10 机器学习系统的设计
10.1 构建学习算法的方法
以一个垃圾邮件分类器算法为例。先要做的决定是如何选择并表达特征向量x, 可以选择一个由 100 个最常出现在垃圾邮件中的词所构成的列表,根据这些词是否有在邮件中出现,来获得我们的特征向量(出现为 1,不出现为 0),尺寸为 100×1。构建一个学习算法的推荐方法为:
1)从一个简单的能快速实现的算法开始,实现该算法并用交叉验证集数据测试这个算法。
2)绘制学习曲线,决定是增加更多数据,或者添加更多特征,还是其他选择。
3)进行误差分析:人工检查交叉验证集中我们算法中产生预测误差的实例,看看这些实例是否有某种系统化的趋势。
10.2 类偏斜的误差度量
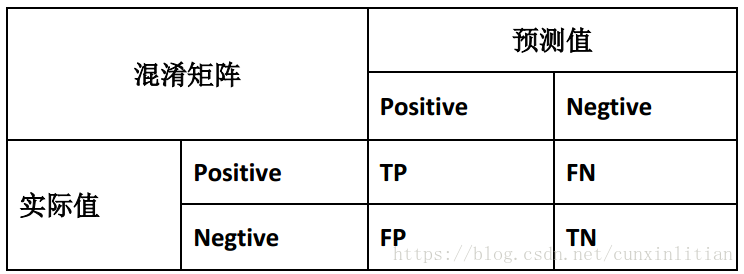
类偏斜情况表现为训练集中有非常多的同一种类的实例,只有很少或没有其他类的实例。这时,误差的大小是不能视为评判算法效果的依据的。查准率( Precision)和查全率( Recall)我们将算法预测的结果分成四种情况:
1)正确肯定( True Positive,TP):预测为真,实际为真。
2)正确否定( True Negative,TN):预测为假,实际为假。
3)错误肯定( False Positive,FP):预测为真,实际为假。
4)错误否定( False Negative,FN):预测为假,实际为真。
查准率(P)=TP/(TP+FP)。表示所有预测为真的样本中,实际上为此真的百分比,越高越好;查全率(R)=TP/(TP+FN)。表示所有实际上为此真的样本中,成功预测为真的百分比,越高越好。
10.3 权衡查准率和查全率
假设算法输出的结果在 0-1 之间,使用阀值 0.5 来预测真和假。如果希望只在非常确信的情况下预测为真,即希望更高的查准率,可以使用比0.5更大的阀值,如 0.7,0.9。但是会增加未能成功预测为假的情况,反之,亦然。
想要权衡查准率和查全率,选择计算F1 值( F1 Score),其计算公式为:
选择使得最高的阀值。