文章于2017年6月提交到Arxiv,投稿于 Neuroinformatics (2018),Published online: 3 May 2018
作者单位:Department of Computer Science and Engineering,Lehigh University
文章截止2019.3.25的引用量为50
文章代码见github
这篇文章主要的创新点在于不同于之前的公式化loss,作者设计了一个可以进行学习的loss函数(一个神经网络的输出作为loss);并借鉴GAN训练的思路,采用min-max的对抗学习模式来训练segment网络和loss网络,得到了当前(2017年)state-of-art的分割结果。此外,作者没有直接用预测图与ground truth二值图计算loss,而是分别利用它们对原图进行掩膜后再计算loss,也是一个很好的idea。
问题的提出
首先,作者提出了一个问题:在医学图像分割中,当前(2017年)state-of-art的网络结构Unet存在的一个问题是无法有效解决图像中像素类别不平衡的问题。针对这个问题,之前有人提出过用weighted cross-entropy loss来进行优化,但是作者认为这个weghted loss 的问题是 task-specific 以及难以优化的。
作者基于上述问题,并借鉴了GAN的思路,设计了新的分割网络,并提出了Multi-scale L1 Loss来优化分割网络。
网络结构
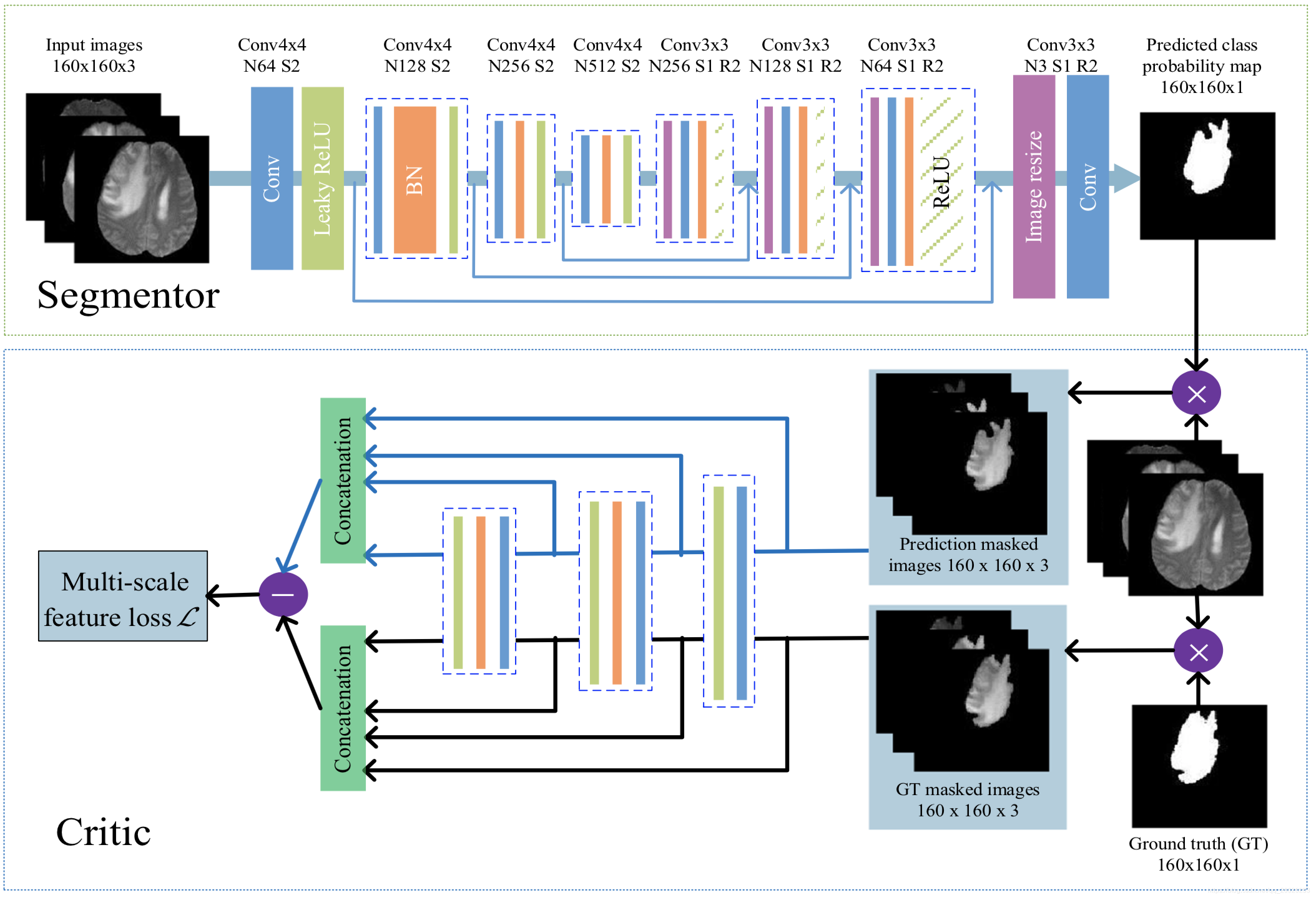
整个网络分为segmentor和critic两部分:
1、segmentor部分为普通的unet结构,encoder部分为4层stride=2的卷积,decoder部分为4层upsample,输出为网络预测的肿瘤二值图像;
2、critic部分的网络共用segmentor部分encoder的前三层,分别向critic部分输入经预测的肿瘤二值图掩膜的原始输入图像,以及经真值肿瘤二值图掩膜的原始输入图像,最后的loss计算两个不同输出之间的MAE值(L1 loss)。其中Multi-scale体现在对critic部分每一个卷积层输出的特征图像都计算MAE值,最后的总loss取平均。
3、训练方式类似于GAN的min-max对抗学习过程。首先,固定S(segmentor),对C(critic)进行一轮训练;再固定C(critic),对S(segmentor)进行一轮训练,如此反复。对 critic 的训练想使loss变大(min),对 segmentor 训练想使loss变小(max)。
其loss函数如下式所示:

训练的稳定性与收敛性证明
1、首先定义几个概念:
表示从输入图像的紧空间到输出分割图的紧空间的映射。
表示上述映射
的估计,即为segmentor
表示从输入图像的紧空间到真值分割图的紧空间的映射。即理想最优的segmentor
2、接着证明一个关于Lipschitz 连续性的引理:

3、最后证明网络训练稳定且收敛:

( 详细证明过程见原文章 )
实验结果
在Brats13和Brats15数据集上进行了实验,目标是分割出脑部MRI影像中的3类肿瘤,评价指标为DICE分数。
数据集中包含有T1、T1c、T2、Flair四个模态,作者实验中只使用T1c、T2、Flair三个模态作为输入,因为发现这对最后的结果没有明显影响,且节约了显存。
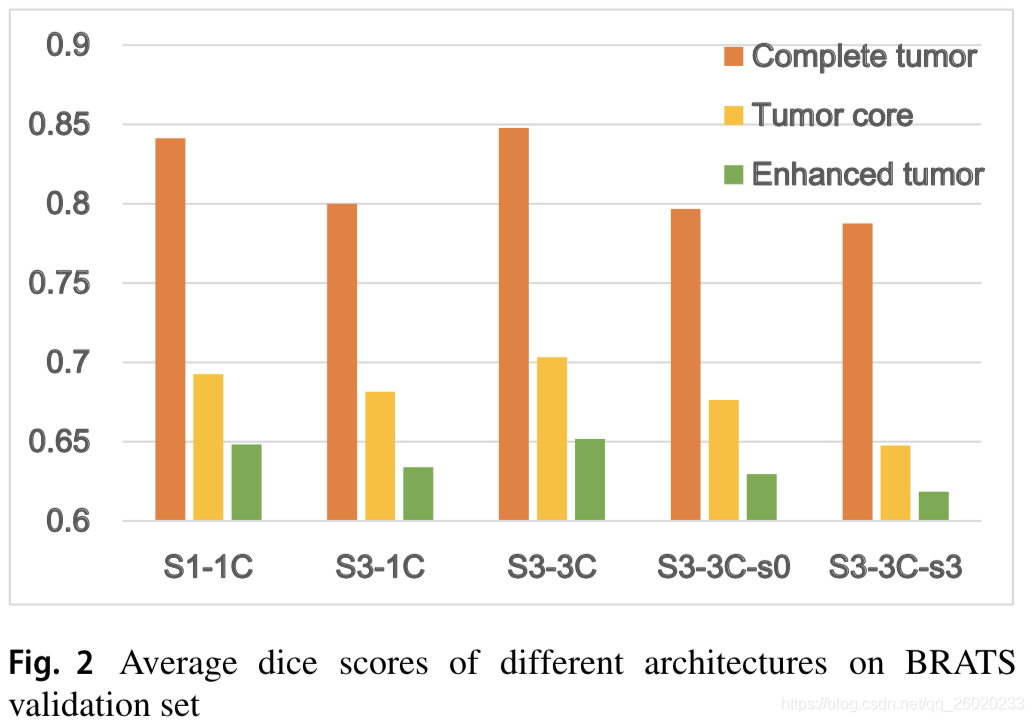
作者探究了不同的segmentor、critic的组合搭配,包括:
1、S1-1C:每个S1-1C网络分割一类肿瘤,需要分别训练三个独立的S1-1C;
2、S3-1C:S3-1C中segmentor输出三个通道,分别对应三类肿瘤的预测图,但critic只有一个
3、S3-3C:与S3-1C相比,使用3个不同的critic来评价不同类别肿瘤的分割结果
4、S3-3C:single scale:与S3-3C相比,loss计算只使用单一scale。其中S3-3C-s3为只使用critic的第三层输出特征图计算loss,S3-3C-s0为只使用critic的输入层计算loss。
比较结果如下,S3-3C最优:
与state-of-start比较结果如下:
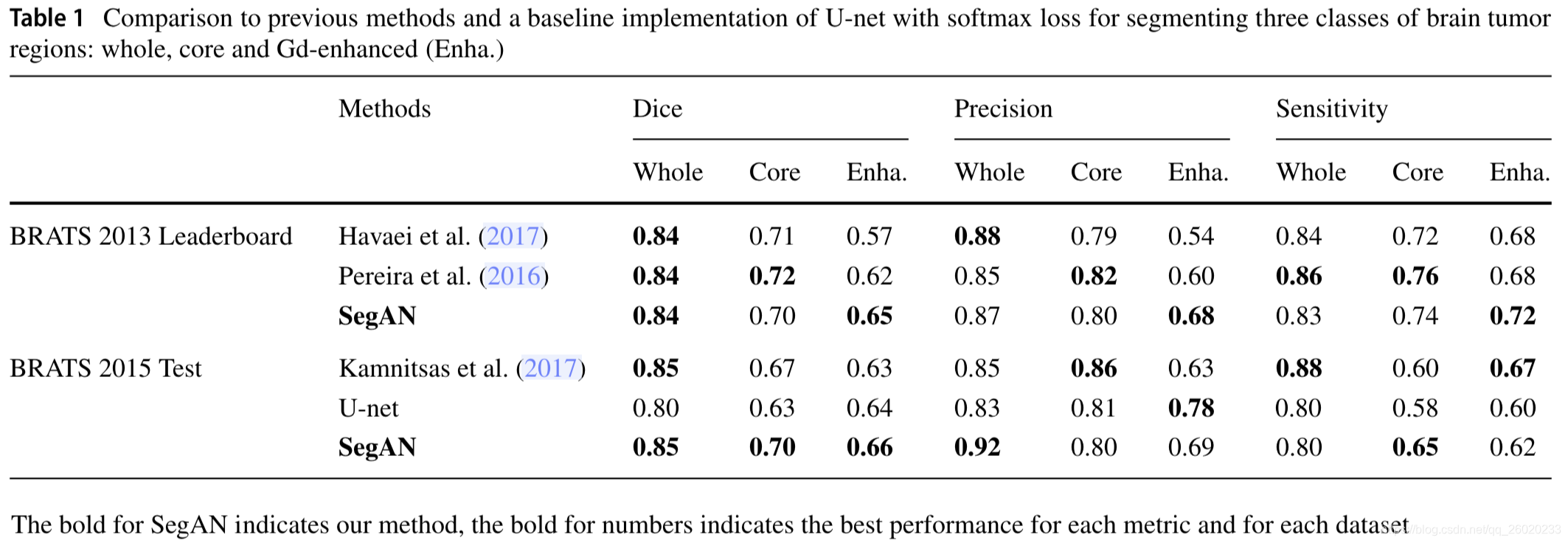
(其中用于比较的U-net结构与segmentor的结构完全一样,只是loss由softmax loss变成了提出的Multi-scale L1 Loss,从这两者DICE的差别可以看出引入的loss对segmentor的提升效果比较明显)
讨论:该方法与GAN的关联
首先我们来看一下基础的GAN的训练方式
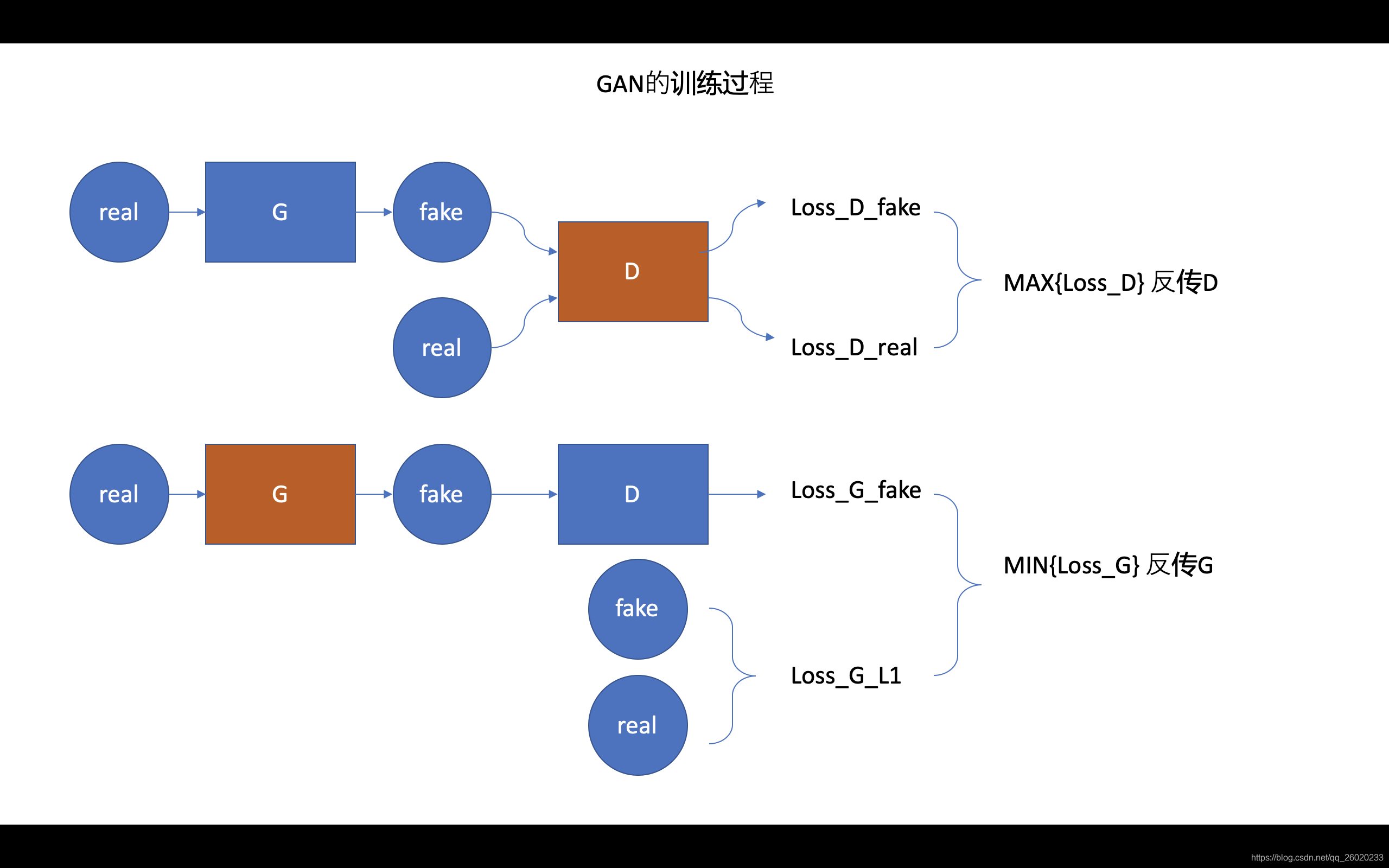
再来看本文网络的训练方式:
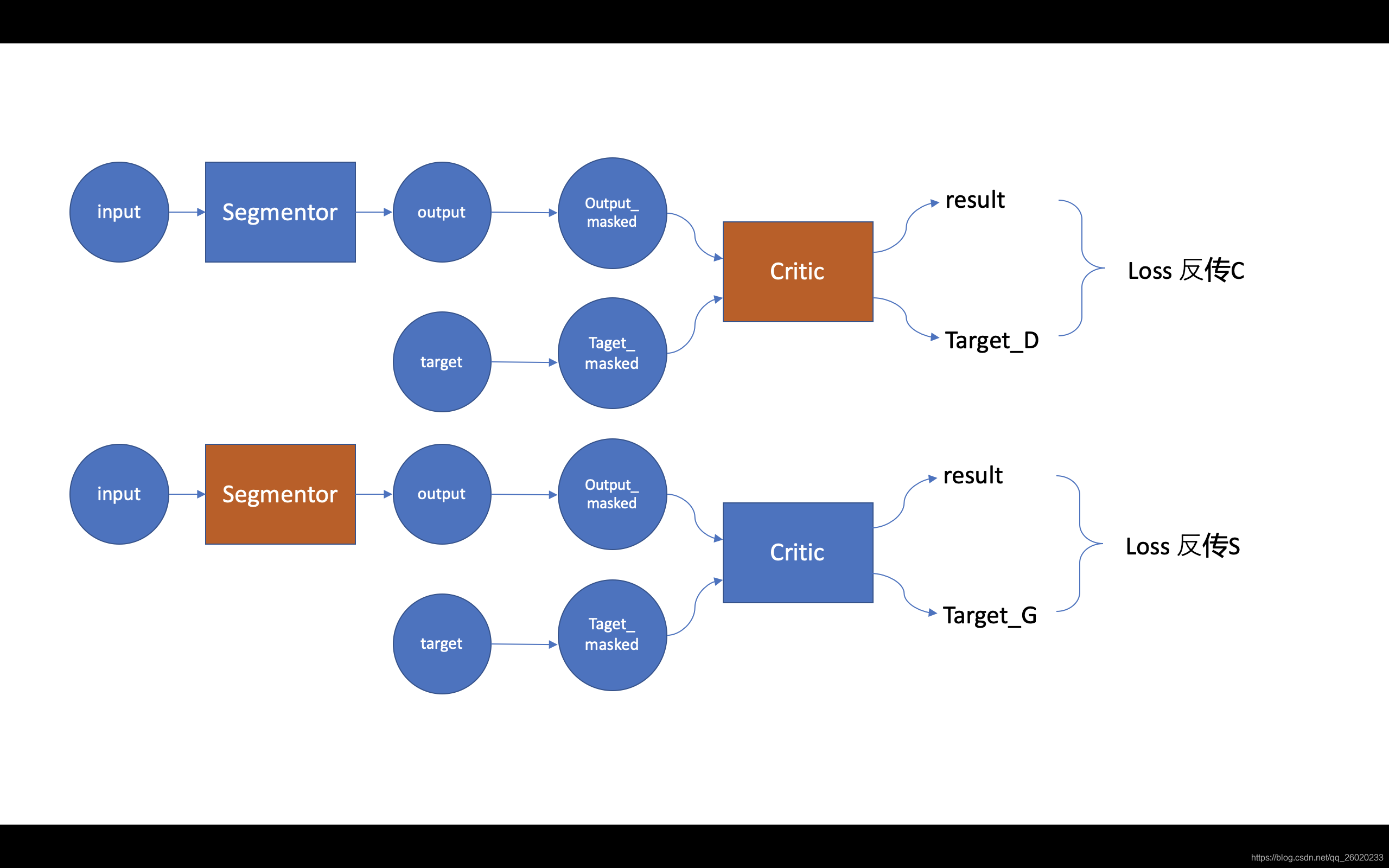
可以看出两者的训练过程很相似,而且因为本文网络用于分割任务,使得无论是反传S还是C,计算的loss都是相同的。作者认为S和C使用相同的loss以及multi-scale的计算形式(有更丰富的梯度信息反传)使得整个对抗学习更加稳定。
我比较希望的是,作者再添加一个比较:网络按传统方式训练和按对抗方式训练。比较好奇这种对抗学习的方式带来了多大增益。
文章作者公式推导证明了L1 norm可稳定收敛,但没有对L2 norm进行相关证明。作者尝试性使用 L2 norm 代替L1 norm,模型不稳定且难以收敛,但并没有排除L2 norm可能稳定的潜能。
最后,作者提到,目前该模型的缺点:1、对小的分割区域,比起使用pixelwise loss还有些差距;2、对多类别分割任务而言,该模型太大;