论文地址:https://arxiv.org/abs/1803.09894
论文总结
本文的主要贡献是提出了一种结构损失的损失函数,将几个物理相连的肢体关键点连接起来,用于人体姿态估计。肢体是我们所认知的人体结构先验,本文将其利用了起来。可以利用身体结构先验,从可见关键点得到不可见关键点的线索。
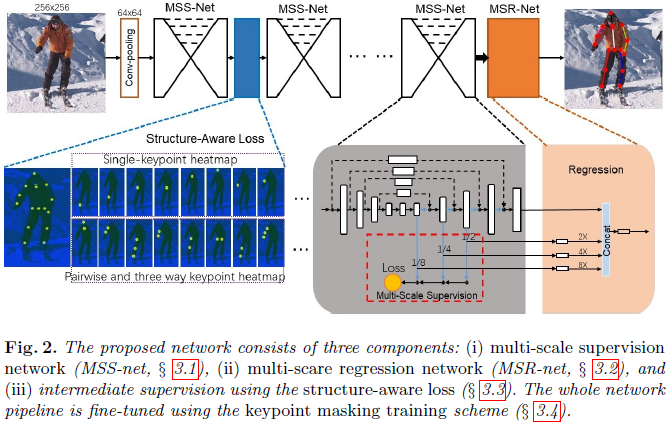
本论文的改进了目前的深层conv-deconv的 hourglass 模型,有四点改进:(1)多尺度监督想法的实践,通过结合跨尺度的特征heatmaps来加强身体关键点的上下文信息;(2)多尺度回归网络,对多尺度特征的结构匹配进行全局优化;(3)结构感知损失(structure-aware loss),用在中间监督和回归中,用于改进关键点和其领域关键点的匹配,从而推断出高阶的结构匹配;(4)关键点masking 训练方案,可有效地增强被遮挡关键点的鲁棒性,通过相邻匹配。这些改进,有效地在当时提升了算法的尺度变化、遮挡和多人场景存在的问题。
本文的整体网络由两个网络组成:多尺度监督网络(multi-scale supervision network,MSS-net)和多尺度回归网络(multi-scale regression network)。其中MSS-Net,使用layer-wise loss在每个deconv上,以监督各个layer上的scale-specific特征。其实就是多尺寸监督,而不是hourglass论文使用的相同尺度的监督,用于学习多尺寸特征。MSR-Net,将来自MSS-Net的多个多尺度keypoint heatmap输出给stacks起来,以得到一个全局关键点回归。
本文的网络结构入下图所示。前面是堆叠的MSS-Net,后面使用MSR-Net回归关键点。应该是在MSS-Net使用结构损失,作者的假设是MSS-Net的输出很可能不是高斯的响应,可能对应多个关节点,这是Hourglass的缺陷问题。在此同时,在MSS-Net的每个deconv上都是用layer-wise的中间监督。
论文介绍
当时最新的hourglss更趋向于过拟合某个特定尺寸,本文介绍的方法可以改善尺寸不稳定问题,利用多尺寸的监督和结合多尺度特征的预测。作者的假设是,在MSS-Net的后面使用结构损失作为中间监督,在MSS-Net的每个deconv上使用多尺寸监督,这样子,在MSR-Net上就可以得到所有尺度的heatmap,就有了全局一致的姿态。这样的MSR-Net不仅匹配了单独的关键点,也匹配了相邻关键点的成对一致性。
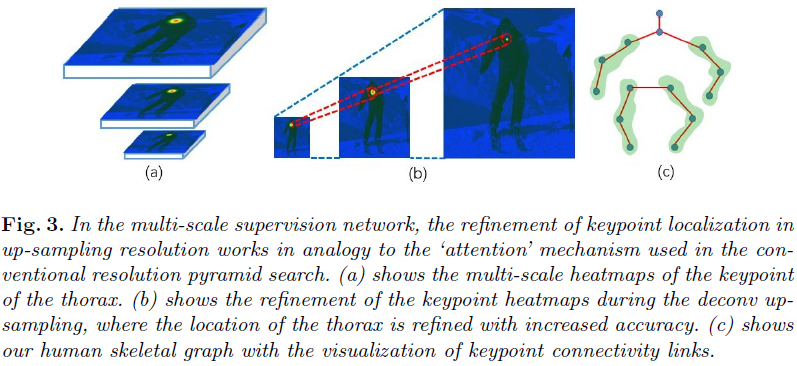
低分辨率产生的heatmap可以相当于高分辨率的attention,如下图所示,可以供以指导refine的方向。这应该也是MSR-Net后面多尺寸监督再concat起来的思想的来源。下图中,a为各尺度下的heatmap,b为上采样heatmap的变化,可看到相对于尺度变化,其heatmap响应值变化更集中,这也增加了准确率。c为对应的人类骨骼拓扑图。
多尺度监督的损失 L M S L_{MS} LMS,就是所有尺度上的 L 2 L_2 L2损失的和: L M S = 1 N ∑ n = 1 N ∑ x , y ∥ P n ( x , y ) − G n ( x , y ) ∥ 2 L_{MS}=\frac1N\sum_{n=1}^N\sum_{x,y}\|P_n(x,y)-G_n(x,y)\|_2 LMS=N1n=1∑Nx,y∑∥Pn(x,y)−Gn(x,y)∥2
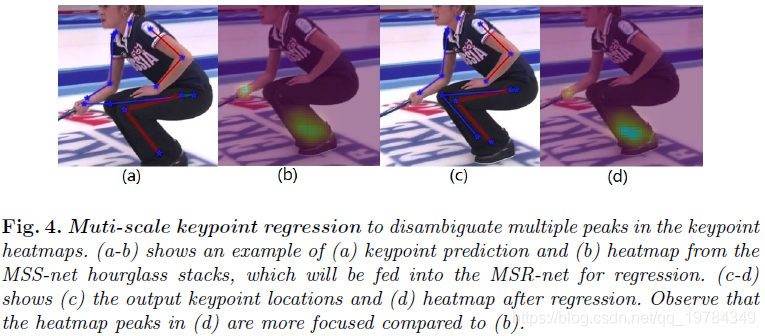
下图是各个结构的某关键点的输出。a是MSS的关键点预测,b是对应a预测的MSS的heatmap,c是MSR的关键点,d是对应MSR的heatmap。
当网络较深的时候,会出现梯度消失现象,可以使用中间监督来缓解。本文设计出了结构损失,其借鉴来源于人体骨骼拓扑结构,将人体骨骼结构中物理相连的关键点结合起来作为连接的关节点。结合起来的关键点设计如下图所示,有三元关键点结合(手臂和腿部,骨盆可以先不三元)和两元关键点结合。
损失函数就变得如下面公式所示,在两个地方使用结构损失:(1)在MSS-Net中作为中间监督,去强迫使用全局信息定位局部关键点;(2)MSR-Net寻找全局的姿态配置。下面的公式中, N N N为关键点的数量, P n P_n Pn表示为单独的关键点, P S n P_{S_n} PSn表示与此点连接的关键点对。 L M S = 1 N ∑ n = 1 N ∥ P n i − G n i ∥ 2 + α ∥ P S n i − G S n i ∥ 2 L_{MS}=\frac1N\sum_{n=1}^N\|P_n^i-G_n^i\|_2+\alpha\|P_{S_n}^i-G_{S_n}^i\|_2 LMS=N1n=1∑N∥Pni−Gni∥2+α∥PSni−GSni∥2
在训练的时候,作者开发了新的关键点masking数据增强方案来增加训练网络的遮挡能力,关键点的遮挡是影响姿态估计性能的一个重要方面。如下图所示,有几种不同的遮挡:被东西遮挡、自遮挡、被其他人遮挡。(a)表示左手腕被遮挡住了,但可以通过可见关键点的连接结构来估计左手手腕的关键点定位。©表示如果有其他人考的比较近,也会造成很大的麻烦。在这种情况下,传统的数据增强方法,如常用的flip、随机裁剪、颜色抖动等都是无效的。为解决这一问题,作者提出了一种关键点masking方法,通过在图片上复制和粘贴关键点的贴片(patches)来增强数据,如下图(d)所示,其主要思想是生成关键点遮挡的训练样本和人工插入的关键点,从而有效提高网络对这些极端情况的学习能力。

两种生成关键点遮挡样本的方法:(1)如上图(b),复制背景的patch放在一个关键点上,这能有效模拟关键点遮挡;(2)如上图(d)所示,复制身体关键点patch在人体附近的北京和是哪个,模拟多人存在的情况。但这种数据增强会导致多个相同的关键点patches,所以成功的姿态估计方法必须依赖于某种结构推理和知识。
实验和分析
训练的时候,先用 5 e − 4 5e^{-4} 5e−4的学习率训练MSS-Net 150 150 150个epoch,当性能不再增长的 8 8 8个epoch后降低 5 5 5倍学习率训练。在训练MSR-Net时,需要固定MSS-Net的参数进行训练。最后,用Keypoint Masking 训练75个epochs。输入图片通过crop后,采用 256 ∗ 256 256*256 256∗256的像素输入。
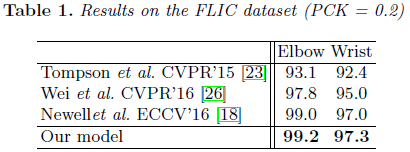
在FLIC数据集与Graphical model、CPN、Hourglass的对比:
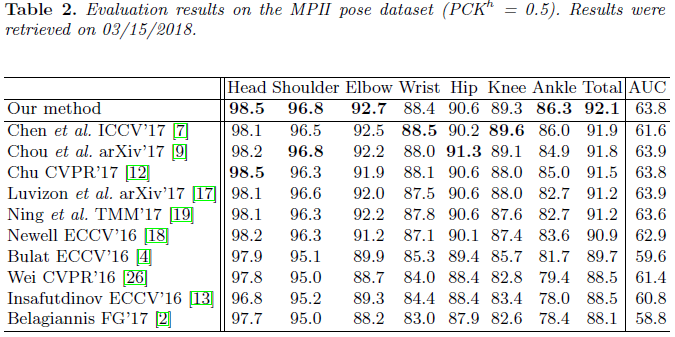
在2018年3月15日的时候,与当时最好的模型,在MPII上的对比。