略。