主要内容:
一.Evaluating a hypothesis
二.Model selection and training/validation/test sets
三.Bias and variance
四.Learning curves
五.Precision and recall
一.Evaluating a hypothesis
如何评价模型的好坏?直接绘图以此判断曲线与数据集的拟合程度似乎是一个不错的办法,但是当特征的数量较大时却不能实现,因为我们最多只能看到三维的图像;而且,怎么判断是否为过拟合或者欠拟合,也不能单凭肉眼去观察,而需要一个科学的方法就判断。如下:
1.将数据集分成两部分,第一部分约占70%,称为训练集;第二部分约占30%,称为测试集。注意:两部分的选取需要是随机的,不能带有偏见。
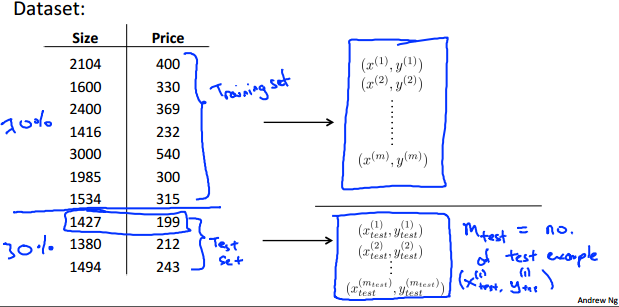
2.训练集,顾名思义就是用于训练参数;同理,测试集就是用于测试已得参数(确切的说是模型)工作的好坏,而评估的工具依然是代价函数,与训练集的代价函数不同的是:此代价函数不需要加上正则项,为什么呢?其实想想正则项的作用就可以很好理解了,正则项的作用就是在训练参数时降低参数的规模,即正则项的作用体现在求参数的过程,既然参数都求出来了,就不需要再加上正则项画蛇添足了。
例子:

二.Model selection and training/validation/test sets
面对一个数据集,我们又多种备选模型,如特征的数量(或指数次数)不同,或者正则项λ的取值不同,形成了不同的模型。那么该如何从中选择一个最合适的模型呢?如下:
1.我们将数据集分成三部分。第一部分约占60%,称为数据集;第二部分约占20%,称为检验集;第三部分约占20%,称为测试集。
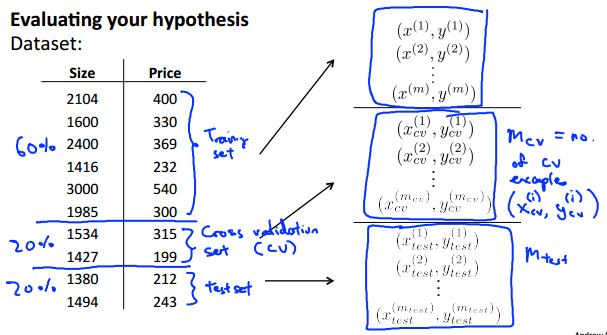
2.训练集用于训练参数;检验集用于评估已得模型的好坏,也是根据这个选择最终模型的;测试集用于测试已选模型工作的好坏。
3.首先利用训练集训练出各个模型的参数;然后再利用检验集评估每个模型工作的好坏程度,并从中挑选出表现最好的模型;最后利用测试集测试已选模型工作的好坏。
4.注意:检验集和测试集的评估和测试工具都是代价函数,并且不需要正则项,原因上文已解释。如线性回归:
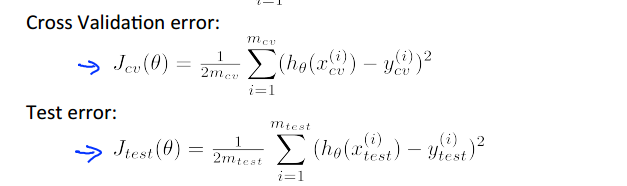
三.Bias and variance、
1.bias对应于欠拟合,variance对应于过拟合。
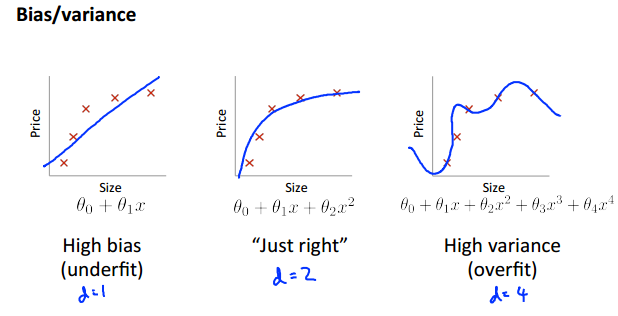
2.当特征的次数从小逐渐变大时,bias和variance所对应的J(train)和J(cv)的情况如下:
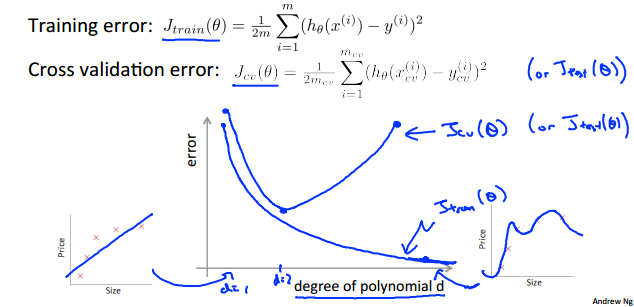

对此的解释是:
1) 对于bias,其所对应的情况是欠拟合。所谓欠拟合,也就是曲线不能很好地拟合训练集,其是由特征过于简单导致的(伸缩性不强,不能“神龙摆尾”)。那么它训练集的代价值就当然大,既然连训练集都不能很好拟合,那更不用说测试集的代价值了。所以对于bias,J(train)和J(cv)较大,且两者较为接近。
2)对于variance,其所对应的情况是过拟合。所谓过拟合,就是曲线好地拟合训练集,所以其J(train)较小,但这样曲意逢迎地讨好数据集,就导致了模型不能很好地运用于训练之外的数据,所以对应的J(cv)就比较大。
四.Learning curves
五.Precision and recall