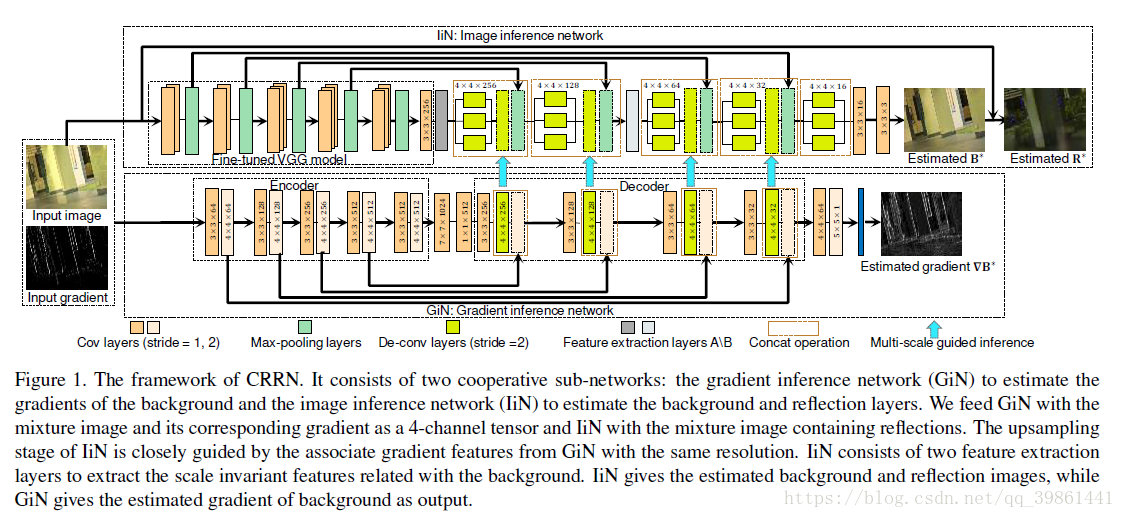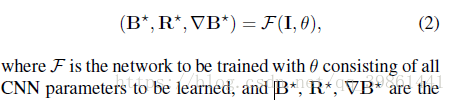

gradient inference network(GiN):输入是4通道张量,它是输入混合图像及其对应梯度的组合.
The image inference network (IiN):以混合图像为输入,提取描述全局结构和高层语义信息的背景特征表示来估计B和R。

GIN网络用的是一个镜像框架结构,即首尾结构对称(分别对应编码和解码结构)。
编码结构由五个卷积层构成,先一个步长1的卷积层,然后再一个步长2的卷积层。这种结构可以很好的逐步提取和降低样本特征。
解码结构:特征升采样,然后组合重建输出没有反射影响的梯度。为了不丢失一些梯度信息,一开始编码的特征信息和解码层的信息相连接(拥有相同的空间分辨率,即图像大小)


最近的研究显示,VG16网络培训高水平计算机视觉中的大量数据任务可以很好地推广到逆成像任务,例如阴影去除(19)和显著性检测。也就是说VGG16不止适用于图像识别,对于生成图像其实也是有很好的效果的!这里他把vgg16原本最后应该的全连接层图换成了3*3的卷积层。然后拿resnet-v2中的结构来做提取特征层。但是在其他地方这个结构一般不被用来做从图像到图像的问题。因为池化层会破坏一些特征信息。所以作者进行了修改,原本模型中的池化层,分别被1*1和7*7的卷积层给替代了。第二所有卷积层的步长都为1.

每个GIN网络中反卷积输出的tensor与liN网络中反卷积输出相级联。

损失函数的定义,用结构相似形来,本来值越高,代表相似性越好,但为了适合网络优化,故用1-.
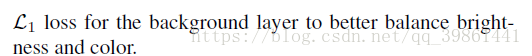
还用了L1 loss来平衡亮度和颜色(即两幅图亮度和颜色的差别也不能太大)

由于gin网络中是边界信息(黑白的),所以这里的损失函数就可以忽略对比度和亮度的差异了,修改前面的SSIM函数,去除其中有关亮度的信息,得到SI.


先GIN网络独自训练40代,学习率为10-4。然后将GIN网络与liN网络一同训练,一开始要收敛快些,所以把学习率调大一些,后面学习率逐渐减小。作者还认为反射只出现在图片中的部分区域。训练那些没有明显反射的部分可能还会引入噪音。为了解决这个问题,就输入不同大小的图像。