论文:https://arxiv.org/abs/1608.00859
代码:https://github.com/yjxiong/temporal-segment-networks
1. 引言
在视频分类中,对长时间域的建模有利于掌握整个视频的类别。而ConvNets擅长的是对appearance的建模和短时的motion。因此对于长时域结构的建模,CUHK提出了TSN。
视频里面的连续帧是存在很多冗余信息的,所以dense temporal sampling是不必要的,sparse temporal sampling比较合适。所以TSN的思想之一就是从长的视频中稀疏采样一些帧,然后再聚合起来,这样就能建模长时间域了。另外一个思想,TSN借鉴于two-stream的结构来同时建模appearance和dynamic。
2. TSN
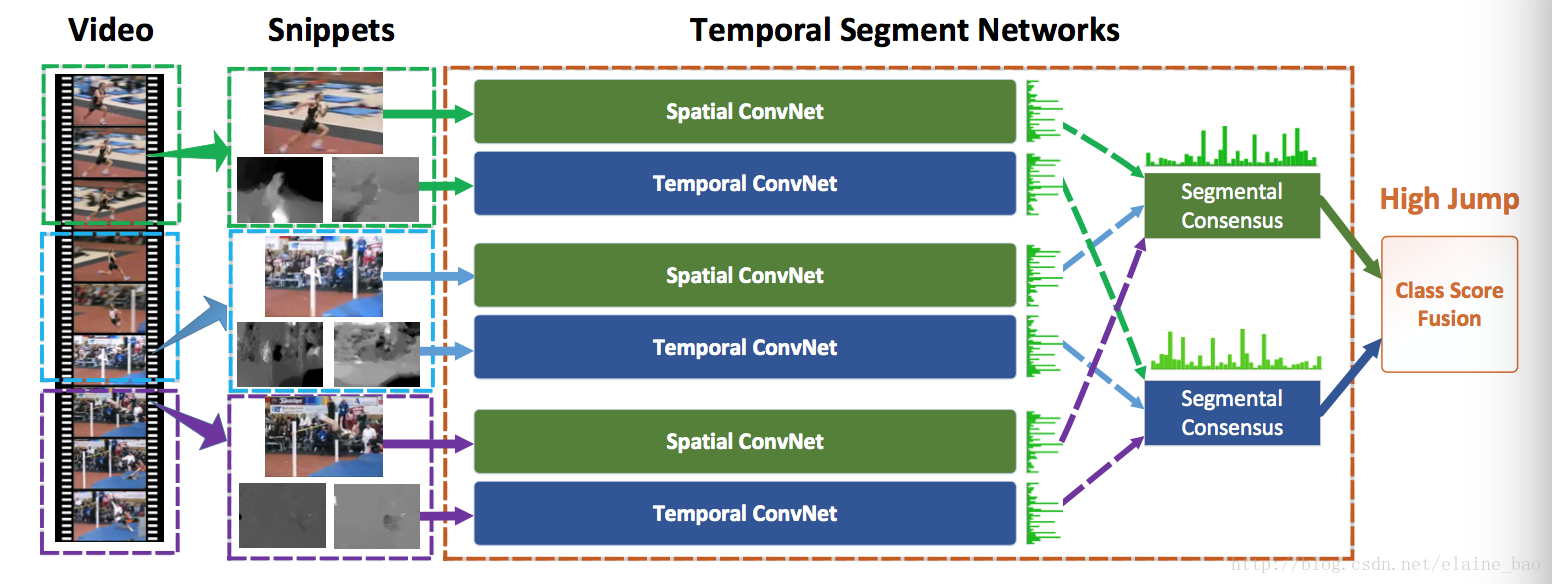
2.1 网络结构
TSN的结构是two-stream,其中spatial的输入是视频中稀疏采样得到的帧序列。为了保证视频中各个位置都能采样到,TSN引入了segment的概念,即把整个视频分成segment份,然后在每一份中分别采样帧。这种做法是它long-range temporal structure的具体体现。
temporal的分支也是分segment的,不过它在每一份中会抽取多帧flow stack到一起作为输入。
2.2 训练相关
Cross Modality Pre-training. 用Spatial的模型来初始化Temporal的部分。首先将光流值scale到0~255,然后将Spatial模型的第一层conv层的weights作改变,即将3个channel的weights平均得到avg weights,然后将这个weights重复n次,n=temporal网络的channel数目。
Regularization Techniques. 提出了Partial-BN,即只对第一个BN层进行参数优化,其他BN层的参数都固定。同时在global pooling层后面增加一个额外的dropout层来减少过拟合的可能。dropout ratio在spatial net里等于0.8,在temporal net里等于0.7。
Data Augmentation. random cropping,horizontal flipping,corner cropping,scale jittering。其他都根据字面意思可以理解,那scale jittering的做法是指,帧/光流图输入大小都是256*340,然后将宽和高分别random crop/corner crop成{256,224,192,168},再resize到224*224进行训练。