Appearance-and-Relation Networks for Video Classification
paper:https://arxiv.org/abs/1711.09125
code: https://github.com/wanglimin/ARTNet
1. 引言
在视频分类和理解中,有两类信息至关重要:单帧的静态表观信息,以及多帧之间的时序关系。针对这一点很多视频分类相关的文章都进行了研究,其中有3种比较成功的框架:
(1)two-stream CNN
(2)3D CNNs
(3)2D CNNs + 时序模型如LSTM,时域卷积,稀疏采样和聚合,attention等。
Two-stream CNNs通过两个分支来捕获appearance和motion的信息,这对于video classification是比较有效的。但是它要训练两个网络比较费时,且需要提前提取optical flow也很耗时。为了解决这一点,3D CNNs利用3D conv和3D pooling直接从RGB的堆叠序列中学习到时空域的特征。但是3D CNNs的效果还是比two-stream要稍差一些,这可能说明了:3D的结构可能并不能够有效地同时对表观信息和时序关系进行建模。
2D CNNs + 时序模型通常在提取粗糙的长时的时序结构上表现的比较好,对于提取短时的精细的时序关系表现得不太好。
基于以上问题,本文提出了SMART block,这个block的目标是同时对appearance和temporal relation进行建模,但是是通过RGB的输入以一个two branch unit的方式,而不是像two-stream一样有两种输入(RGB+flow),也不是像3D conv的方式直接从RGB一支到底地建模(因为根据刚才的分析3Dconv的结构可能不能够有效地同时对表观信息和时序关系进行建模)。
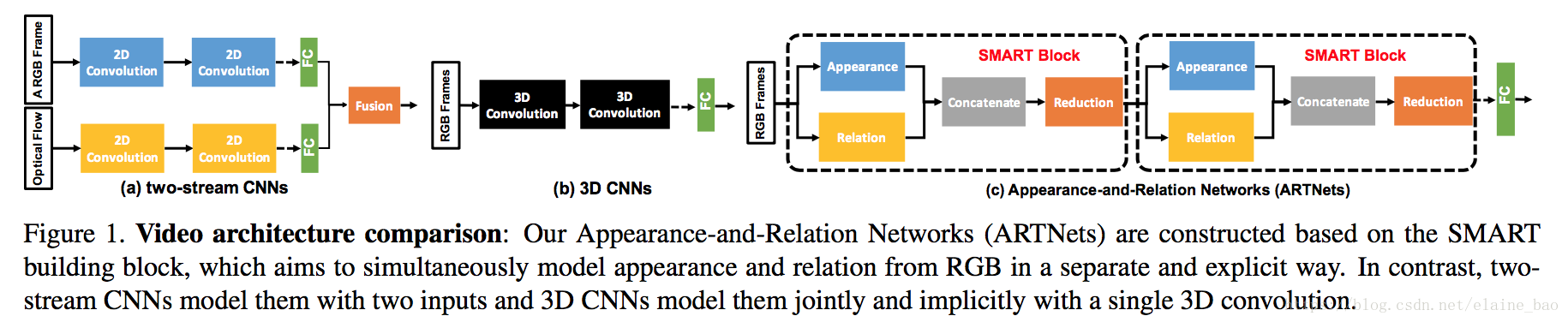
本文的主要贡献有3点:(1)SMART block能够同时对appearance和relation建模 (2)ARTNet是通过堆叠多个SMART blocks得到的,可以从不同尺度对appearance和relation进行建模 ,这也使得SMART block的参数优化可以end-to-end地进行。(3)ARTNet在Kinetics上实验的结果表明,仅通过RGB的输入,train from scratch, 能够达到state-of-the-art的性能。
2. 时空域的特征学习
2.1 Multiplicative interaction
假设在连续帧上有两个patches,x和y,我们的目标是学习它们之间的变换关系z。一个常见的解决方案是将两个patches concat起来然后进行特征学习,就像3D conv一样:
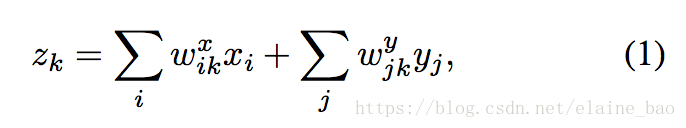
这里学到的
就是[x,y]和参数
之间的线性组合。然而,这种情况下z的取值是依赖于patches的appearance的而不仅仅是依赖于它们之间的relation。也就是说如果两个patches改变了它们的表观特征但是没有改变它们之间的时序关系,z的取值也是会发生变化的,因此这个解决方案将appearance和relation的信息结合起来了,这可能导致建模的困难并且增加过拟合的风险。
假设appearance和relation之间是相互独立的,则可以将两者分开建模。x和y的乘积就能很容易地实现 appearance-independent relation detector,此时
的形式如下:

是一个x和y和weight的二次方程, 也就是x和y的外积。这样
的每个元素都表示x和y之间的一种关系(感觉有点像non-local nwtwork里面的dot product),保证了
主要受两者relation之间的影响。
Factorization and energy models. (2)式实现起来的一个主要问题是它的参数量相当于像素个数的立方,将其因式分解成3个矩阵能够有效地减少参数量,即
。所以(2)式就可以写成:
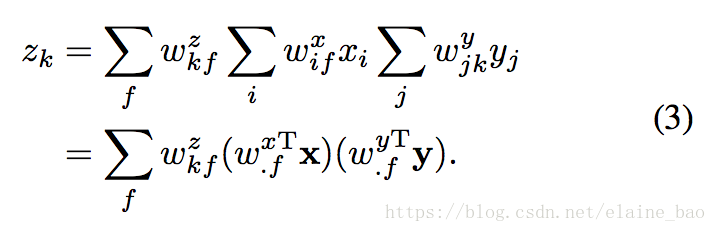
这个因式分解的公式和energy model很相关,并且可以被表示成energy model的形式。具体地,在energy model中的一个隐含单元
是通过以下公式计算的:
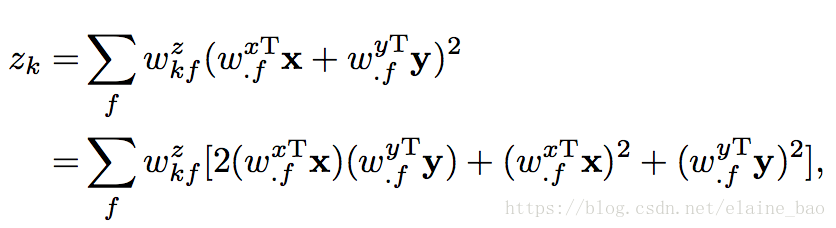
看出第一项和(3)式一样的,后面2项二次项不会有很大的影响。energy model可以通过3D CNNs实现,并且可以很容易地是一层一层地叠加。
2.2 SMART模块
SMART模块主要用于将appearance和relation分开建模。
Appearance branch. 这个分支作用于单帧的图像上,即对输入的视频帧使用2D conv来捕获每一帧的spatial信息。然后后面接BN和ReLU。
Relation branch. 这个分支作用在stacked连续帧上,用于捕获帧与帧之间的关系。根据之前对multiplication interactions的讨论,我们用3D Conv实现energy model。具体地,首先对输入V采用3D Conv,然后后面再通过一个平方函数(square function)得到隐含层unit
。然后再做cross-channel pooling来将U中不同unit聚合,得到
。这个cross-channeel是通过1*1*1 conv实现的。实际中在Z后面还会接BN和ReLU,和appearance branch保持一致。另外我们还在3D conv和square-pooling之间加了一个BN以提高它的鲁棒性。
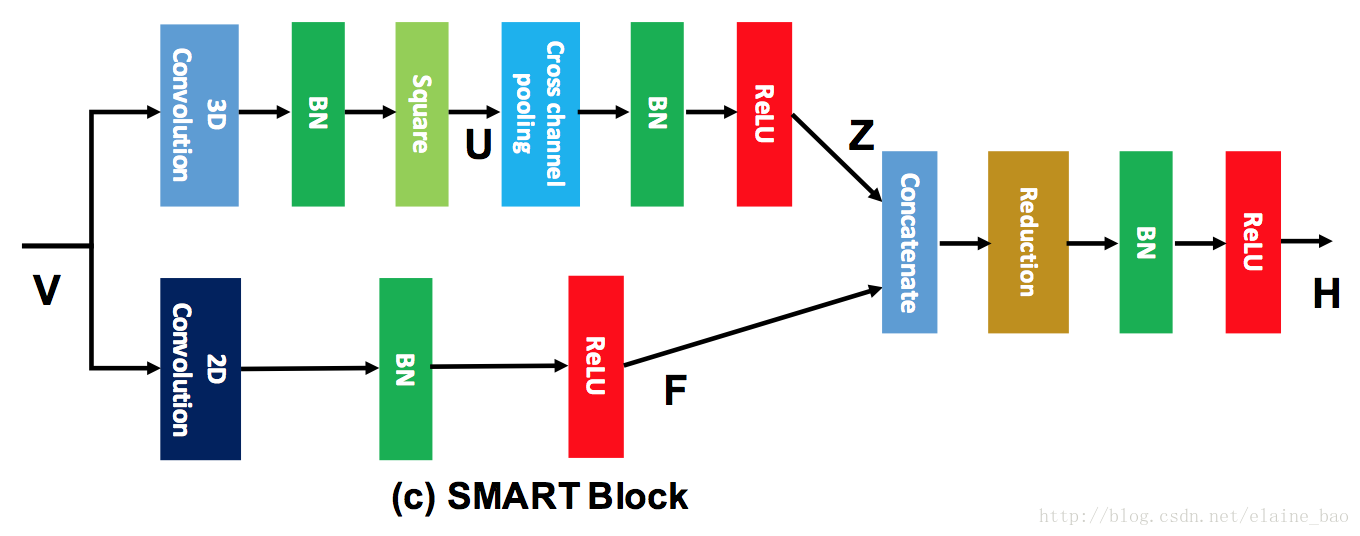
A SMART block. 将以上两个分支的输出做concat,然后经过1*1*1的卷积进行reduce之前concat的channel数。后再接BN和ReLU。
一个例子:ARTNet-ResNet18
SMART模块实现的功能和C3D类似,所以SMART模块可以代替3D conv来学习时间空间域的特征。
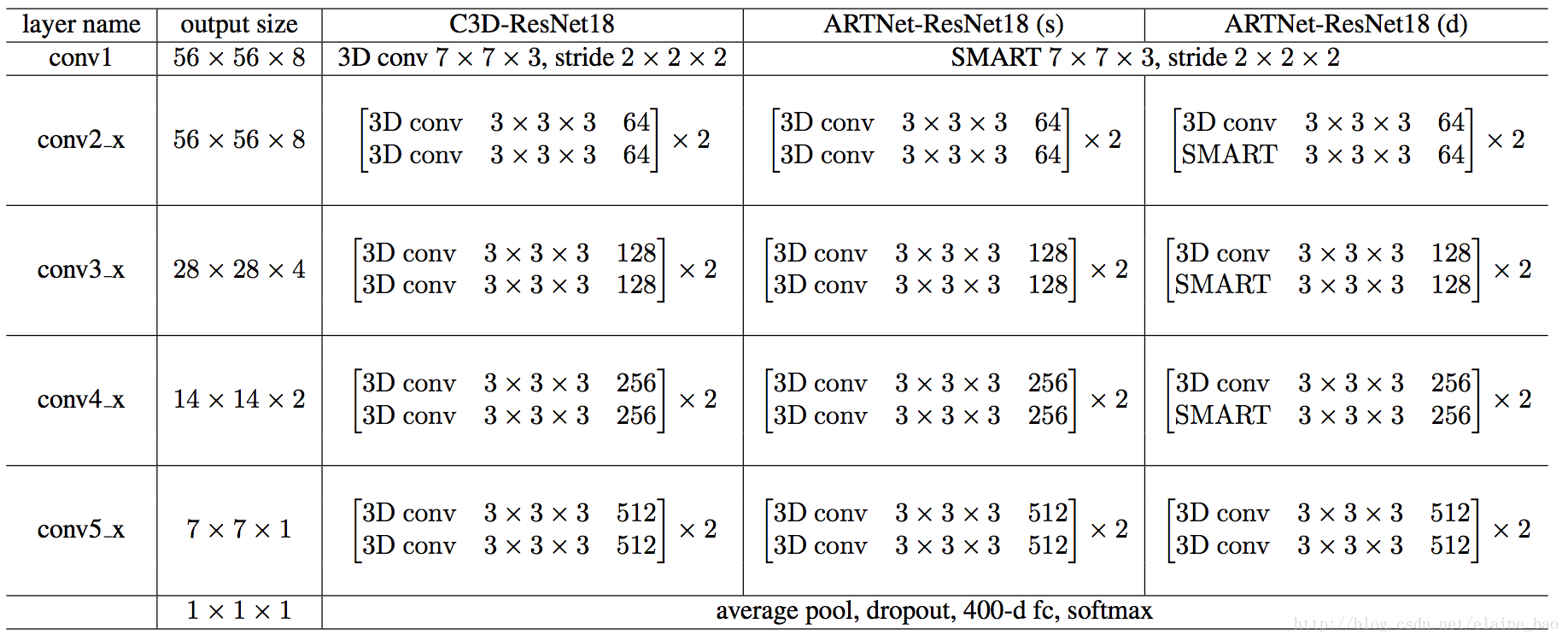
C3D-ResNet18的结构就是多个3D conv,ARTNet-ResNet18(s)是将C3D-ResNet18的第一个3D conv改成SMART的结构,ARTNet-ResNet18(d)则是改了7个SMART的结构。堆叠多个SMART blocks是为了在不同尺度上获取appearance和relation的信息,增强ARTNet-ResNet18(s)的建模能力。
这篇文章用的backbone都是ResNet18,原因貌似是ARTNet的参数比较多,难收敛。
实现细节。我们在Kinetics上测试了我们的模型。这些模型都是通过在Kinetics的训练集上train from scratch得到的。模型参数随机初始化,batchsize=256,moments=0.9, 帧的大小resize到128*170再随机取112*112*16帧,random horizontal flip。初始lr=0.1,每当val loss不下降了就降10倍。在Kinetics上的总iteration为250000。为防止过拟合,在fc层前加了dropout=0.2。
在test时,从整个视频中平均选取128*170*16个clips,然后做10crop得到112*112*16*250,最后的结果是这250帧的平均。
3. 实验
文章大部分实验都是在kinetics完成,模型都是从kinetics上train from scratch得到。
(1) 比较不同的building block和stacking的作用
下图给的都是error,即Top-1 error,Top-5 error,Avg error。
其中C2D-ResNet18就是将上述例子中C3D-ResNet18中的3D conv改成2D conv。Relation-ResNet18就是指只用Relation Branch。
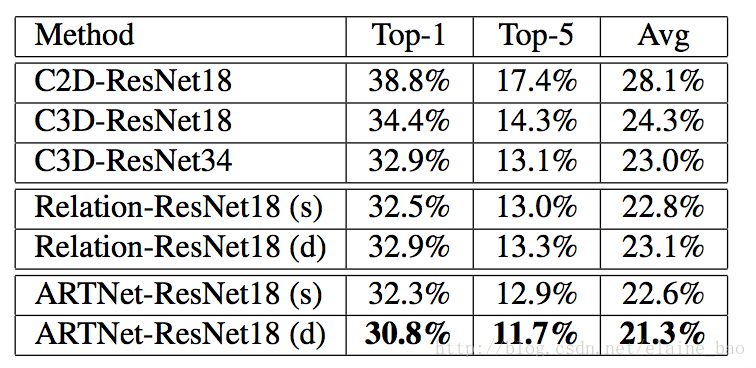
这里值得一提的是,增加SMART的block数目其实也是增加了网络的深度,那么到底是网络深度使得ARTNet-ResNet18(d)的结果好于ARTNet-ResNet18(s),还是SMART结构确实在起作用呢?看C3D-ResNet18和C3D-ResNet34的对比发现,深度深了效果反而降了,所以说是SMART结构在起作用。
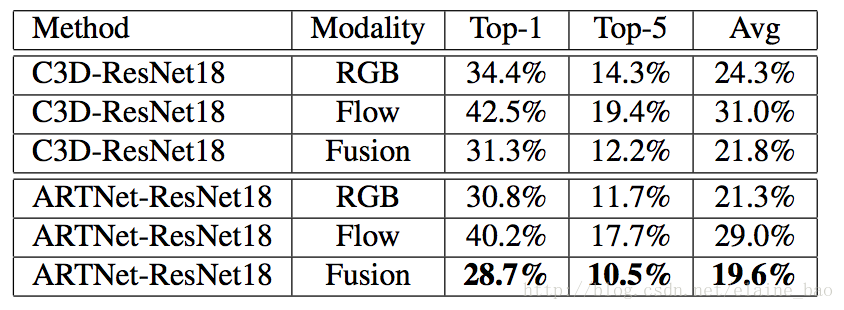
(2) two-stream的作用
two-stream还是明显有效果的,说明SMART结构提取到的时间空间域的信息和光流还是互补的。值得一提的是ARTNet-ResNet18基于RGB的结果比C3D-ResNet18基于Fusion的结构还要好一些。不过文章说ARTNet-ResNet18基于Flow的训练计算参数太多,比较难调,所以后文还是用的RGB的结果做的比较。这个说起来如果网络结构更大,就更难调了。。难怪作者用的backbone都是ResNet18。
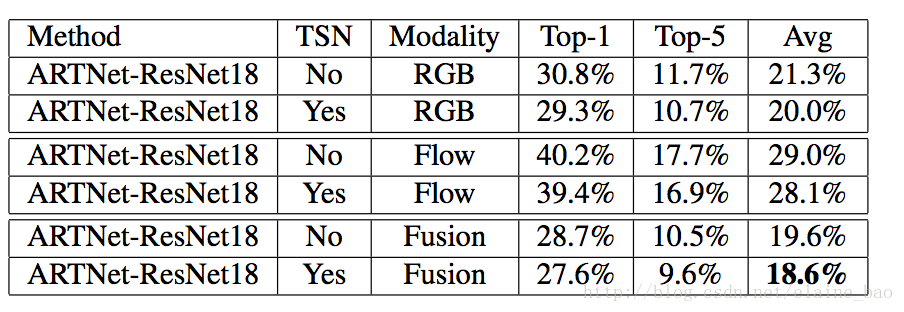
(3) long-term的建模
用TSN结合ARTNet实现的long-term。
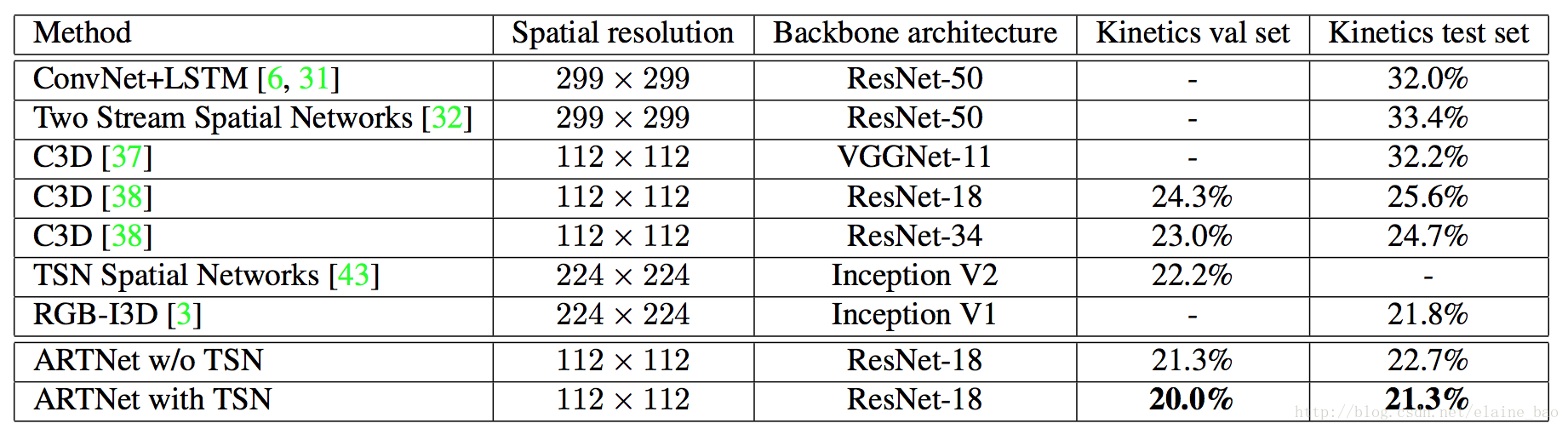
(4) 和其他state-of-the-art模型的对比
ARTNet用的112尺度的图+ResNet-18的结果要优于别的更大尺度的图+更大的模型的结果。