十一、机器学习系统的设计
11.0 工作的优先级:垃圾邮件分类例子
我们将垃圾邮件标注为 spam 用1表示
将废垃圾邮件标注为 non-spam 用0表示
如果我们有一些这样标注好的垃圾和非垃圾邮件样本,如何来训练一个垃圾邮件分类器?很清楚这是一个有监督学习的问题,假设我们选择逻辑回归算法来训练这样的分类器,首先必须选择合适的特征。这里定义:
- x = 邮件的特征;
- y = 垃圾邮件(1) 或 非垃圾邮件(0)
我们可以选择100个典型的词汇集合来代表垃圾/非垃圾(单词),例如deal, buy, discount, andrew, now等,可以按它们的字母顺序排序。对于已经标注好的邮件训练样本,如果100个词汇中有单词j在样本中出现,就用1代表特征向量x中的xj,否则用0表示,这样训练样本就被特征向量x所替代:
注意在实际使用中,我们不会手动去选择100个典型的词汇,而是从训练集中选择出现频率最高的前n个词,例如10000到50000个。
那么,如何高效的训练一个垃圾邮件分类器使其准确率较高,错误率较小?
- 首先很自然的考虑到收集较多的数据,例如"honeypot" project,一个专门收集垃圾邮件服务器ip和垃圾邮件内容的项目;
- 但是上一章已经告诉我们,数据并不是越多越好,所以可以考虑设计其他复杂的特征,例如利用邮件的发送信息,这通常隐藏在垃圾邮件的顶部;
- 还可以考虑设计基于邮件主体的特征,例如是否将"discount"和"discounts"看作是同一个词?同理如何处理"deal"和"Dealer"? 还有是否将标点作为特征?
- 最后可以考虑使用复杂的算法来侦测错误的拼写(垃圾邮件会故意将单词拼写错误以逃避垃圾邮件过滤器,例如m0rtgage, med1cine, w4tches)
11.1 首先要做什么
以一个垃圾邮件分类器算法为例进行讨论。
为了解决这样一个问题,我们首先要做的决定是如何选择并表达特征向量 x x x。我们可以选择一个由100个最常出现在垃圾邮件中的词所构成的列表,根据这些词是否有在邮件中出现,来获得我们的特征向量(出现为1,不出现为0),尺寸为100×1。
为了构建这个分类器算法,我们可以做很多事,例如:
- 收集更多的数据,让我们有更多的垃圾邮件和非垃圾邮件的样本
- 基于邮件的路由信息开发一系列复杂的特征
- 基于邮件的正文信息开发一系列复杂的特征,包括考虑截词的处理
- 为探测刻意的拼写错误(把watch 写成w4tch)开发复杂的算法
在上面这些选项中,非常难决定应该在哪一项上花费时间和精力,作出明智的选择,比随着感觉走要更好。
我们将在随后的课程中讲误差分析,我会告诉你怎样用一个更加系统性的方法,从一堆不同的方法中,选取合适的那一个。因此,你更有可能选择一个真正的好方法,能让你花上几天几周,甚至是几个月去进行深入的研究。
11.2 误差分析(Error Analysis)
构建一个学习算法的推荐方法为:
- 从一个简单的能快速实现的算法开始,实现该算法并用交叉验证集数据测试这个算法
- 绘制学习曲线,决定是增加更多数据,或者添加更多特征,还是其他选择
- 进行误差分析:人工检查交叉验证集中我们算法中产生预测误差的样本,看看这些样本是否有某种系统化的趋势
假设交叉验证集上有500个邮件样本,其中算法错分了100个邮件,那么我们就人工来检查这100个bad case, 并且按如下的方式对它们进行分类:
- (i) 邮件是什么类型的?
- (ii) 什么样的线索或特征你认为有可能对算法的正确分类有帮助?
数值评估的重要性:
在对bad case进行分析后,我们可能会考虑如下的方法:
- 对于discount/discounts/discounted/discounting 能否将它们看作是同一个词?
- 能不能使用“词干化”的工具包来取单词的词干,例如“Porter stemmer"?
错误分析不能决定上述方法是否有效,它只是提供了一种解决问题的思路和参考,只有在实际的尝试后才能看出这些方法是否有效。
所以我们需要对算法进行数值评估(例如交叉验证集误差),来看看使用或不使用某种方法时的算法效果,例如:
- 不对单词提前词干:5%错误率 vs 对单词提取词干:3% 错误率
- 对大小写进行区分(Mom / mom): 3.2% 错误率
11.3 不对称性分类的错误评估(Error metrics for skewed classes)
什么是不对称性分类?
以癌症预测或者分类为例,我们训练了一个逻辑回归模型. 如果是癌症,y = 1, 其他则 y = 0。
在测试集上发现这个模型的错误率仅为1%(99%都分正确了),貌似是一个非常好的结果?
但事实上,仅有0.5%的病人得了癌症,如果我们不用任何学习算法,对于测试集中的所有人都预测y = 0,既没有癌症。那么这个预测方法的错误率仅为0.5%,比我们废好大力训练的逻辑回归模型的还要好。这就是一个不对称分类的例子,对于这样的例子,仅仅考虑错误率是有风险的。
现在我们就来考虑一种标准的衡量方法:Precision/Recall(精确度和召回率)
首先对正例和负例做如下的定义:
True Positive (真正例, TP)被模型预测为正的正样本;可以称作判断为真的正确率
True Negative(真负例 , TN)被模型预测为负的负样本 ;可以称作判断为假的正确率
False Positive (假正例, FP)被模型预测为正的负样本;可以称作误报率
False Negative(假负例 , FN)被模型预测为负的正样本;可以称作漏报率
| 预测值 | |||
|---|---|---|---|
| Positive | Negtive | ||
| 实际值 | Positive | TP | FN |
| Negtive | FP | TN |
那么对于癌症预测这个例子我们可以定义:
Precision(精确度)-预测中实际得癌症的病人数量(真正例)除以我们预测的得癌症的病人数量:
T r u e p o s i t i v e s p r e d o c t e d p o s i t i v e = T r u e P o s i t i v e T r u e P o s i t i v e + F a l s e P o s i t i v e \frac{True\ positives}{predocted\ positive}=\frac{True\ Positive }{True\ Positive + False\ Positive} predocted positiveTrue positives=True Positive+False PositiveTrue Positive
Precision = TP/(TP+FP)
Recall(召回率)-预测中实际得癌症的病人数量(真正例)除以实际得癌症的病人数量:
T r u e p o s i t i v e s a c t u a l p o s i t i v e = T r u e P o s i t i v e T r u e P o s i t i v e + F a l s e N e g a t i v e \frac{True\ positives}{actual\ positive}=\frac{True\ Positive }{True\ Positive + False\ Negative} actual positiveTrue positives=True Positive+False NegativeTrue Positive
Recall = TP/(TP+FN)
11.4 精确度和召回率的权衡(Trading off precision and recall)
假设我们的分类器使用了逻辑回归模型,预测值在0到1之间:, 一种通常的判断正负例的方法是设置一个阈值,例如0.5:
- 如果 ,则预测为1, 正例;
- 如果 , 则预测为0, 负例;
这个时候,我们就可以计算这个分类器的precision and recall(精确度和召回率):
- Precision = TP/(TP+FP) 例,在所有我们预测有恶性肿瘤的病人中,实际上有恶性肿瘤的病人的百分比,越高越好。
- Recall = TP/(TP+FN) 例,在所有实际上有恶性肿瘤的病人中,成功预测有恶性肿瘤的病人的百分比,越高越好。
这个时候,不同的阈值会导致不同的精确度和召回率,那么如何来权衡这二值?
对于癌症预测这个例子:
假设我们非常有把握时才预测病人得癌症(y=1), 这个时候,我们常常将阈值设置的很高,这会导致高精确度,低召回率(Higher precision, lower recall);
假设我们不希望将太多的癌症例子错分(避免假负例,本身得了癌症,确被分类为没有得癌症), 这个时候,阈值就可以设置的低一些,这又会导致高召回率,低精确度(Higher recall, lower precision);
这些问题,可以归结到一张Precision Recall曲线,简称PR-Curve:
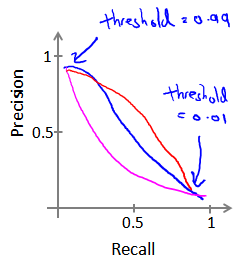
通常我们会考虑用它们的均值来做比较,但是这会引入一个问题,例如上面三组Precision/Recall的均值分别是:0.45, 0.4, 0.51,最后一组最好,但是最后一组真的好吗?如果我们将阈值定的很低,甚至为0, 那么对于所有的测试集,我们的预测都是y = 1, 那么recall 就是1.0,我们根本就不需要什么复杂的机器学习算法,直接预测y = 1就得了,所以,用Precison/Recall的均值不是一个好办法。
我们希望有一个帮助我们选择这个阀值的方法。一种方法是计算标准的F值或者F1-score:
其计算公式为: F 1 S c o r e : 2 P R P + R { {F}_{1}}Score:2\frac{PR}{P+R} F1Score:2P+RPR
我们选择使得F1值最高的阀值。
F值是对精确度和召回率的一个很好的权衡,两种极端的情况也能很好的平衡
11.5 数据对于机器学习的重要性(Data for machine learning)
在设计一个高准确率的机器学习系统时,数据具有多大的意义? 2001年的时候,Banko and Brill曾做了一个实验,对易混淆的单词进行分类,也就是在一个句子的上下文环境中选择一个合适的单词,例如:
For breakfast I ate ___ eggs
给定{to, two, too},选择一个合适的单词。
他们用了如下几种机器学习算法:
- -Perceptron(Logistic regression)
- -Winnow
- -Memory-based
- -Naïve Bayes
根据训练集的不同规模记录这几种算法的准确率,并且做了如下的图:

最终得到的结论是:
“It’s not who has the best algorithm that wins. It’s who has the most data."
选择大数据的理由?
假设我们的特征有很多的信息来准确的预测y, 例如,上面的易混淆词分类的例子,它有整个句子的上下文可以利用;
反过来,例如预测房价的时候,如果仅有房屋大小这个特征,没有其他的特征,能预测准确吗?
对于这样的问题,一种简单的测试方法是给定这样的特征,一个人类专家能否准确的预测出y?
如果一个学习算法有很多的参数,例如逻辑回归/线性回归有很多的特征,神经网络有很多隐藏的单元,那么它的训练集误差将会很小,但容易陷入过拟合;如果再使用很大的训练数据,那么它将很难过拟合,它的训练集误差和测试集误差将会近似相等,并且很小。所以大数据对于机器学习还是非常重要的。