Understanding Convolution for Semantic Segmentation
Abstract
首先,我们设计了密集卷积上采样(dense upssampling convolution DUC)可以获得像素级别的上采样,DUC可以获取并解码一些细节信息,这些细节信息是双线性插值上采样不能获取的。第二,在编码部分我们提出了混合空洞卷积(Hybrid dilated convolution HDC)框架,这个框架由两个优点1)、有效的增加了感受野(receptive fields RF),可以综合全局的信息,2)、解决了网格问题(“gridding issue”),这是由于标准的空洞卷积造成的。我们在城市数据集上进行了测试,并且取得了soa的效果mIOU=80.1%,并且也在KITTI以及PASCAL VOC2012上进行了测试。
1. Introduction
语义分割的目的是解决图像中像素的分类问题,这在图像理解和无人驾驶中具有非常重要的意义。现在大多数解决语义分割的框架有三个关键的思路:1)、全卷积(FCN)把分类网络的全连接层换成卷积层,这样可以获得一个end-to-end的模型并且支持任意大小的输入。2)、条件随机场(CRF),为了获得局部以及长程信息来优化分割结果,3)、空洞卷积,在同样的计算量的情况下,增大卷积核的感受野,生成更加准确的预测结果。
自从FCN问世以来,全监督语义分割模型主要在两个点上进行改进,1)、加深模型,从VGG-16到Resnet-101到ResNet-152模型逐渐加深,mIOU也逐渐提高。2)、CRF的应用,把CRF集成至神经网络中,以及配合其它信息,比如边缘或者目标检测。
我们从另外一个角度出发来提高语义分割的性能-Convolution,分别从编码(输入到中间feature map)和解码(中间feature map到最终的label map)。在解码部分,大部分语义分割模型主要采用双线性插值上采样来获得输出label map。但是双线性插值不是可学习的而且会丢失信息。受超分辨率的启发,我们采用密集上采样卷积(DUC),来一次性恢复label map的全部分辨率,我们学习了一系列上采样滤波器来对下采样的feature map进行恢复到要求的分辨率。DUC通过实现端到端的训练自然而然地适合FCN框架,并且它显着增加了城市景观数据集[5]上的像素级语义分割的mIOU,特别是对于相对较小的对象。
对于编码部分,空洞卷积由于其可以增大感受野、控制分辨率从而消除了下采样的需要。然后空洞卷积固有的问题就是gridding现象,因为卷积核中间加入了0(空洞),感受野只获取了非0区域的信息,丢失了一些邻居(局部)信息。当rate逐渐增大,这个问题越来越严重,通常是在深层网络中,感受野特别大,造成卷积核中两个非0权重的距离太远,卷积核太稀疏以至于不能覆盖任何局部信息。某个固定位置像素的信息总是来自与具有空格的模式下。因此,作者提出混合空洞卷积,使用一系列空洞卷积然后把feature map级联在一起。这个方法有效的减轻了gridding问题。而且选择合适的rate可以提高感受野和精确度。
3. Our Approach
3.1. Dense Upsampling Convolution(DUC)
假设输入的图像大小是HxWxC,分割目的是获得HxW大小的label map。把图像送入FCN之后,在分类之前获得h*w*c的feature map,h=H/d,w=W/d,d代表下采样的倍数。之前的很多模型都会采用双线性插值或者反卷积来进行上采样。而作者是直接在feature map上DUC操作来获得逐像素的预测类别。图1中有DUC层。
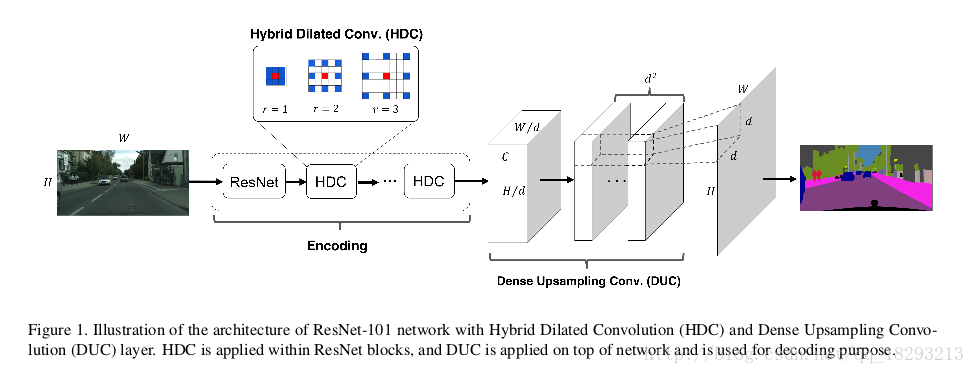
DUC操作全是基于卷积的。ResNet输入为H*W的图像,输出的feature map为h*w*c,经过DUC之后变为h*w*d^{2}*L,L代表分割的类别个数。然后将输出reshape为H*W*L,就可以获得分割结果,然后再对上述分割结果进行argmax即可得到最终的label map。DUC的主要思想就是将整个label map划分成与输入的feature map等尺寸的子部分。所有的子部分被叠加d^2次就可以产生整个label map了。这种变化允许我们直接作用在输出的feature map上而不用像deconvolution和unpooling那样还需要一些额外的信息。
因为DUC是科学习的,它能够捕获和恢复双线性插值操作中通常缺少的细节信息。例如,如果一个模型的下采样倍数为16,但是一个物体的长或者宽小于16个像素,下采样之后双线性插值就很难恢复这个物体了。这样最终的label map就会丢失细节信息了。DUC的输出和输入分辨率是一致的,而且可以集成至FCN中,完美的实现了端到端的分割。
3.2 Hybrid Dilated Convolution(HDC)
HDC就是带孔卷积的集合,带孔卷积在DeepLab系列中已经介绍过了。带孔卷积可以增大模型的感受野,假设标准的(r=1)卷积核感受野为k*k,带孔卷积的感受野为k_{d}*k_{d},k_{d}=k+(k-1)(r-1)。带孔卷积集替代了传统模型中的maxpooling和卷积中的stride来控制feature map的分辨率。
然而带孔卷积存在一个问题,就是gridding现象。当dilated convolution在高层使用的rate变大时,对输入的采样将变得很稀疏,将不利于学习。因为一些局部信息完全丢失了,而长距离上的一些信息可能并不相关;并且gridding效应可能会打断局部信息之间的连续性。如图5所示。
所以作者对带孔卷积提出了改进,不采用完全一致的rate。
图a. 所有带孔卷积层的rate=2
图b. rate分别为1,2,3
从图中也可以看出,HDC不仅可以增大感受野,而且覆盖面也密集,其实可以简单的理解为rate=2的卷积核在计算时可能会漏过一些点,但是rate=3的卷积核在计算时可能就会把这写漏过的点覆盖上,这也是削弱gridding现象的一个原因。而且作者指出,rate之间的因子不能相同,即rate=2, 4, 8这种就不能去除gridding现象。这就是HDC和ASPP最大的不同。

4. Experimrnts and Results
4.1.1 Baseline Model
作者采用DeepLab-V2 ResNet101作为对比实验。因为Cityscapes的数据集size为1024*2048,这非常占用GPU的内存,我们把这个图像分成12个800*800的图像块,图像块之间有部分重合,因此训练集增加到了35700。这种数据增强方式是保证图像中的每一个区域都能被访问到,这比随机裁剪要好,因为随机裁剪相邻的区域会被重复的访问。
训练采用随机梯度下降,输入数据从800800的图像中随机裁剪为544544的图像块。batch=12,lr=2.5*10^{-4}, power=0.9,训练20个epochs之后,验证集上的mIOU=72.3%。
4.1.2 Dense Upsampling COnvolution(DUC)
作者在baseline上测试了DUC的效果。只改变了模型的最顶层的卷积层。举个例子,如果baseline的最顶层的feature map为68*68*19(19为类别个数),而采用DUC的话,顶层的feature map为68*68*r^2*19,r代表模型的下采样率。然后直接直接把feature map进行reshap,恢复到544*544*19。DUC会增加顶层的参数,对ResNet-DUC训练了20epochs,mIOU增加到74.3%。
Ablation Studies,作者对实验进行了中设置,分别是1)、下采样的比率,这个决定了顶层feature map的分辨率。2)、是否采用ASPP,以及ASPP的并行个数。3)、是否进行12倍的数据增强。4)、cell size,cell size决定预测一个像素时是否考虑其周边的像素(cell*cell)。逐像素的DUC应该设置cell=1,但是ground truth也不能达到逐像素的精度,所以作者尝试了cell=2的方式。可以看出减少下采样的比例会降低分割精度,而且会提高计算量,因为feature map的分辨率变大了。ASPP有助于提高精度,作者测试了提高ASPP的并行个数从4增加到6,精度提高了0.2%。数据增强使精度提高了1.5%。cell=2比cell=1精度稍微的提高了一点。而且cell=2降低了计算量,这个地方我不是很明白?
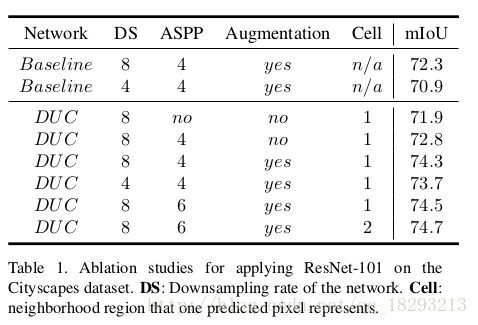
Bigger Patch Size 作者考虑到cell=2可以降低计算量,而且原始的图像大小是1024x2048,这个模型使用越大的图像效果越好,这样就可以包含更多的局部和全局上下文信息。因此作者把图像块变大为880x880,但是12倍数据增强得到的图像大小只有800x800所以作者重新进行了数据增强。进行了7倍数据增强,在原始数据中以x=512, y={256,512,768…1792}确定7个坐标,然后以这7个坐标为中心,画160x160的矩形,从这7个矩形中随机选取中心点,在原图上裁剪880x880的区域。这种数据增强方式使得精确度提高至75.7%。
Compared with Deconvolution 作者在实验中和Deconv进行了对比,1)直接从8倍下采样的feature map进行deconv恢复至原始分辨率。2)、先2倍deconv,再进行4倍上采样恢复至原始分辨率。这两种方式分别获得mIOU为75.1%和75.0%。比ResNet-DUC低(75.7%)。
CRF 在ResNet-DUC上采样CRF,mIOU=76.7%。
4.1.3. Hybrid Dilated Convolution(HDC)
作者使用101层的ResNet-DUC作为基本模型,来测试HDC以及HDC的各种变体。
不使用dilation
dilation-conv:两个block作为一个group,第一个block中rate=2,第二个block中rate=1
dilation-RF:对于res4b由23个block,作者把每3个block作为一组,设置rate分别为1,2,3。做后两个block设置rate=2。对于res5b包含3个block,设置rate分别为3,4,5。
dilation-bigger:对于res4b由23个block,作者把每4个block作为一 组,设置rate分别为1,2,5,9。最后三个block设置rate=1,2,5。对于res5b包含3个block,设置rate分别为5,9,17。
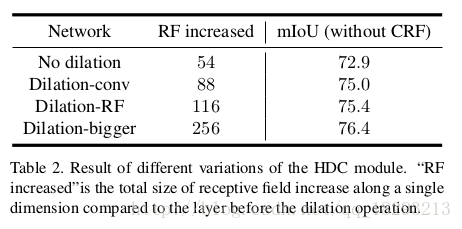
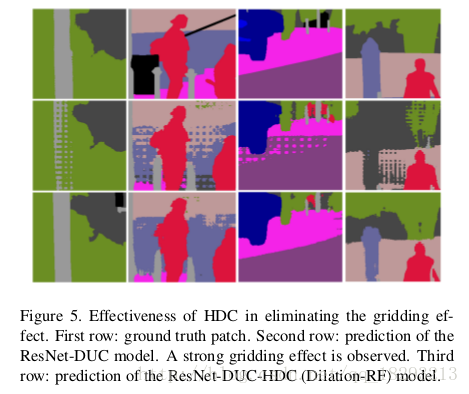
从结果中可以看出感受野的增大,可以提高分割的精度。
4.1.4 Test Set Results
作者训练模型时分别额采用了精细的label和粗糙与精细混合的label两种数据。在ResNet-DUC-HDC的模型上分别达到了77.6%,78.5%的精度。
受VGG模型的启发,在VGG模型中作者用两个3x3的卷积核代替一个5x5的卷积何来增强模型的表达能力。作者把ResNet中7x7的卷积核用3个3x3的卷积核替代。重新训练模型在测试集上mIOU达到80.1%,而且没有使用CRF后处理。比deeplab模型高9.7%。
5. Conclusion
作者提出了简单但是有效的卷积模型来提高语义分割的精度。DUC有助于像素级别的预测,HDC解决了带孔卷积中的gridding现象,并有效的增大了感受野。
这两大贡献都简单易懂,而且效果比较好。DUC是开创性的,以一种”自产自销”或者“自给自足”的思路来完成上采样,就是我不引入任何的额外信息,仅仅通过我产生的feature map就可以恢复到原始分辨率。HDC就是对ASPP的改进,去除了gridding现象。
这篇文章很好的提出了几个语义分割常见的问题:
1、反卷积或者双线性插值都是不可学习的,并且引入额外的信息,造成恢复的label没有那么精细。
2、图像中存在小物体时,经过多次下采样很难重建,特别是当小物体的大小比下采样的倍数还小的时候,基本是不能重建出来的。
3、DeepLab的遗留问题,就是dilate convolution造成gridding现象。
4、采用大的dilate convolution针对大的物体还是有效的,但是小物体可能就是灾难了。
所以针对以上问题,作者进行了改进,DUC解决了第一个问题,HDC解决了2、3、4问题,很完美。
文章理解的有不足之处,还请各位指出,谢谢。