0 摘要
我们针对标准卷积神经网络提出了两种有效的近似网络:二元权重网络和XNOR网络。二元权重网络中,卷积核用两个值来近似表示,从而节省32倍的存储空间。在XNOR网络中,卷积核和卷积层输入都是用两个值(1和-1)表示的。 XNOR网络主要使用二元运算进行卷积运算。这使得卷积操作速度提高了58倍,节省了32倍的内存。 XNOR网络实现了在CPU(而不是GPU)上实时运行最先进网络的可能。我们的二元权值网络简单,准确,高效,并且能够处理具有挑战性的视觉任务。我们在ImageNet分类任务上评估我们的方法。 AlexNet二元权值版本的分类准确性与全精度AlexNet相同。我们将我们的方法与最近的网络二值化方法BinaryConnect和BinaryNets进行比较,并且在ImageNet上以大幅优势胜过这些方法,超过了top-1 16%的精度。
1 引言
深度神经网络在计算机视觉领域,语音识别领域都显示了很好的性能。在计算机视觉领域,最出名的是卷积神经网络。AlexNet,VGG,GoogLeNet,ResNet用于物体分类;RCNN,Fast RCNN,Faster RCNN用于物体检测。
卷积神经网络在物体识别和检测领域展现了其可靠的性能,已经被用于现实世界的应用中。同时,虚拟现实(VR),增强现实(AR )以及智能可穿戴设备等方面也正在发生有趣的进步。将这两件作品结合在一起,我们认为现在是在智能便携设备上安装最先进识别系统的最佳时机。 但是,基于CNN的识别系统需要大量的内存和计算资源。 虽然它们在基于GPU的机器上运行良好,但它们通常不适用于手机和嵌入式电子设备等较小的设备。
例如,AlexNet具有61M参数(249MB内存)并且需要执行1.5B高精度操作来分类一个图像。 对于更深的CNN,这些数字甚至更高,例如VGG(参见第4.1节)。 存储这些参数很快就会超过手机等小型设备的有限内存容量,电池电量和计算能力。
在本文中,我们介绍一种简单,高效,准确的网络来近似卷积神经网络。近似的方法是通过对卷积神经网络中的权值,甚至中间层的表达,进行二值化。 我们的二值化方法旨在使用二元运算找到卷积的最佳近似值。我们证明,我们对神经网络进行二值化的方式在ImageNet分类的准确度与标准全精度网络一致,但是需要的内存更少和浮点运算也更少。
我们研究两个近似网络:具有二元权重的网络和XNOR网络。 在二元权重网络中,所有权重值都用两个值近似。 与全精度权重的网络相比,二元权重网络更小(大约压缩了32倍)。另外,当权重值都用两个值近似时,卷积可以仅通过加法和减法来计算(无乘法),从而加快运算速度(大约提高2倍)。 将大型CNN进行二值化近似可以适用于小型便携式设备,同时保持相同的准确性(请参阅第4.1节和第4.2节)。
更进一步,我们提出了XNOR网络,其中卷积层、全连接层的权重以及网络的输入都进行二值化。 二值化的权重和二值化的输入可以有效地实现卷积运算。如果卷积运算的所有操作数都是二值(1和-1)的,那么可以通过XNOR(异或非门)和位计数操作来估计卷积。XNOR-Nets可以精确地近似CNN,同时在CPU中提高58倍计算速度。 这意味着,XNOR-Nets可以在内存小和无GPU的设备中实现实时前向计算(XNOR-Net中的前向计算可以在CPU上非常高效地完成)。
本文是第一次尝试在像ImageNet这样的大规模数据集上对二值神经网络进行评估。 我们的实验结果表明,我们提出的卷积神经网络二值化方法在ImageNet挑战ILSVRC2012中的top-1图像分类方面优于Binarynet方法,并且有大幅度的提高(16.3%)。 我们的贡献有两方面:
首先,我们介绍了卷积神经网络中权值二值化的方法,并展示了我们的解决方案与最先进的解决方案相比的优势。
其次,我们引入XNOR-Nets,一种具有二值权重和二值输入的深度神经网络模型,并且实验表明XNOR-Nets可以获得与全精度网络相似的分类准确性,但是更高效。
2 相关工作
深度神经网络往往参数过多,会造成参数冗余。这会导致内存和计算资源的浪费。已有一些方法来解决这个问题,使得训练和前向计算更有效。
Shallow Networks浅层网络: 用更浅的网络来表示训练好的网络。很多时候,神经网络会存在冗余的参数和层数,这个方法通过使用更浅的网络,达到相同的效果,减少参数加快计算。
Compressing pre-trained networks压缩训练好的模型: Deep Compression就是这样的方法。通过对模型参数进行剪枝,量化,哈夫曼编码等技巧,能够压缩模型。
Designing compact layers设计更简洁层: Residual layers就是一种压缩的手段。
Quantizing parameters量化参数: 目前浮点数通常使用32bit表示,量化可以用更少的位数来表示参数,但是会损失一定精度。
Network binarization网络二值化: 二值化是将网络完全使用+1, -1来表示,这样就可以用1bit来表示网络。Binary Weight Network 和XNOR-Net都是二值化的网络。网络二值化后,卷积可以表示为简单的加法减法,且可以大大减小计算时间。
3 二值化卷积网络
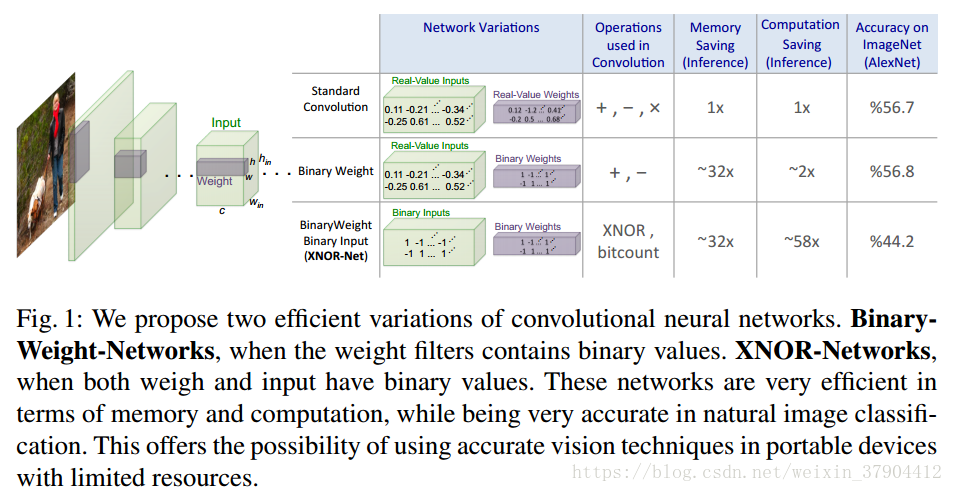
图1简单列出了二值化的两种网络和标准的卷积网络的差别。
3.1 Binary-Weight-Networks
Binary-weights的目的是将权重W的值都用二值表示,也就是W的值要么是-1,要么是1。这个替代过程贯穿整个forward和backward过程,但是在更新参数时候还是采用原来的权重W,主要是因为梯度的量级通常很小,直接对B进行更新时,求导后值为0,造成梯度消失;而且更新参数需要的精度比较高。
一个卷积层的操作可以用 表示, 表示输入,维度是 , 表示卷积核(或者叫权重),维度是 。那么当我用二值卷积核 以及一个尺度参数 代替原来的卷积核 (即, ),那么就可以得到下面这个式子:
其中, 表示没有乘法的卷积计算; 默认是个正数, 和 是相对的,因为如果 和 都取相反数的话,二者相乘的结果不变。前面的 和 表示某一层的卷积操作的写法,因为每一层卷积都包含多个卷积核,因此如果具体到某一层的某个卷积操作,则可以用下面这个式子表示: 。其中, ;下标 表示第 层的第 个卷积核。
既然我们希望用一个尺度参数
和二值矩阵
来代替原来的权重
,那么肯定希望前者能尽可能等于后者,于是就有了下面的优化目标函数,也就是希望下面这个式子中的
越小越好,这种情况下的
和
就是我们需要的。另外这里将矩阵
和
变换成向量,也就是
和
的维度是
,这里
,这主要是为了后面推导的方便。
因此接下来就是要求
和
的最优值,使得满足上面那个优化目标。那么这个优化具体要怎么实现呢?来看推导。上面那个优化函数展开后可以写成下面这个形式。应该比较容易理解。
因为
是一个
的向量,里面的值要么是-1,要么是1,所以:
,也就是一个常量。同时因为W是已知的,所以:
,也是一个常量。另外
是个正数。这些常量在优化函数中都可以去掉,不影响优化结果。就可以得到
的最优值的计算公式(可以结合前面第一个和第二个优化函数看):
显然,根据这个式子, 的最优值就是 的值的符号。也就是(这个式子是求 最优值的最终式子):
举个例子,当 中某个位置的值是正数时, 中对应位置的值就是+1,反之为-1。知道了 的最优值,接下来就是求 的最优值。这里采用上面第2个 函数表达式对 求导,并让求导结果等于0,从而得到最优值。式子如下 。
通过简单换算并利用前面计算得到的 的最优值就可以得到下面这个求 最优值的最终的式子: 。也就是说 的最优值是 的每个元素的绝对值之和的均值。 表示L1范数。
因此Binary-Weight-Networks的算法总结可以看下面这个介绍:第一个for循环是遍历所有层,第二个for循环是遍历某一层的所有卷积核。通过得到
和
就可以近似约等于原来的权重
了,另外在backward过程中的梯度计算也是基于二值权重。

3.2 XNOR-Networks
前面介绍的Binary-weights是将权重 的值都用二值表示,而接下来要介绍的XNOR-Networks不仅将权重 用二值表示,而且也将输入用二值表示。XNOR又叫同或门,假设输入是0或1,那么当两个输入相同时输出为1,当两个输入不同时输出为0。我们知道卷积操作就是用卷积核去点乘(element-wise product)输入的某个区域然后得到最后的值,因此假设你的输入是 ,卷积核是 ,那么我们就希望得到 使得: 。这里是用 近似表示输入 。另外: 。
因此就有了下面这个优化式子:
其中,
表示的是element-wise product,也就是点乘(dot product)。如果用
代替
,
代替
,
,那么优化式子就变成下面这样:
这个式子就和Binary-Weight-Networks部分介绍的优化式子类似。因此可以利用Binary-Weight-Networks的推导结果来解这个优化式子。根据前面
和
的计算公式,相应可以得到这里
和
的计算公式(就是下面两个式子的第一个等号):
其中,
式子的第二个等号是因为
和
是相互独立的,所以可以直接拆开。
两个等式的最右端就是4个参数的最优解。以上就是关于输入和权值都二值化的最优值的解。
接下来的图2是具体的二值操作。第一行就是前面介绍的Binary-Weight-Networks的最优值的求解。第二行是XNOR-Networks的最优值的求解,将输入进行二值化时,由于计算L1正则化时存在很多冗余的计算,所以采用第三行的方式:将输入在channel维度(
表示通道数)计算均值得到
,用
(
为
大小的卷积核,其值为
)对
进行卷积得到
。第四行其实和第三行含义是一样的,更加完整地表达了XNOR的计算过程,这里的
就是第三行计算得到的
,中括号里面的式子就是刚刚计算得到的最优的
。
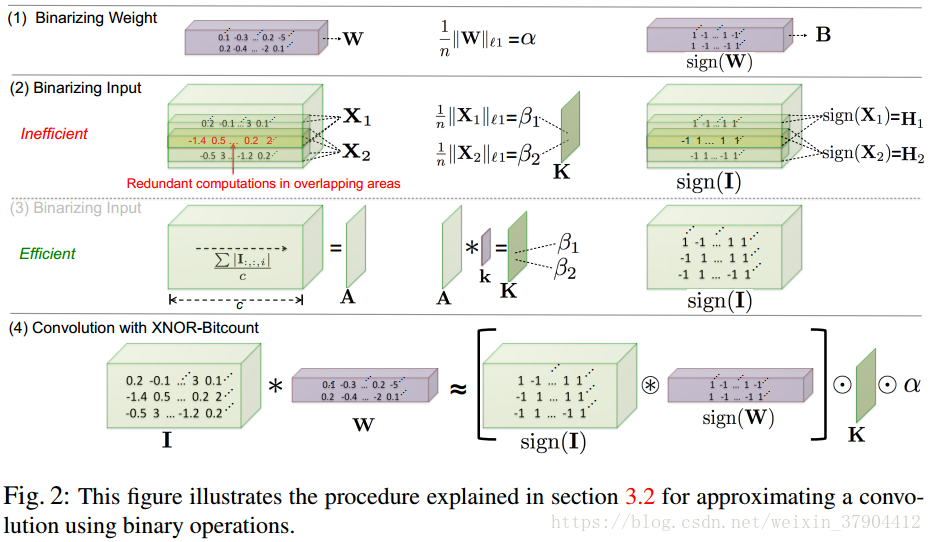
这里第四行有个符号是圆圈里面有个*,表示的是convolutional opration using XNOR and bitcount operation。也就是说正常两个矩阵之间的点乘如果用在两个二值矩阵之间,那么就可以将点乘换成XNOR-Bitcounting operation,从32位浮点数之间的操作直接变成1位的XNOR门操作,这就是加速的核心。
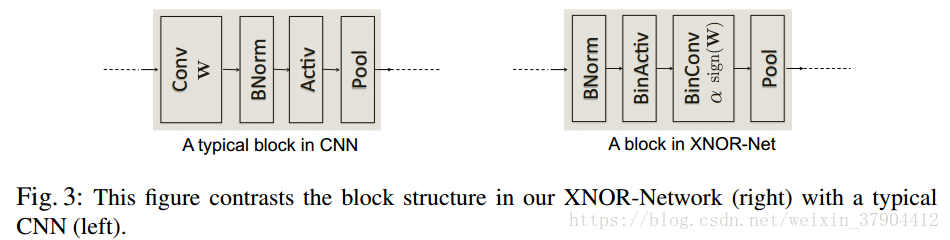
一个典型的 CNN 具有卷积、批规范化、激活、池化这样的四层结构,其中,池化层可以对输入运用任何种类的池化方式。但在二值化的输入(-1,1)进入到池化过程时,会产生大量的信息丢失。例如,对二值化输入进行 max-pooling 时,会导致大部分输入只剩+1,使得消息消减,精度降低。为了解决这个问题,改善了网络结构,改变这几层的顺序,首先实行批规范化,保证 0 均值,然后进行二值化激活,使数据都是+1 和-1,再做二值化卷积,此时由于比例因子的作用输出的不再是-1 和+1,这会相对减少信息丢失。在这里,建议在二值化卷积后加一个非二值化激活步骤(如 ReLU),这可以帮助训练比较复杂的网络。
4 实验
4.1 有效性分析
在标准卷积中,运算的总数是
,其中
是通道数,
,
。注意到,现在的CPU可以将乘法和加法融合为一个单周期操作。 XORNet具有
个二元运算和
个非二元运算,在64位的CPU上的加速比率
.
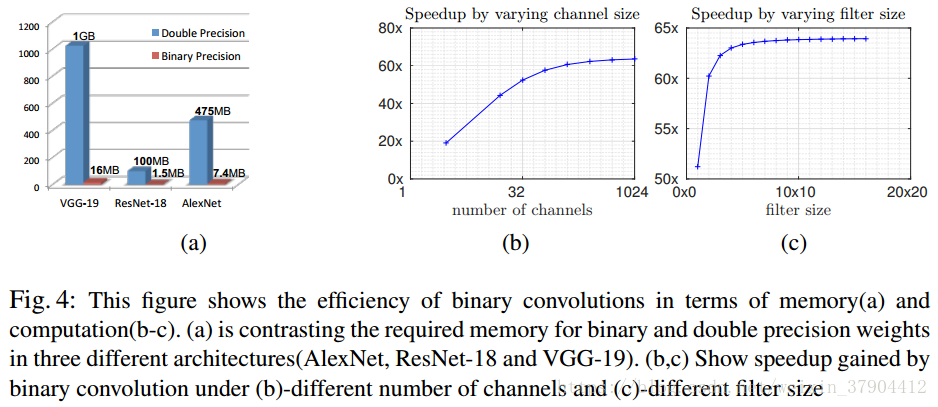
可以看到速度取决于输入通道数,卷积核尺寸,而不依赖于输入尺寸。图4(b-c)解释了速度随着输入通道数和卷积核尺寸的变化图。当改变一个参数的时候,固定其他参数,结果如下:
,
,
,这组参数达到了62.27倍的理论加速率,但是由于CPU的内存分配和处理程序,实际中只实现了58倍的加速率。当
,
时,加速效果不是很高,这说明在卷积网络的初始阶段,或者最后一层中避免使用二值化。因为第一层通道数是3,最后一层卷积核的尺寸是
。
4.2 图像分类实验结果
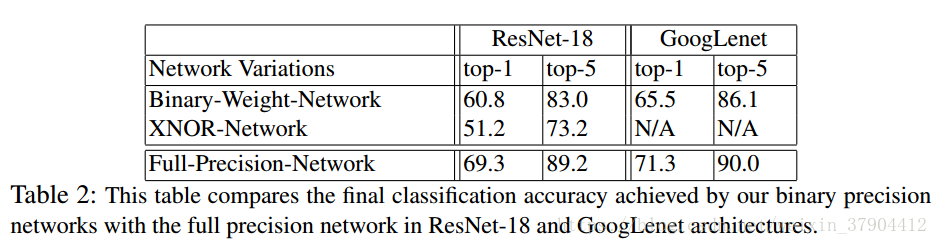
表1是两种二值化方式和其他二值化方式的对比。最后的Full-Precision是不经过二值化的模型准确率。
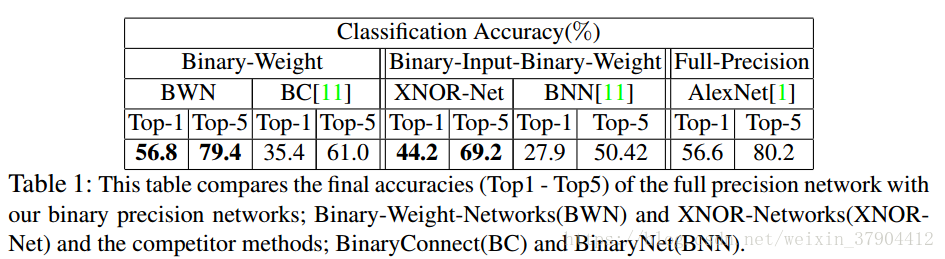
表2是两种二值化方式和正常的ResNet18的准确率对比,可以看出在ResNet18上Binary-Weight-Networks对准确率的影响也比较大。