0.Abstract
We introduce DiscoBox, a novel framework that jointly learns instance segmentation and semantic correspondence using bounding box supervision. Specifically, we propose a self-ensembling framework where instance segmentation and semantic correspondence are jointly guided by a structured teacher in addition to the bounding box supervision.The teacher is a structured energy model incorporating a pairwise potential and a cross-image potential to model the pairwise pixel relationships both within and across the boxes.
我们介绍了 DiscoBox,这是一种新颖的框架,它使用边界框监督联合学习实例分割和语义对应。具体来说,我们提出了一个自集成框架,除了边界框监督之外,实例分割和语义对应由结构化教师共同指导。教师是一个结构化的能量模型,结合了成对势能和跨图像势能,对盒子内部和盒子之间的成对像素关系进行建模。
Minimizing the teacher energy simultaneously yields refined object masks and dense correspondences between intra-class objects, which are taken as pseudo-labels to supervise the task network and provide positive/negative correspondence pairs for dense constrastive learning.
最小化教师能量同时产生精细的对象掩码和类内对象之间的密集对应关系,它们被视为伪标签来监督任务网络并为密集对比学习提供正/负对应对。
We show a symbiotic relationship where the two tasks mutually benefit from each other. Our best model achieves 37.9% AP on COCO instance segmentation, surpassing prior weakly supervised methods and is competitive to supervised methods.We also obtain state of the art weakly supervised results on PASCAL VOC12 and PF-PASCAL with real-time inference.
我们展示了一种共生关系,其中两个任务相互受益。我们的最佳模型在 COCO 实例分割上实现了 37.9% 的 AP,超过了先前的弱监督方法,并且与监督方法具有竞争力。我们还在 PASCAL VOC12 和 PF-PASCAL 上通过实时推理获得了最先进的弱监督结果。
1. Introduction
The ability to localize and recognize objects is at the core of human vision. This has motivated the vision community to study object detection [1] as a fundamental visual recognition task. Instance segmentation [2] is further introduced on top of detection to predict the foreground object masks, thus enabling localization with pixel-level accuracy.
定位和识别物体的能力是人类视觉的核心。这促使视觉社区研究对象检测 [1] 作为一项基本的视觉识别任务。在检测之上进一步引入实例分割 [2] 以预测前景对象掩码,从而实现像素级精度的定位。
More recently, a growing number of works aim to lift the above tasks to the 3D space [3–7]. As a result, landmark [3,8] and (semantic) correspondence [9–30] have been widely studied to associate object parts across different views. These methods have become critical components in pose estimation [31–34] and reconstruction [35–38] because they help to reduce uncertainties through additional constraints, such as determining camera poses and viewpoints [31,36].
最近,越来越多的工作旨在将上述任务提升到 3D 空间 [3-7]。因此,地标 [3,8] 和(语义)对应 [9-30] 已被广泛研究以将对象部分关联到不同的视图。这些方法已成为姿态估计 [31-34] 和重建 [35-38] 的关键组成部分,因为它们有助于通过额外的约束来减少不确定性,例如确定相机姿态和视点 [31,36]。
Among various correspondence tasks, semantic correspondence aims to establish the associations across different scenes and object instances, and is arguably the most challenging one due to large variations in appearance and pose. The literature of semantic correspondence and instance segmentation have largely remained decoupled.
在各种对应任务中,语义对应旨在建立跨不同场景和对象实例的关联,并且由于外观和姿势的巨大变化,可以说是最具挑战性的任务。语义对应和实例分割的文献在很大程度上仍然是分离的。
For instance, the main semantic correspondence benchmarks [19,39–43] have been focusing on object-centric scenarios which deemphasizes the role of object localization, while the latest instance segmentation methods do not make use of intraclass correspondences. However, these seemingly separate problems can benefit from each other because associating object parts requires understanding the object of interest a priori. Similarly, knowing the semantic parts of an object requires understanding the geometry of functional parts and can improve object localization [44, 45].
例如,主要的语义对应基准 [19,39-43] 一直专注于以对象为中心的场景,这不再强调对象定位的作用,而最新的实例分割方法没有利用类内对应。然而,这些看似独立的问题可以相互受益,因为关联对象部分需要先验地理解感兴趣的对象。同样,了解对象的语义部分需要了解功能部分的几何形状,并且可以改进对象定位 [44, 45]。
Even though the advantage of learning correspondences and instance segmentation jointly is clear, many state of the art methods do not make use of this approach due to the lack of large scale datasets with both masks and correspondences. To overcome this challenge, weakly supervised methods have been recently introduced to relax the need for costly supervision in both tasks [25–30, 46–49].
尽管联合学习对应和实例分割的优势很明显,但由于缺乏具有掩码和对应的大规模数据集,许多最先进的方法并没有使用这种方法。为了克服这一挑战,最近引入了弱监督方法来放松这两项任务中对昂贵监督的需求[25-30, 46-49]。
Our work is aligned with these efforts as we aim to address instance segmentation and semantic correspondence jointly with inexpensive bounding box supervision. This allows us to effectively push the boundaries with more data.
我们的工作与这些努力保持一致,因为我们的目标是通过廉价的边界框监督来解决实例分割和语义对应。这使我们能够有效地利用更多数据突破界限。
More importantly, box supervision presents a principled way to couple the above two tasks: First, instance segmentation greatly extends the capability of semantic correspondence to handle multi-object scenarios. This allows one to define a more generalized and challenging semantic correspondence task where the performance emphasizes both the quality of object-level correspondence and the accuracy of object localization. Second, multi-tasking provides the mutual constraints to overcome trivial solutions in box supervision. Indeed, our study shows a symbiotic relation where localization benefits correspondence via improved locality and representation, whereas correspondence in turn helps localization with additional cross-image information.
更重要的是,box supervision提供了一种耦合上述两个任务的原则方法:首先,实例分割极大地扩展了语义对应的能力以处理多对象场景。这允许人们定义更通用和更具挑战性的语义对应任务,其中性能强调对象级对应的质量和对象定位的准确性。其次,多任务提供了相互约束来克服盒子监督中的琐碎解决方案。事实上,我们的研究显示了一种共生关系,其中本地化通过改善局部性和表示来有益于对应,而对应反过来又有助于通过额外的跨图像信息进行定位。
We propose DISCOBOX, a framework which instantiates the above targets as shown in Fig. 1. DISCOBOX leverages various levels of structured knowledge and self-supervision both within and across images to reduce the uncertainties.
我们提出了 DISCOBOX,这是一个实例化上述目标的框架,如图 1 所示。DISCOBOX 利用图像内部和跨图像的各种层次的结构化知识和自我监督来减少不确定性。

Figure 1. Task overview. Given a pair of images, DISCOBOX simultaneously outputs detection, instance segmentation and semantic correspondence predictions. Best viewed in color.
图 1. 任务概览。给定一对图像,DISCOBOX同时输出检测、实例分割和语义对应预测,最好以彩色观看。
Summary of contributions:
Our work is the first to propose a unified framework for joint weakly supervised instance segmentation and semantic correspondence using bounding box supervision.
我们的工作是第一个提出使用边界框监督的联合弱监督实例分割和语义对应的统一框架。
We propose a novel self-ensembling framework where a teacher is designed to promote structured inductive bias and establish correspondences across objects. We show that the proposed framework allows us to jointly exploit both intraand cross-image self-supervisions and leads to significantly improved task performance.
我们提出了一种新颖的自组装框架,其中教师旨在促进结构化归纳偏差并建立跨对象的对应关系。我们提出的框架允许我们共同利用图像内和跨图像自我监督,并显着提高任务性能。
We achieve state-of-the-art performance on weakly supervised instance segmentation. Our best model achieves 37.9% AP on COCO test-dev, surpassing competitive supervised methods such as YOLACT++ [50] (34.6% AP) and Mask R-CNN [51] (37.1% AP).
我们在弱监督实例分割上实现了最先进的性能。我们最好的模型在 COCO test-dev 上实现了 37.9% 的 AP,超过了 YOLACT++ [50] (34.6% AP) 和 Mask R-CNN [51] (37.1% AP) 等竞争监督方法。
We also achieve state-of-the-art performance on weakly supervised semantic correspondence, and are the first to propose a multi-object benchmark for this task.
我们还在弱监督语义对应上实现了最先进的性能,并且是第一个为此任务提出多对象基准的人。
Task network. Our task network contains an instance segmentation backbone with a multiple instance learning head. The module is supervised by bounding boxes which contain rich object information. Through multiple instance learning, coarse object masks naturally emerge as network attention, and is taken by the teacher as initial predictions.
我们的任务网络包含一个带有多实例学习头的实例分割主干。该模块由包含丰富对象信息的边界框监督。通过多实例学习,粗略的对象掩码自然而然地作为网络注意力出现,并被教师作为初始预测。
Teacher model. The teacher is defined by a Gibbs energy which comprises a unary potential, a pairwise potential and a cross-image potential. The unary potential takes the initial output from the student whereas the pairwise and cross-image potentials model the pairwise pixel relationships both within and across bounding boxes. Minimizing the teacher energy promotes contrast-sensitive smoothness while establishing dense correspondence across the objects.This allows one to consider cross-image self-supervision where correspondence provides positive and negative pairs for dense contrastive learning. We show that this in turn can improve the quality of instance segmentation.
教师由吉布斯能量定义,包括a unary potential, a pairwise potential and a cross-image potential。The unary potential 从学生那里获取初始输出,而the pairwise and cross-image potentials对边界框内和边界框之间的成对像素关系进行建模。最小化the teacher energy可促进对比度敏感的平滑度,同时在对象之间建立密集对应关系。这允许人们考虑跨图像自我监督,其中对应关系为密集对比学习提供正负对。我们表明,这反过来可以提高实例分割的质量。
Our promising results indicate the possibility to completely remove mask labels in future instance segmentation problems. We also envisage the wide benefit of DISCOBOX to many downstream applications, particularly 3D tasks.
我们有希望的结果表明在未来的实例分割问题中完全删除掩码标签的可能性。我们还设想 DISCOBOX 对许多下游应用程序的广泛好处,特别是 3D 任务。
2. Related Work
2.1. Object recognition and localization
Object detection:
Object detection has been an active research area with rich literature. Training on large amounts of bounding box annotations with convolutional neural networks (CNNs) has become a standard paradigm [52]. Initial CNN based detectors tend to share a multi-stage design [52, 53] where the first stage gives redundant object proposals, followed by refinement by CNNs in the second stage. A recent trend of design aims to reduce the complexity by having one-stage architectures [54–57], and therefore achieves good trade-off between efficiency and performance. Our weakly supervised design allows DISCOBOX to be conveniently trained like any object detection algorithm on the increasingly large datasets [58–60], but output additional predictions beyond just bounding boxes.
目标检测一直是一个活跃的研究领域,拥有丰富的文献。使用卷积神经网络 (CNN) 对大量边界框注释进行训练已成为标准范式 [52]。最初的基于 CNN 的检测器倾向于共享多阶段设计 [52, 53],其中第一阶段给出冗余对象建议,然后在第二阶段由 CNN 进行细化。最近的设计趋势旨在通过具有单阶段架构来降低复杂性[54-57],因此在效率和性能之间实现了良好的权衡。我们的弱监督设计允许 DISCOBOX 像任何对象检测算法一样在越来越大的数据集 [58-60] 上方便地进行训练,但输出超出边界框的额外预测。
Instance segmentation:
Instance segmentation aims to produce more precise localization over detection by predicting the object segmentation masks. Bharath et al. [2] are the first to introduce an R-CNN-based framework with a precision-recall benchmark. Similar to R-CNN [52], their object proposal and mask generation [61] is not end-to-end learnable. Recent methods including Mask R-CNN [62–64] have largely followed this “detection-flavored” design and benchmarking, but introduce end-to-end learnable object proposal and mask prediction. Inspired by the one-stage detection, a number of one-stage instance segmentation methods have also been proposed [50,51,65–68]. These methods all require mask annotations during training, whereas DISCOBOX only needs box labels. DISCOBOX is also agnostic to the choice of frameworks. In this work, we showcase DISCOBOX on both YOLACT++ [50] and SOLOv2 [68] by taking them as the base architectures for our method.
实例分割旨在通过预测对象分割掩码来产生更精确的检测定位。巴拉特等人。 [2] 是第一个引入具有精确召回基准的基于 R-CNN 的框架。与 R-CNN [52] 类似,它们的对象提议和掩码生成 [61] 不是端到端可学习的。包括 Mask R-CNN [62-64] 在内的最新方法在很大程度上遵循了这种“检测风格”的设计和基准测试,但引入了端到端的可学习对象提议和掩模预测。受单阶段检测的启发,还提出了许多单阶段实例分割方法[50,51,65-68]。这些方法都需要在训练过程中进行掩码标注,而 DISCOBOX 只需要框标签。 DISCOBOX 也与框架的选择无关。在这项工作中,我们在 YOLACT++ [50] 和 SOLOv2 [68] 上展示了 DISCOBOX,将它们作为我们方法的基础架构。
2.2. Weakly supervised segmentation
Weakly supervised semantic segmentation:
A number of methods have been proposed to learn semantic segmentation with image-level class labels [69–73], points [74,75], scribbles [76–79] and bounding boxes [46,80–83]. Among them, box-supervised semantic segmentation is probably most related, and recent methods such as Box2Seg [83] have achieved impressive performance on Pascal VOC [58].These methods often use MCG [61] and GrabCut [84] to obtain segmentation pseudo-labels for supervising subsequent tasks. However, they focus on semantic segmentation which does not distinguish different object instances.
已经提出了许多方法来学习使用图像级类标签 [69-73]、点 [74,75]、涂鸦 [76-79] 和边界框 [46,80-83] 的语义分割。其中,框监督语义分割可能是最相关的,最近的方法如 Box2Seg [83] 在 Pascal VOC [58] 上取得了令人印象深刻的性能。这些方法通常使用 MCG [61] 和 GrabCut [84] 来获得分割伪用于监督后续任务的标签。然而,他们专注于不区分不同对象实例的语义分割。
Weakly supervised instance segmentation:
Here, the term “weakly supervised” can either refer to the relaxed supervision on bounding box location [85,86], or the absence of mask annotations [46–49]. The former can be viewed as an extension of weakly supervised object detection [87], whereas our work falls into the second category. Among the latter methods, Hsu et al. [47] leverages the fact that bounding boxes tightly enclose the objects, and proposes multiple instance learning framework based on this tightness prior.
在这里,“弱监督”一词既可以指对边界框位置的宽松监督[85,86],也可以指没有掩码注释[46-49]。前者可以看作是弱监督目标检测的扩展[87],而我们的工作属于第二类。在后一种方法中,Hsu 等人。 [47]利用边界框紧密包围对象的事实,并基于这种紧密性先验提出了多实例学习框架。
A pairwise loss is also imposed to maintain object integrity.However, their pairwise consistency is defined on all neighboring pixel pairs without distinguishing the pairwise pixel contrast. Arun et al. [48] proposes an annotation consistency framework which can handle weakly supervised instance segmentation with both image-level and bounding box labels. On COCO, the gap to supervised methods has remained large until recently BoxInst [49] reduced this gap significantly. DISCOBOX outperforms these methods while additionally targeting semantic correspondence.
还施加了成对损失以保持对象完整性。但是,它们的成对一致性是在所有相邻像素对上定义的,而不区分成对像素对比度。阿伦等人[48] 提出了一个注释一致性框架,可以处理具有图像级和边界框标签的弱监督实例分割。在 COCO 上,与监督方法的差距一直很大,直到最近 BoxInst [49] 显着缩小了这一差距。 DISCOBOX 优于这些方法,同时还针对语义对应。
2.3. Finding correspondence
Local features:
Using local features to match the keypoints across different views has been widely used in 3D vision problems such as structure from motion. Over the past decade, the methods have evolved from hand-crafted ones [9–11] to learning-based ones using decision tree and deep neural networks [12–17] with extremely abundant literature. These methods primarily focus on multi-view association for the same object instance or scene, which differs from our task despite the underlying strong connection.
使用局部特征来匹配不同视图的关键点已广泛用于 3D 视觉问题,例如运动结构。在过去的十年中,这些方法已经从手工制作的 [9-11] 发展到使用决策树和深度神经网络 [12-17] 的基于学习的方法,文献非常丰富。这些方法主要关注同一对象实例或场景的多视图关联,尽管存在潜在的强连接,但这与我们的任务不同。
Semantic correspondence:
Semantic correspondences has been a challenging problem. The problem probably dates back to SIFTFlow [18] which uses hand-crafted features to establish the correspondence. More recent methods have universally resorted to deep networks as powerful feature extractors [21–23]. The challenge of this task is further aggravated by the costly nature of correspondence annotation. Existing datasets [43, 88] are relatively small in size, and only provide sparse correspondence ground truths since manually annotating dense ones is prohibitive. In light of this challenge, weakly supervised semantic correspondence are proposed to learn correspondence without correspondence ground truths [25–30]. In addition, existing benchmarks and methods have predominantly focused on “objectcentric” scenarios where each image is occupied by a major object. In this work, we further add challenge to the task by considering a more generalized multi-object scenario with object localization in the loop.
语义对应一直是一个具有挑战性的问题。这个问题可能可以追溯到 SIFTFlow [18],它使用手工制作的特征来建立对应关系。最近的方法普遍采用深度网络作为强大的特征提取器[21-23]。对应注释的昂贵性质进一步加剧了这项任务的挑战。现有数据集 [43, 88] 的大小相对较小,并且仅提供稀疏的对应基本事实,因为手动注释密集数据集是禁止的。鉴于这一挑战,提出了弱监督语义对应来学习没有对应基础事实的对应[25-30]。此外,现有的基准和方法主要关注“以对象为中心”的场景,其中每个图像都被一个主要对象占据。在这项工作中,我们通过考虑在循环中进行对象定位的更通用的多对象场景,进一步增加了任务的挑战。
3. Method
We define the following notations for the variables in our problem, and use them throughout the rest of the paper. We denote the input image as I. Given any instance segmentation backbone, we assume that a set of box region proposals R = {rn|n=1,...,N} are generated. Each box proposal corresponds to an RoI feature map fn of size C×H×W.Additionally, instance segmentation produces a set of object masks M = {mn|n=1,...,N}, where each mn is an H×W probability map associated with rn. Fig. 2 illustrates an overview of the proposed framework.
我们为问题中的变量定义以下符号,并在本文的其余部分使用它们。我们将输入图像表示为 I。给定任何实例分割主干,我们假设生成一组框区域建议 R = {rn|n=1,...,N} 。每个 box proposal 对应一个大小为 C×H×W 的 RoI 特征图 fn。此外,实例分割产生一组对象掩码 M = {mn|n=1,...,N},其中每个 mn 是与 rn 关联的 H×W 概率图。图 2 说明了所提出框架的概述。

Figure 2. Overview of DISCOBOX. We design a self-ensembling framework where a structured teacher generates refined instance segmentation mask and establishes dense correspondence between intra-class box proposals to guide the task network. Best viewd in color.
图 2. DISCOBOX 概览。我们设计了一个自集成框架,其中结构化教师生成精细的实例分割掩码,并在类内框建议之间建立密集对应以指导任务网络。最好以彩色观看。
4. Experiments
We conduct experiments on 4 datasets: PASCAL VOC 2012 (VOC12) [58], COCO [59], PF-PASCAL [88], PAS-CAL 3D+ [4]. We test instance segmentation on VOC12 and COCO, and semantic correspondence on the other two.
我们对 4 个数据集进行了实验:PASCAL VOC 2012 (VOC12) [58]、COCO [59]、PF-PASCAL [88]、PAS-CAL 3D+ [4]。我们在 VOC12 和 COCO 上测试实例分割,并在另外两个上测试语义对应。
4.1. Datasets and metrics
COCO.
COCO contains 80 semantic categories. We follow the standard partition which includes train2017 (115K images) and val2017 (5K images) for training and validation. We also report our results on the test-dev split. During training, we only use the box annotations.
COCO包含80个语义类别。我们遵循标准分区,其中包括用于培训和验证的Train 2017(11.5万张图像)和val2017(5K张图像)。我们还报告了测试-开发拆分的结果。在培训期间,我们只使用方框注释
VOC12.
VOC12 consists of 20 categories with a training set of around 10,500 images and a validation set of around 5,000 images. Around 1,500 images of the validation set contain the instance segmentation annotations.
VOC12 由 20 个类别组成,其中包含约 10,500 张图像的训练集和约 5,000 张图像的验证集。验证集的大约 1,500 张图像包含实例分割注释。
PF-PASCAL.
The PF-PASCAL dataset contains a selected subset of object-centric images from PASCAL VOC.It contains around 1,300 image pairs with 700 pairs for the training set and 300 pairs for the validation set, and 300 image pairs for the test sets respectively. There is only one conspicuous object in the middle of the image. Each image pair contain two intra-class objects.
PF-PASCAL 数据集包含来自 PASCAL VOC 的以对象为中心的图像的选定子集。它包含大约 1,300 个图像对,其中 700 对用于训练集,300 对用于验证集,300 对用于测试集。图像中间只有一个显眼的物体。每个图像对包含两个类内对象。
PASCAL 3D+.
PASCAL 3D+ contains the annotations of object poses, landmarks and 3D CAD models in addition to bounding boxes, and consists of 12 rigid categories where each has 3,000 object instances on average. We evaluate multi-object correspondence on PASCAL 3D+ dataset. The availability of both bounding boxes and landmarks, as well as other 3D information makes it an ideal dataset to evaluate multi-object semantic correspondence. We construct the benchmark on the 12 rigid categories of PASCAL 3D+ and follow the official VOC12 partitioning of the validation set, where images only containing the 8 non-rigid classes are removed. For training, we still preserve the full VOC12 training set and annotations (20 classes).
除了边界框外,PASCAL 3D+ 还包含对象姿势、地标和 3D CAD 模型的注释,由 12 个刚性类别组成,每个类别平均有 3,000 个对象实例。我们在 PASCAL 3D+ 数据集上评估多对象对应关系。边界框和地标以及其他 3D 信息的可用性使其成为评估多对象语义对应的理想数据集。我们在 PASCAL 3D+ 的 12 个刚性类别上构建基准,并遵循验证集的官方 VOC12 划分,其中仅包含 8 个非刚性类别的图像被删除。对于训练,我们仍然保留完整的 VOC12 训练集和注释(20 类)。
As PASCAL 3D+ does not provide image pairs, we need to generate image pairs and keypoint pairs on PASCAL for the correspondence evaluation. We enumerate all pairwise combinations of two images on the PASCAL 3D+ validation set. For any pairwise images, if both contain at least one intra-class object in common, we mark them as matched and keep this pair for evaluation. The second step is to generate the sparse correspondence ground truths on top of the matched image pairs using the provided keypoints. For any pairwise images, we find all combinations of intra-class object pairs and use the keypoint pairs between these object pairs as the correspondence ground-truth. Due to occlusion, some keypoints may be missing and are ignored during the evaluation. Note that we also ignore any pairwise objects where the difference between their 3D orientations is greater than 60 degrees, since a large orientation gap often results in very few valid keypoint pairs.
由于 PASCAL 3D+ 不提供图像对,我们需要在 PASCAL 上生成图像对和关键点对以进行对应评估。我们列举了 PASCAL 3D+ 验证集上两个图像的所有成对组合。对于任何成对的图像,如果两者都包含至少一个共同的类内对象,我们将它们标记为匹配并保留这一对以进行评估。第二步是使用提供的关键点在匹配的图像对之上生成稀疏对应的基本事实。对于任何成对的图像,我们找到类内对象对的所有组合,并使用这些对象对之间的关键点对作为对应的 ground-truth。由于遮挡,一些关键点可能会丢失并在评估过程中被忽略。请注意,我们还忽略了 3D 方向之间的差异大于 60 度的任何成对对象,因为较大的方向间隙通常会导致非常少的有效关键点对。
Multi-object correspondence metric.
Similar to object detection, we introduce a precision-recall based metric with average precision (AP). We assume that there is a confidence associated with each predicted correspondence, and we define it as the multiplication of the pairwise box confidence in this work. This allows us to compute precision and recall by defining true positive (TP), false positive (FP) and false negative (FN). Since PASCAL 3D+ only provides sparse correspondence ground truths, the challenge here is to correctly ignore some of the correspondence predictions that are far away from any ground truth but are correct. To this end, we follow a keypoint transfer setting where we always define a source side s and a target side t for any pairwise objects. Given a ground truth (gjs; gjt), a predicted correspondence (psi ; pti) and a distance threshold :
与目标检测类似,我们引入了一种基于精度召回的具有平均精度 (AP) 的度量。我们假设每个预测的对应关系都有一个置信度,我们将其定义为这项工作中成对框置信度的乘积。这允许我们通过定义真阳性 (TP)、假阳性 (FP) 和假阴性 (FN) 来计算精度和召回率。由于PASCAL 3D+ 只提供稀疏的对应基本事实,这里的挑战是正确地忽略一些远离任何基本事实但正确的对应预测。为此,我们遵循关键点传输设置,我们始终为任何成对对象定义源端 s 和目标端 t。给定一个基本事实(gjs;gjt),一个预测对应(pis;pit)和一个距离阈值α:

We term the average precision as AP@ where is a threshold relative to the box diagonal. We then define the final APas: mean(AP@f0:75%; 1%; 1:5%; 2%; 3%g).
我们将平均精度称为 AP@,其中是相对于框对角线的阈值。然后我们将最终的 AP 定义为:mean(AP@f0:75%; 1%; 1:5%; 2%; 3%g)。
4.2. Implementation details
Training. We use stochastic gradient descent (SGD) for network optimization. For loss weights, we set αmil, αcon, αnce as 10; 2; 0:1 on YOLACT++ and set αmil, αcon, αnce as 1; 1; 0:1 on SOLOv2. Kindly refer to Appendix C for additional implementation details.
我们使用随机梯度下降 (SGD) 进行网络优化。对于损失权重,我们将 αmil, αcon, αnce 设置为 10; 2;在 YOLACT++ 上为 0:1,并将 αmil, αcon, αnce 设置为 1; 1个; SOLOv2 上 0:1。请参阅附录 C 了解更多实施细节。
4.3. Weakly supervised instance segmentation

Main results. We evaluate instance segmentation on COCO and VOC12, with the main results reported in Tab. 1 and 2, respectively. DISCOBOX outperforms BBTP [47] by 10:3% mAP on the COCO validation 2017 split with a smaller backbone (ResNet-50). DISCOBOX also outperforms BoxInst [49] which is the current state-of-the-art boxsupervised method on both COCO and VOC12. Notably, BoxInst/ResNet-101-DCN also adopts BiFPN [95], an im-proved variant of FPN [89]. Fig. 4 and Appendix D additionally visualize the instance segmentation results.
主要结果。我们评估了 COCO 和 VOC12 上的实例分割,主要结果在表中报告。分别为表1和表2。在 2017 年 COCO 验证拆分中,DISCOBOX 的性能优于 BBTP [47] 10:3% mAP,主干更小(ResNet-50)。 DISCOBOX 的性能也优于 BoxInst [49],后者是目前在 COCO 和 VOC12 上最先进的盒监督方法。值得注意的是,BoxInst/ResNet-101-DCN 还采用了 BiFPN [95],这是 FPN [89] 的改进变体。图 4 和附录 D 还可视化了实例分割结果。
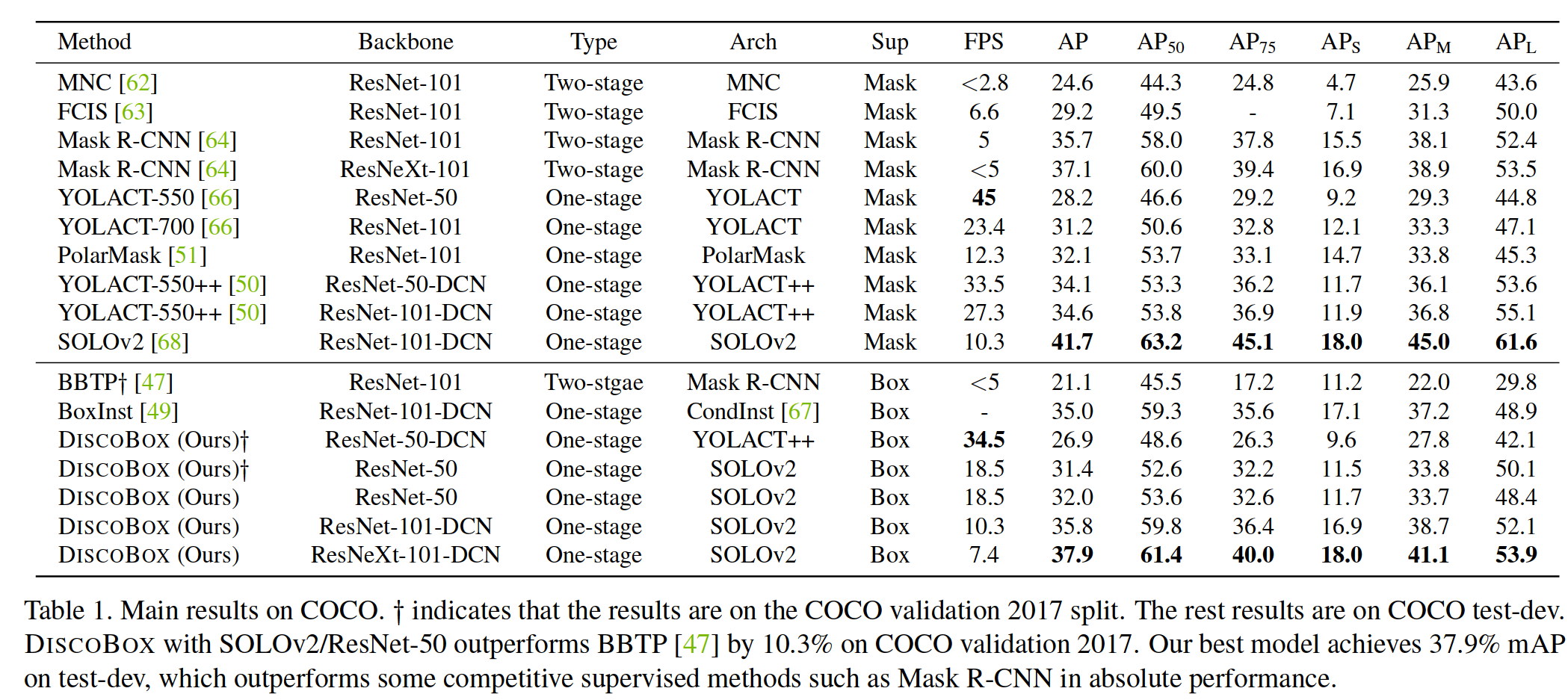
Table 1. Main results on COCO. y indicates that the results are on the COCO validation 2017 split. The rest results are on COCO test-dev.DISCOBOX with SOLOv2/ResNet-50 outperforms BBTP [47] by 10.3% on COCO validation 2017. Our best model achieves 37.9% mAP on test-dev, which outperforms some competitive supervised methods such as Mask R-CNN in absolute performance.
表 1. COCO 的主要结果。 y 表示结果基于 COCO 验证 2017 拆分。其余结果在 COCO test-dev。DISCOBOX 上,SOLOv2/ResNet-50 在 2017 年 COCO 验证中优于 BBTP [47] 10.3%。我们最好的模型在 test-dev 上实现了 37.9% 的 mAP,优于一些竞争性监督方法,例如Mask R-CNN 的绝对性能。
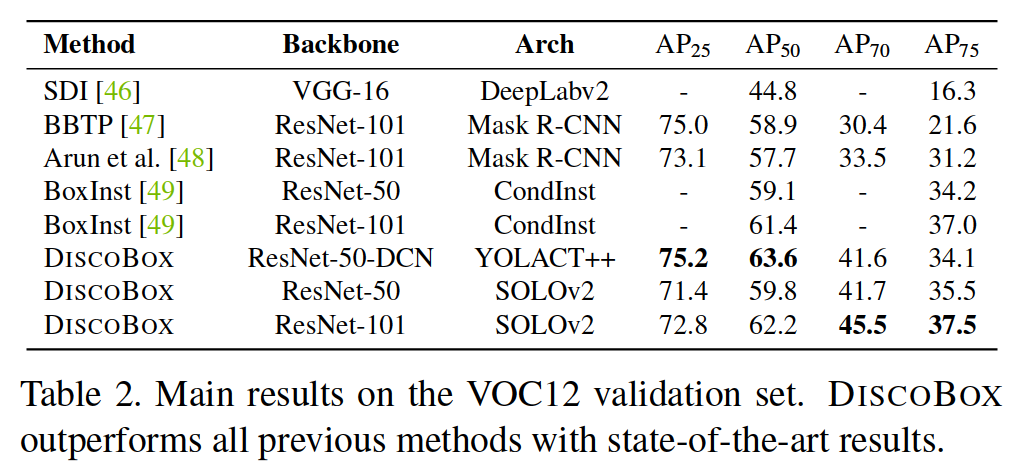
Table 2. Main results on the VOC12 validation set. DISCOBOX outperforms all previous methods with state-of-the-art results.
表2.VOC12验证集的主要结果。Discobox以最先进的结果超越了所有以前的方法。
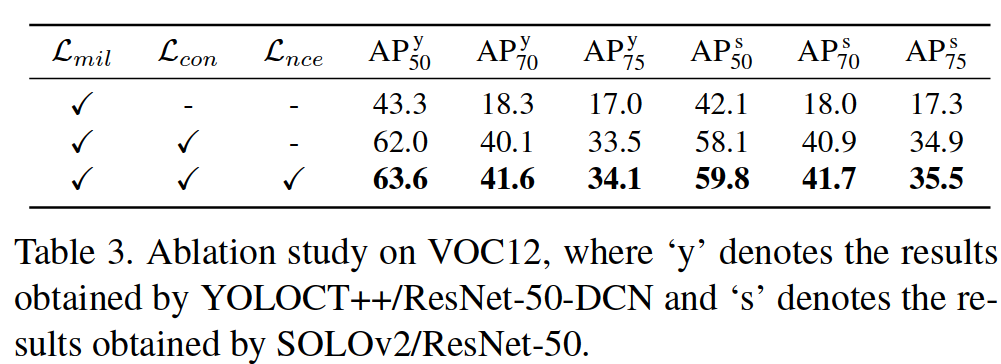
Analysis. We perform ablation study on VOC12 with Lmil, Lcon and Lnce. The results in Tab. 3 show consistent improvements from Lcon and Lnce, demonstrating the benefit of the structured teacher. We also conduct sensitivity analysis with the loss weights on both instance segmentation (VOC12)1 and semantic correspondence (PASCAL 3D+, see Sec. 4.4). The results in Fig. 6 show that DISCOBOX is not sensitive to weight changes.
我们使用 Lmil, Lcon and Lnce 对 VOC12 进行消融研究。选项卡中的结果。表3 显示了 Lcon and Lnce的持续改进,展示了结构化教师的好处。我们还对实例分割(VOC12)1 和语义对应(PASCAL 3D+,参见第 4.4 节)的损失权重进行敏感性分析。图 6 中的结果表明 DISCOBOX 对重量变化不敏感。

4.4. Weakly supervised semantic correspondence
PF-PASCAL (Object-Centric).
We first evaluate DIS-COBOX on PF-PASCAL [88] using YOLACT++/ResNet-50-DCN, with the main results presented in Tab. 4. We do not directly train the DISCOBOX model on PF-PASCAL.Instead, we train it on the VOC12 training set, excluding those images that are present in the PF-PASCAL validation set. It is worth noting that many existing semantic correspondence methods can not be similarly trained on VOC12 without major changes, even though some of them do consider certain level of localization information such as attention.
我们首先使用 YOLACT++/ResNet-50-DCN 在 PF-PASCAL [88] 上评估 DIS-COBOX,主要结果见表。 表4. 我们不直接在 PF-PASCAL 上训练 DISCOBOX 模型。相反,我们在 VOC12 训练集上训练它,不包括那些存在于 PF-PASCAL 验证集中的图像。值得注意的是,许多现有的语义对应方法不能在没有重大变化的情况下在 VOC12 上进行类似的训练,尽管其中一些确实考虑了一定程度的定位信息,例如注意力。

During inference, we use instance segmentation to obtain object masks, and use the structured teacher to produce dense pixel-wise correspondence by taking the masks as input. Our approach outperforms the previous weakly supervised semantic correspondence approaches with considerable margins. Such improvement can be attributed to three main factors: 1) The improved design of structured teacher which renders good correspondence quality at object-level. 2) The box-supervised learning framework which makes it possible to scale up the training using more data and obtain improved correspondence representation. 3) The high quality object localization as a result of the coupled learning framework that help to guide the correspondence.
在推理过程中,我们使用实例分割来获得对象掩码,并使用结构化教师通过将掩码作为输入来产生密集的像素级对应关系。我们的方法以相当大的优势优于以前的弱监督语义对应方法。这种改进可归因于三个主要因素: 1)改进的结构化教师设计,在对象级别呈现良好的通信质量。 2)盒子监督学习框架,可以使用更多数据扩大训练规模并获得改进的对应表示。 3)由于耦合学习框架有助于指导通信,高质量的对象定位。
PASCAL 3D+ (Multi-Object).
Finally, we benchmark DISCOBOX and several baselines on PASCAL 3D+. Tab. 5 lists the main results and Fig. 5 visualizes some predicted correspondence. The comparing methods in Tab. 5 are defined as follows: Identity: We align each pair of images only considering the positions of pixels. SCOT: A modified version of [23] by removing beam search and keeping their matching module on our RoI features. DISCOBOX-: Our model trained on VOC12 without dense NCE loss, but using teacher during inference for correspondence. DISCOBOX: Our full approach. We use YOLACT++/ResNet-50-DCN for all methods. Our method does not include beam search with the validation data and label [23], and is therefore purely box-supervised. The results show the effectiveness of our proposed teacher and dense contrastive learning.
最后,我们在 PASCAL 3D+ 上对 DISCOBOX 和几个基线进行了基准测试。标签。表5 列出了主要结果,图 5 可视化了一些预测的对应关系。表中的比较方法。 5 定义如下: 身份:我们只考虑像素的位置对齐每对图像。 SCOT:[23] 的修改版本,删除了波束搜索并将其匹配模块保留在我们的 RoI 特征上。 DISCOBOX-:我们的模型在 VOC12 上训练,没有密集的 NCE 损失,但在推理过程中使用教师进行通信。 DISCOBOX:我们的完整方法。我们对所有方法都使用 YOLACT++/ResNet-50-DCN。我们的方法不包括带有验证数据和标签 [23] 的光束搜索,因此是纯粹的框监督。结果显示了我们提出的教师和密集对比学习的有效性。

5. Conclusions
We presented DISCOBOX, a novel framework able to jointly learn instance segmentation and semantic correspondence from box supervision.
我们提出了 DISCOBOX,一个能够从盒子监督中联合学习实例分割和语义对应的新框架。
Our proposed self-ensembling framework with a structured teacher has led to significant improvement with state of the art performance in both tasks.We also proposed a novel benchmark for multi-object semantic correspondence together with a principled evaluation metric.
我们提出的带有结构化教师的自集成框架在这两个任务中都显着提高了最先进的性能。我们还提出了一个用于多对象语义对应的新基准以及有原则的评估指标。
With the ability to jointly produce high quality instance segmentation and semantic correspondence from box supervision, we envision that DISCOBOX can scale up and benefit many downstream 2D and 3D vision tasks.
凭借从盒子监督中共同产生高质量实例分割和语义对应的能力,我们设想 DISCOBOX 可以扩大规模并受益于许多下游 2D 和 3D 视觉任务。
Acknowledgement: We would like to sincerely thank Xinlong Wang, Zhi Tian, Shuaiyi Huang, Yashar Asgarieh, Jose M. Alvarez, De-An Huang, and other NVIDIA colleagues for the discussion and constructive suggestions.
致谢:我们衷心感谢Xinlong Wang、Zhi Tian、Shuayi Huang、Yashar Asgarieh、Jose M. Alvarez、De-An Huang 和其他NVIDIA 同事的讨论和建设性建议。