acl论文阅读(Attention-Based Bidirectional Long Short-Term Memory Networks for
Relation Classification,中科大自动化所 Zhou ACL 2016)
数据集详情
SemEval-2010 Task 8 dataset
- training
8,000 sentences - testing
2,717 sentences - validation
randomly select 800 sentence
算法
blstm+attention机制,使用BLSTM对句子建模,并使用word级别的attention机制。
参数
- rate
1.0 - minibatch size
10 - L2 regularization strength
10−5 - the dropout rate
embedding layer:0.3
LSTM layer: 0.3
the penultimate layer:0.5 - Other parameters in our model are initialized randomly
效果
此论文所使用的方法F1值可以达到84.0,目前所有方法中最高的F1值为84.3(BLSTM (Zhang et al., 2015)),但此方法的缺陷是需要手动构造特征,而此论文是把数据灌入模型,不需要手动提特征。
算法详情
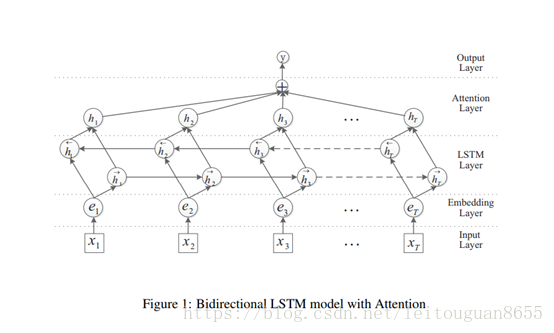
- Input Layer:将原始句子输入该层,x_i:句子中的每个单词,T:句子中单词个数
- embedding层:将每一个单词映射到一个低维向量,e_i:每个词的向量,可以是word2vec的结果;
- LSTM层:利用BLSTM模型从step(2)中得到高级特征;
- attention层:产生一个权重向量,并与LSTM的每一个时间点上word-level特征相乘得到sentence-level特征向量;
- output层:将得到的senten-level特征向量用于关系分类。
疑惑
- 论文对lstm正反向结果的处理(即上文中的第三步)
和之前直接把lstm的最终正反向输出直接拼接相比,作者这里是把每一个单词的前馈输出与反馈输出逐个元素求和得到的向量作为最后的 输出,关于这一块文中并没有给出具体解释。 - Attention机制中权重的处理
和随机初始化不同的是,本论文中的权重和lstm层的输出有关,文中没有具体解释这样做的原因。
代码
没有找到论文的源码,从github找到一份类似思想的脚本进行调试,脚本调试过程。
其他
论文理解的不透,代码也处于很弱的阶段,且行且珍惜,祝自己保持初心!