个人觉着RFCN系列的工作还是非常好的,所提出的position sensitive score maps 非常有启发性,包括本文的一些工作都是有很高的价值的。
主要涉及的论文
[1] Instance-sensitive Fully Convolutional Networks
[2] R-FCN: Object Detection via Region-based Fully Convolutional Networks
[3] Fully Convolutional Instance-aware Semantic Segmentation
1. Position sensitive score maps
以往featuremap 直接根据输入进行学习,每个channel所学习的特征对应位置都是同一像素的映射,而本文提出的position-sensitive score maps,每个channel所学习的特征都与不同的位置相关。
在R-FCN中:
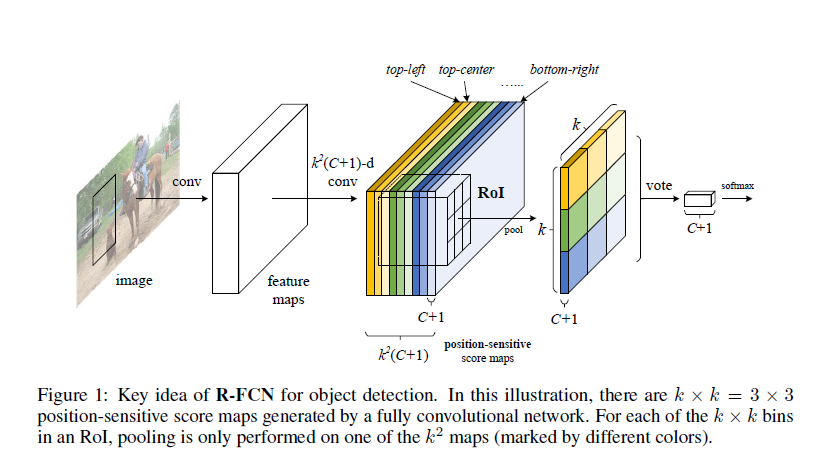
具体请看之前的一篇文章,Position sensitive score maps 共

而在fcis中:
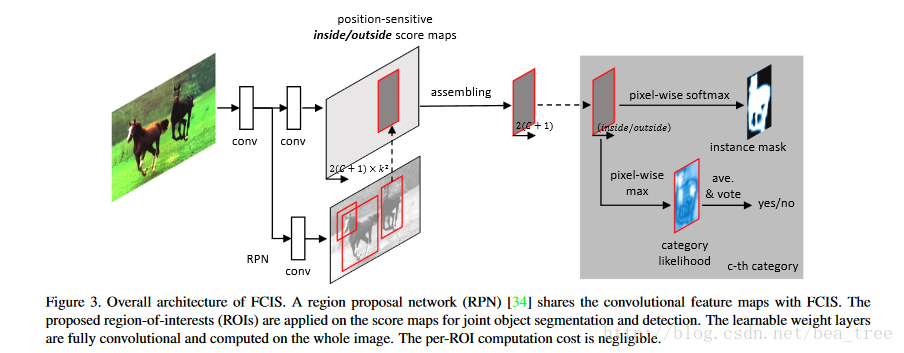
原本
fcis bbox regression 得到的channel是
2 Joint Mask Prediction and Classification
如何利用这里的
首先对于classification:
classification首先进过Grope_max的操作,输出【num_rois, group,h,w】 维数据,得到的是inside和outside之间的最大值,然后将经过softmax进入loss,inference的时候同样得到一个softmax的class的prob。
下面的代码,不想看的请略过。
层的定义
////////////////////////////////
psroipool_cls = mx.contrib.sym.ChannelOperator(name='psroipool_cls', data=psroipool_cls_seg, group=num_classes, op_type='Group_Max')
cls_score = mx.sym.Pooling(name='cls_score', data=psroipool_cls, pool_type='avg', global_pool=True, kernel=(21, 21))
cls_score = mx.sym.Reshape(name='cls_score_reshape', data=cls_score, shape=(-1, num_classes))
////////////////////////////////
前传
namespace cuda {
template <typename DType>
__global__ void GroupMaxForwardKernel(
const int count,
const DType* bottom_data,
const int channels,
const int group,
const int channels_in_group,
const int spatial_dim, //height * width
DType* top_data,
DType* max_idx_data) {
CUDA_KERNEL_LOOP(index, count) {
int s = index % spatial_dim;
int g = (index / spatial_dim) % group;
int n = index / spatial_dim / group;//num_rois
DType max_val = -FLT_MAX;
int max_idx = -1;
for (int i = 0; i < channels_in_group; ++i) {
int c = g*channels_in_group + i;
int bottom_index = (n*channels + c)*spatial_dim + s;
if (bottom_data[bottom_index]>max_val) {
max_val = bottom_data[bottom_index];
max_idx = c;
}
}
top_data[index] = max_val;
max_idx_data[index] = max_idx;
}
}
template<typename DType>
inline void GroupMaxForward(const Tensor<gpu, 4, DType> &out,
const Tensor<gpu, 4, DType> &data,
const Tensor<gpu, 4, DType> &max_idx,
const int group) {
// LOG(INFO) << "GroupMaxForward";
const DType *bottom_data = data.dptr_;
DType *top_data = out.dptr_;
DType *max_idx_data = max_idx.dptr_;
const int count = out.shape_.Size();
const int channels = data.size(1);
const int height = data.size(2);
const int width = data.size(3);
const int spatial_dim = height * width;
const int channels_in_group = channels / group;
cudaStream_t stream = Stream<gpu>::GetStream(out.stream_);
GroupMaxForwardKernel<DType> << <mxnet::op::mxnet_op::cuda_get_num_blocks(count),
kBaseThreadNum, 0, stream >> >(
count, bottom_data, channels, group,
channels_in_group, spatial_dim, top_data, max_idx_data);
ChannelOperator_CUDA_CHECK(cudaPeekAtLastError());
}其次,对于mask:
mask在train时,进过Label_Pick得到的是ground truth类别的inside和outside score map,输出shape为:【num_rois, 2, h, w】,然后求softmax loss。
/////////////////////////////////////////////
label_seg = mx.sym.Reshape(name='label_seg', data=label, shape=(-1, 1, 1, 1))
seg_pred = mx.contrib.sym.ChannelOperator(name='seg_pred', data=psroipool_cls_seg, pick_idx=label_seg, group=num_classes, op_type='Group_Pick', pick_type='Label_Pick')
////////////////////////////////////////////
template <typename DType>
__global__ void GroupPickForwardKernel(
const int count,
const DType* bottom_data,
const int channels,
const int group,
const int channels_in_group,
const int spatial_dim,
DType* top_data,
const DType* pick_idx_data) {
CUDA_KERNEL_LOOP(index, count) {
int s = index % spatial_dim;
int c = (index / spatial_dim) % channels_in_group;
int n = index / spatial_dim / channels_in_group;
int g = pick_idx_data[n];
int bottom_index = (n*channels + g*channels_in_group + c)*spatial_dim + s;
top_data[index] = (g < group && g >= 0) ? bottom_data[bottom_index] : DType(0);
}
}
template<typename DType>
inline void GroupPickForward(const Tensor<gpu, 4, DType> &out,
const Tensor<gpu, 4, DType> &data,
const Tensor<gpu, 4, DType> &pick_idx,
const int group) {
// LOG(INFO) << "GroupPickForward";
const DType *bottom_data = data.dptr_;
DType *top_data = out.dptr_;
const DType *pick_idx_data = pick_idx.dptr_;
const int count = out.shape_.Size();
const int channels = data.size(1);
const int height = data.size(2);
const int width = data.size(3);
const int spatial_dim = height * width;
const int channels_in_group = channels / group;
cudaStream_t stream = Stream<gpu>::GetStream(out.stream_);
GroupPickForwardKernel<DType> << <mxnet::op::mxnet_op::cuda_get_num_blocks(count),
kBaseThreadNum, 0, stream >> >(
count, bottom_data, channels, group,
channels_in_group, spatial_dim, top_data, pick_idx_data);
ChannelOperator_CUDA_CHECK(cudaPeekAtLastError());
}inference 的时候没有groundtruth,会先经过Group_Softmax,然后经过Score_Pick.
group_softmax输出为[num_rois, c, h, w],其前传函数为Softmax(out, data),
score_pick 分为GetMaxIdx与GroupPickForward两部分,第一部分选取最可能的类别,
//////////////////////////
score_seg = mx.sym.Reshape(name='score_seg', data=cls_prob, shape=(-1, num_classes, 1, 1))//cls_prob是通过groupmax+avgpoolig+softmax的结果
seg_softmax = mx.contrib.sym.ChannelOperator(name='seg_softmax', data=psroipool_cls_seg, group=num_classes, op_type='Group_Softmax')
seg_pred = mx.contrib.sym.ChannelOperator(name='seg_pred', data=seg_softmax, pick_idx=score_seg, group=num_classes, op_type='Group_Pick', pick_type='Score_Pick')
////////////////////////////
template <typename DType>
__global__ void GetMaxIdxKernel(
const int count,
const DType* pick_score_data,
DType* argmax_data,
const int group) {
CUDA_KERNEL_LOOP(index, count) {
const DType* offset_pick_score_data = pick_score_data + index*group;
int max_idx = -1;
DType max_val = -FLT_MAX;
for (int i = 1; i < group; ++i) {
max_idx = offset_pick_score_data[i] > max_val ? i : max_idx;
max_val = offset_pick_score_data[i] > max_val ? offset_pick_score_data[i] : max_val;
}
argmax_data[index] = static_cast<DType>(max_idx);
}
}
template<typename DType>
inline void GetMaxIdx(const Tensor<gpu, 4, DType> &pick_score,
const Tensor<gpu, 4, DType> &argmax,
const int group) {
// LOG(INFO) << "GroupPickBackward";
const DType *pick_score_data = pick_score.dptr_;
DType *argmax_data = argmax.dptr_;
const int count = argmax.shape_.Size();
cudaStream_t stream = Stream<gpu>::GetStream(argmax.stream_);
GetMaxIdxKernel<DType> << <mxnet::op::mxnet_op::cuda_get_num_blocks(count),
kBaseThreadNum, 0, stream >> >(
count, pick_score_data, argmax_data, group);
ChannelOperator_CUDA_CHECK(cudaPeekAtLastError());
}
} // namespace cuda3 实验
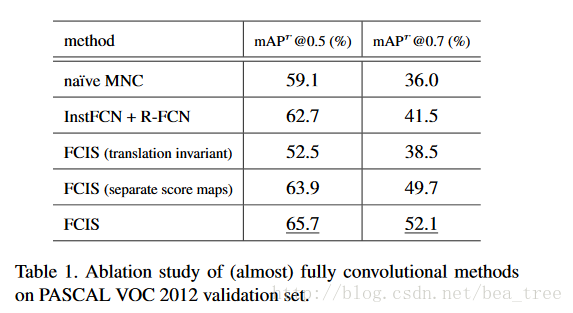
translation invariant是没有positive sensitive的情况,separate score maps是不共用一个score maps 的情况。