
本文描述了NPU团队为2020年个性化语音触发挑战赛开发的系统,该系统包含一个语音唤醒(KWS)系统和一个说话人验证(SV)系统,本文暂时重点讨论KWS系统。针对KWS系统,该团队提出了一种多尺度扩张时间卷积(MDTC)网络来检测唤醒字(WUW)。对于SV系统,我们采用了ArcFace损失和有监督的对比损失来优化说话人确认系统。
KWS系统预测音频发声是否包含WUW的后验概率,同时估计WUW的位置。当WUW的后验概率达到预定阈值时,触发段的身份信息由后续的SV系统确定。在评价数据集上,本文提交的系统在近距离交谈和远场任务中分别获得了0.081和0.091的最终分数。
1、引言
关键字检测(KWS)的目的是从音频中检测预定义的关键字,而KWS的一个重要应用是唤醒词(WUW)检测,它通常用于在智能手机、智能扬声器和不同类型的物联网设备等各种设备中触发语音界面。对于一些个人设备,如智能手机、智能手表、耳机,用户通常不希望其他人唤醒他们的设备。为了构建一个只有设备所有者才能触发的个性化无源光网络系统,通常在无源光网络检测后使用说话人验证(SV)模块进行身份验证。SV系统用于识别测试话语是否与说话人的登记话语匹配,并相应地接受或拒绝说话人的身份声明。
2、KWS系统
2.1 MDTC网络结构
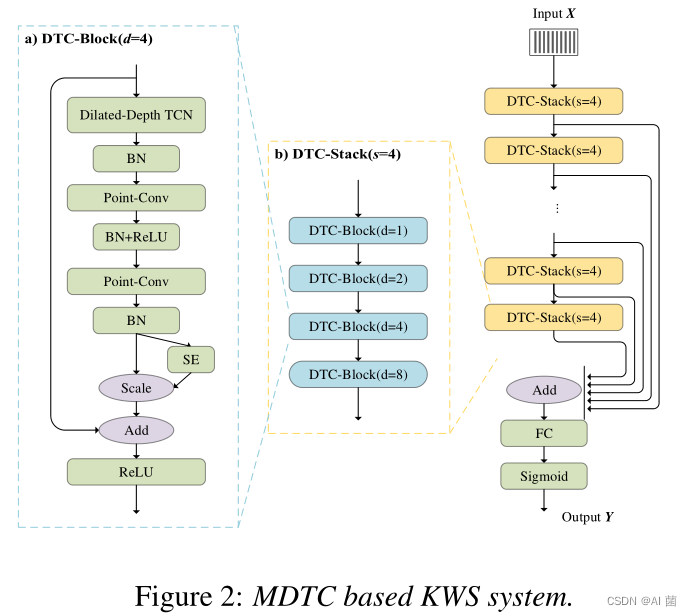
为了在我们的关键词检测器中对声音序列进行建模,提出了一种多尺度膨胀时间卷积(MDTC)网络。图2(A)中显示了一个基本块,即DTC块。首先,使用膨胀深度1D卷积网络(Dilated-Depth TCN)来获得时间上下文,其中卷积核大小为(5*1),并且可以相应地设置膨胀率。由于采用了简单的纵深一维卷积,大大减少了训练参数的个数和计算量。
在扩展深度TCN之后,使用两层逐点卷积(Point Conv)来整合来自不同通道的特征。我们在不同卷积层之间插入批归一化(BN)和RELU激活函数。此外,我们在最后的Point Conv层之后增加了一个挤压和异常(SE)模块,以学习不同通道之间的注意力信息。为防止梯度消失和梯度爆炸,还采用了输入和最后一个REU激活函数之间的残差连接。四个DTC块被堆叠以形成DTC堆栈,如图2(B)所示。四个DTC块的膨胀率分别设置为1、2、4和8。
每个DTC堆栈的感受野为60帧。在我们提交的系统中,我们使用4个DTC堆栈作为特征提取。特征抽取器的感受场为4∗60=240帧,足以模拟一个WUW。我们从具有不同接受域的DTC堆栈中提取特征映射,并将其汇总为关键词分类器的输入。对于关键词分类器,使用简单的全连通层,然后是Sigmoid输出层来预测WUW的后端。
2.2 标签与损失函数
对于正向训练语音,我们在WUW区域的中间帧周围选取最多40帧作为正向训练样本,并为其标签分配1。正向训练发声中的其他帧作为歧义被丢弃并且不在训练中使用。对于负样本训练话语,所有帧都被视为负训练样本,标签被分配到0。因此,我们的KWS系统被建模为一个序列二进制分类问题。为了训练模型,使用二进制交叉熵(BCE)损失:
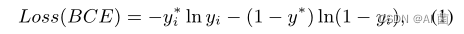
2.3 数据增强
我们扩充了挑战的原始训练集,这对于我们的系统推广到开发集以及评估集是至关重要的。对于原始训练数据,关键字总是出现在话语的开头,而话语的其余部分是同一说话者所说的语音。对于评估集,关键字总是出现在话语的末尾,并且在该关键字之前可能存在来自其他说话者的语音。仅用原始训练数据来训练我们的模型,很难将模型推广到开发和评价集,导致召回率很低。
正向关键词训练集由以下几部分组成:
-
- 训练肯定话语中的关键词片段;
-
- 随机选择非关键词语音片段并填充在1)中的上述关键词片段之前;
-
- 在1)中的上述关键词片段之前和之后填充非关键词语音片段;
此外,我们还创造了更多的负面训练话语。具体的策略是将关键词中间帧3)中的正面话语切成两个片段,然后用作负面训练样本。这种反例也可以提高模型的泛化能力。
Speaugment也被应用于训练中,这是首次提出用于端到端(E2E)ASR以缓解过度拟合,最近被证明在训练E2E KWS系统中也是有效的。具体地说,我们在训练中应用了时间和频率掩蔽。我们随机选择0−20个连续帧,并将其所有MEL滤波器组设置为零,以进行时间遮罩。对于频率掩蔽,我们随机选择80个MEL滤波器组的0−30个连续维度,并将它们的值设置为说话的所有帧的零。
3、实验结果
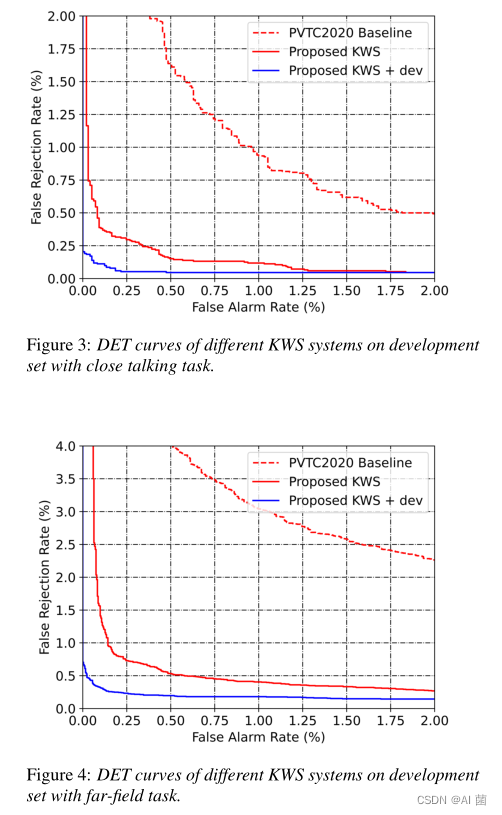
图3和图4显示了开发集上不同KWS系统的DET曲线。我们根据官方源代码复制官方的KWS系统(图3和图4中的‘PVTC2020基线’)。与PVTC2020基准相比,我们提出的KWS系统在近距离通话和远场任务中都获得了明显更好的DET曲线。
使用主频为2.4 GHz的Intel®Xeon®E5-2620 v3 CPU对系统的推理效率进行了评估。我们的KWS模型有大约180k个参数。在评估集上,我们的KWS子系统的归一化实时因子(RTF)为0.05,即1秒音频处理时间大概需要50ms。
4、结论
本文介绍了我们提交给PVTC2020的个性化语音触发系统。我们的系统由KWS系统和SV系统组成。KWS系统和SV系统是独立优化的,但最终合作良好。对于KWS系统,提出了一种新颖的MDTC网络,并采用了数据增强策略。对于SV系统,我们利用ArcFace损失和监督对比损失对基线系统进行了修正,结果表明这对提高系统的性能是有效的。在评估数据集上,我们提交的系统在近距离交谈和远场任务中分别获得了0.081和0.091的最终分数。未来我们将重点关注KWS和SV系统的联合优化,我们相信这将带来明显的性能提升。