现在来看看mask rcnn之前的一种实例分割的方法FCIS。FCIS是从作者之前的工作[1]衍生出来的,因此在这里一并介绍了,这样的话可以对来龙去脉比较清楚。
1InstanceFCN
传统的FCN很难做实例分割是因为物体的位置有可能重叠,如果是相同类别的物体,那么他们的mask也会连在了一块,因此无法区分出每一个个体的mask的位置。
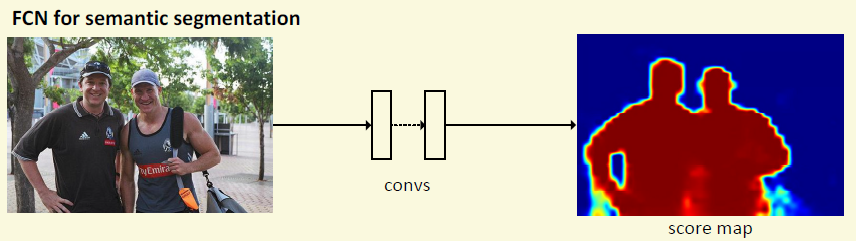
那作者想出了个什么方法呢?作者引入了位置敏感的激活图。类似于DPM,作者采用了多个激活图,每个激活图只负责物体某个位置的检测。以9个为例,那么第一个激活图就负责物体的左上角。如果某个点在某个物体的左上角,那么它在该激活图就有反应,另外就算该点属于这个物体的中部,那么理想情况下它在左上这个激活图应该不激活。虽然上图中两个人连在了一起,但是连在一起的部分相对于两个人的位置是不一样的,因此可以预见他们相对应的部分在同一个激活图中应该是不相连的,比如两个人的中上部也就是头不会连在一块,右手部分也不会连在一起等,如下图。

这个图第一次看的时候我觉得很晕,不过理解过后就很清楚了。比如右下角这个图激活比较大的点是两个人的右下部分。
那么怎么知道一个物体的完整的mask呢,只要拼接对应这个物体框的9幅小激活图即可。
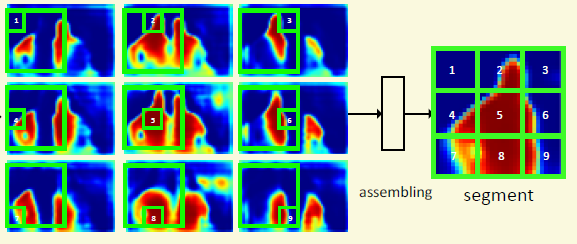
比如右图的左上角1好图就是从左图的左上图1号小图直接拷贝而来,其他类似。
不过一看这种固定框的就会存在scale的问题,因为物体有不一样的大小,不过现在先不考虑这个问题,还有两个大问题需要考虑,那就是
1怎么知道哪里有物体?
2怎么知道这个框对应什么物体?
第一个问题,作者加了一个head去预测objectness scores,不过这样子好像又看到了另外一个问题。分割是在缩小8倍的特征图上做的,虽然Mask RCNN类似,但是别人有RoiAlign,这里的低分辨率感觉是个问题,会影响最后的性能。

第二个问题,作者好像没有处理啊,难道实例分割不需要包含语义分割--!,应该还是需要再加个分类的head吧,不太确定。
之前scale的问题作者采用多scale的图像输入解决,
总体感觉这个方法有些丑陋。
2 FCIS
到了FCIS, Mask RCNN好像就跟它很像了,如下图
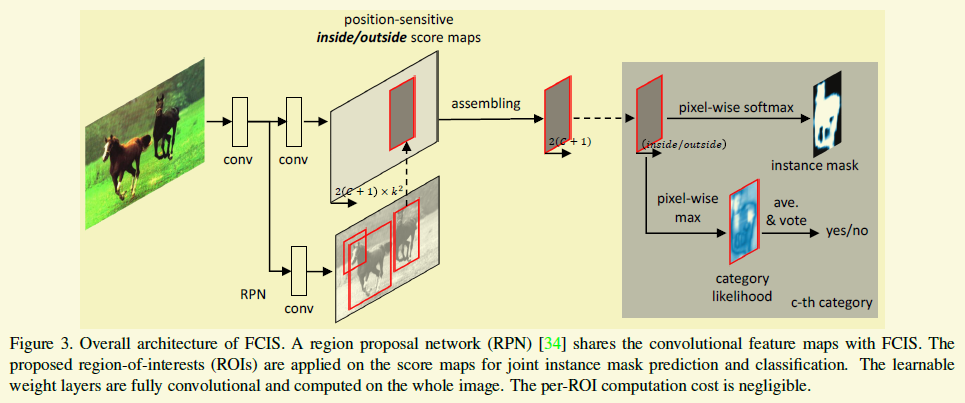
应该都是一个2-stage的架构。首先通过RPN定位物体,然后另外一路分支在这个ROI里做分割和分类。
不同的是,FCIS采用的类似上面多个不同的score map来处理,而mask rcnn是直接预测。这样可以发现mask rcnn的一个问题,如果像第一幅图中一样有两个人,而RPN框住了一个人,mask rcnn得非常依赖CNN来区别连在一块的部分。
另外FCIS的分割部分跟作者之前的InstanceFCN的区别是增加了outside score,也就是说有另外9个score maps预测不是物体像素的概率,有点互补的感觉,如果真的互补,有这个没这个其实都无所谓,有点奇怪,到现在还明白这部分的作用
[1]Instance sensitive fullyconvolutional networks