- Instace-sensitive Fully Convolutional Networks.ECCV 2016【2016.3月上传到arxiv】
- R-FCN:Object Detection via Region-based Fully Convolutional Networks.NIPS 2016【2016.7月上传到arxiv】
- Fully Convolutional Instance-aware Semantic Segmentation.xxxx 2017【2016年11月上传到arxiv,MSCOCO2016的第一名】
一、InstaceFCN【Instace-sensitive Fully Convolutional Networks.ECCV 2016】
先来说这篇工作是针对什么问题:FCN网络只能产生semantic segmentation的结果,也就是说同样的物体类别,它不会区分物体实例【可以理解为两个人挨在一起的话,FCN输出的mask标记的都是people,但是instance-aware要求区分出来这两个人各自。我认为instance semantic segmentation =semantic segmentation + object detection】之前的instance semantic segmentation方法通常诉诸于现成的分割proposal方法,本文打算一次性解决。
FCN为每一个物体类生成一个score map,map上每个pixel代表一个分类器(是不是这类物体),本文的方法为每一个物体类生成一系列instance-sensitive的score maps,map上每个pixel代表一个分类器(是不是在此类的一个物体实例的某个相对位置上)
1.网络结构
首先来看网络结构:

Image用VGG16的结构得到conv feature map,这里做了改动,把pool4的stride改为1,conv5的三个卷积层的filter都用dilated的,所以一个W*H大小的image会得到W/8*H/8大小的conv feature map。接着这个conv feature map走了两个并行的分支:一个分支负责估计segment instance,另一个分支负责对这个instance进行打分。
分支1:先经过1*1*512的卷积层生成W/8*H/8*512的输出【降维】,然后经过3*3*(k*k)的卷积层生成一系列Instance-sensitive score maps,也就是说一共有k*k个大小为W/8*H/8的score map喔~然后经过assembling模块,产生score map上m*m大小的sliding window内的object instance。
分支2:先经过3*3*512的卷积层生成W/8*H/8*512的输出,然后经过1*1*(k*k)的卷积层输出objectness score map,map上的每一个分数是以这个像素为中心的sliding window是否有一个实例。【这个objectness score map的大小是多少啊???】
- Instance-sensitive score maps
- Instance assembling module
2.有一些疑问
Instance-sensitive score maps的大小是W/8*H/8的,网络是按照每个m*m大小的sliding window来生成它的segment instance和instance score的,那么整个score map以及整个image【W*H啊啊啊】范围内的segmentation结果是怎么得到的呢????

我想一个合理的解释可能是:
这里的输入sliding window并不是由proposal method产生的,而是论文作者指定的:
1 假设k*k个instance score maps大小为W/8*H/8(同样的,scoring分支的objectness score map的大小也是W/8*H/8)
2 instance score maps上的每个pixel都产生一个以它为中心的sliding window,其大小为m*m(论文里m=21)
3 每个pixel,假设是(i,j)坐标位置的,根据它的sliding window(已经是投影在feature map上的sliding window了,这个需要注意,而不是从原图的sliding window投影到feature map上的),输出其instance-level的mask。
4 那么在objectness score map上对应的(i,j)位置的值,就是这个pixel的instance-level mask的objectness score【由此可以看出这个score不是class-specific的,它只是指出是否是物体】。
5 一共有W/8*H/8个mask和对应的object score,最后通过非极大值抑制方法留下那些合理的
但是楼主还有一个问题没有解决,最后得到的是在W/8*H/8个mask尺度上的mask,本篇paper也没说怎么变成整张image的mask呀,难道像DeepMask一样就用一个简单的双线性内插上采样??
--------------------------------------------------------我是分割线喵~------------------------------------------------------------
二、R-FCN【R-FCN:Object Detection via Region-based Fully Convolutional Networks.NIPS 2016】
先来说这篇工作是针对什么问题:首先,目前基于region proposal的物体检测框架存在一个问题就是会有subnetwork的重复计算,什么意思呢?我们回忆一下Faster RCNN,整张image计算conv feature map,然后通过ROI pooling把每一个region proposal变成一个大小固定的feature map,再经过若干次fc层得到结果,此时subnetwork指的就是这些分成层。假设一张image有N个region proposal,那么subnetwork的计算也会有N次,本文的想法就是丢掉这些fc层,使得所有的计算都可以由region proposal共享【博主一度不是特别理解这个共享的意义,但是最近突然开窍了,说一下我的看法。先说有fc层的情况下不能共享是因为,每个region proposal都得自己计算,但是卷积就不一样了:一张image只需要计算一次卷积流程得到一个conv map,然后对应不同region proposal,只需要“找到”它对应的conv map的位置就好了呀,没有多余的计算】。
对于上面的问题,一些解决方案是在两个卷积层集之间加一个ROI pooling层,前面的卷积共享,后面的不共享。本文认为这种做法是为了消除一对矛盾:分类时希望对位置不敏感【卷积就是不敏感的】,检测时又希望是translation-variant的【ROI pooling的作用就在此。顺便说一句fc层也是为了达到这个效果】。但是这样做呢,也牺牲了训练和测试的效率,因为引入了很多region-wise层。
所以为了解决这个问题,本文最大的亮点来了:position-sensitive score maps和position-sensitive RoI pooling
1.网络结构
首先来看网络结构:
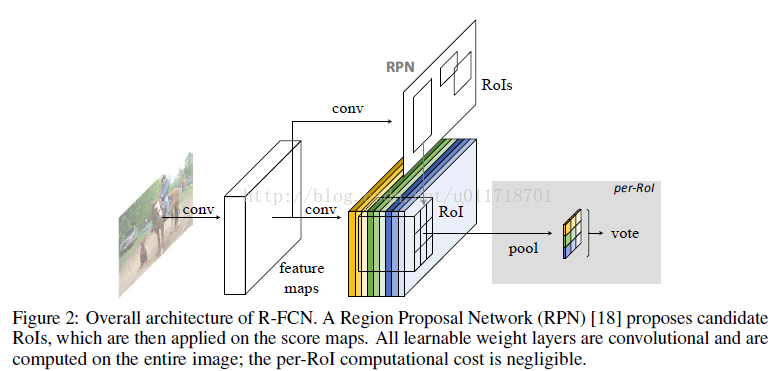
Image先经过FCN生成conv feature map【本文选择的是ResNet-101,去掉最后的fc和average pooling层,然后接一个1*1的1024维的卷积降维,所以conv feature map的大小是W/8*H/8*1024】,这个feature map兵分两路:
(1)经过3*3和1*1卷积层生成ROI【也就是Faster R-CNNhttp://blog.csdn.net/u011718701/article/details/53758927里的RPN网络啦~】
(2)经过一系列特殊的卷积层生成position-sensitive score map集合,一共有k*k个score map,每个score map都是C+1维的(C是物体类别,1代表背景类),代表着一个相对位置上的score结果(比如物体的左上方啊,右方啊之类的)。然后结合RPN生成的ROI经过position-sensitive的ROI pooling层,生成这个ROI的检测结果。所谓position-sensitive pooling就是说,pooling只在某个位置的(C+1)维的score map中进行,然后放在对应的位置上。【对照结构图来看就是,橘色的score map内部进行pooling,跟其他颜色的没有关系】,还有更数学性的解释:
把每个w*h大小的ROI分成k*k个bin,每个bin的大小是w/k*h/k*(C+1)的,在第(i,j)个bin里,定义一个只在这个bin里进行的position-sensitive RoI pooling操作,本文用的是average pooling啦~即第(i,j)个bin的输出值是这个bin里所有位置score map的均值。对照图,每个颜色代表一个(i,j)bin,这样下来我们就得到了k*k个按照位置排列的通道数为C+1的score map啦~然后这k*k个scores就要来投票啦,本文的投票方式就是取均值,得到C+1维的向量,然后softmax处理一下,那么得到的就是这个ROI是各类别的概率了~
2.Bounding box regression
bbox回归又是物体检测框架下一个必不可少的环节,我们来看本文的处理方式:
前面部分和主网络都一样,从那个conv feature map开始。和k*k*(C+1)维的score maps并行,接上一个k*k*4维的卷积层,也就是说得到的maps一共是k*k个,每个map是4维的【因为是bbox嘛,中心坐标和长度宽度,所以是4】。然后每个w*h大小的ROI接position-sensitive RoI pooling层,那么每个RoI就得到了4*k*k的向量呀。再通过取均值的投票方式,得到4维的向量了,也就是bbox regression的结果~
3.一些细节
ResNet-101一共有5个conv block,原来的网络,一张W*H的image会输出W/32*H/32的conv feature map,现在本文做了改动,把conv5层第一个层的stride变成1,所有conv5层的卷积都用dilated,这样conv feature map的大小就变成了W/16*H/16。
还有就是,RPN网络生成的RoI的尺寸可是在原image上的,所以它需要投影到大小为W/16*H/16的score maps上,bbox regression的结果是基于尺寸W/16*H/16的,所以它需要反投影到原image上。【大家不要被它的网络结构图蒙蔽了.....feature map、score map的大小它画的跟原image一样,这太过分了。。。根本就不一样啊。。。】
------------------------------------------------------------我是分割线喵~--------------------------------------------------------------------------
三、FCIS【Fully Convolutional Instance-aware Semantic Segmentation.xxxx 2017】
据作者说,这是第一篇fully sonvolutional end-to-end的解决方案来完成instance-aware segmentation任务的,也是MSCOCO2016数据集上的第一名~
是基于InstaceFCN【Instace-sensitive Fully Convolutional Networks.ECCV 2016】这篇的工作。作者指出InstanceFCN只是用来产生mask proposal,不能区分semantic类别,而且需要一个downstream网络进行分类,也就是说它的mask proposal和classification两个子任务是分离的,因此不是end-to-end的方法。还有就是它操作的是正方的、固定大小的sliding window,所以找不同尺寸物体的时候要用image pyramid scanning,非常耗时。本文在InstanceFCN的基础上做改进,一方面用box proposal代替sliding window,另一方面把mask proposal和classification网络融合起来~
1.网络结构
首先来看网络结构:

重点关注两个改进:
- position-sensitive inside/outside score maps
- joint mask prediction and classification
2.Bounding box regression
但凡是自己产生RoI的,bbox回归又是必不可少的:
前面部分和主网络都一样,从那个conv feature map开始。和2*k*k*(C+1)维的score maps并行,接上一个1*1*4*(k*k)的卷积层,输出维度是4*(k*k)。然后每个w*h大小的RoI接position-sensitive RoI pooling层,那么每个RoI就得到了4*k*k的向量呀。再通过取均值的投票方式,得到4维的向量了,也就是这个RoI进行bbox regression的结果~
3.Inference and Training
Inference:对一张image,先从RPN生成的RoI里面选出分数最高的300个,它们经过bbox regression分支,产生另外300个RoI,所以一共是600个RoI。对每一个RoI,得到它在各个类别的classification score和前景mask。用IoU阈值为0.3的非极大值抑制过滤掉高度重叠的RoIs,剩下的RoI就被分类为有最高classification score的类别呗~它们的前景mask通过mask voting的方式来获取:比如对某个RoI,我们从600个RoI中找到与它的IoU大于0.5的那些,每一个RoI在这个RoI类别的mask进行逐像素加权平均,权值是各自RoI在该类的classification score。平均后的mask再二值化作为输出。【二值化的阈值怎么确定的咯?cross-validation?】
Training:先说RoI的正负标签怎么确定,如果一个RoI与离它最近的ground-truth的IoU大于0.5就是正的【也就是说是物体】,否则就是负的。每个RoI有三个loss项目:softmax classification loss over C+1个类别;softmax segmentation loss overground-truth类别的前景mask;bbox regression loss。后面两个loss仅仅针对标签为正的RoI计算诶。训练图像最短边规定为600像素。
2.Bounding box regression
bbox回归又是物体检测框架下一个必不可少的环节,我们来看本文的处理方式:
前面部分和主网络都一样,从那个conv feature map开始。和k*k*(C+1)维的score maps并行,接上一个k*k*4维的卷积层,也就是说得到的maps一共是k*k个,每个map是4维的【因为是bbox嘛,中心坐标和长度宽度,所以是4】。然后每个w*h大小的ROI接position-sensitive RoI pooling层,那么每个RoI就得到了4*k*k的向量呀。再通过取均值的投票方式,得到4维的向量了,也就是bbox regression的结果