论文地址:https://arxiv.org/pdf/1812.03982v1.pdf
1.Abstract
作者提出了用于视频识别的快速网络。模型包括(i)一个缓慢的路径,在低帧率下运行,以捕获空间语义,以及(ii)一个快速的路径,在高帧率下运行,以捕获精细时间分辨率的运动。快速路径可以通过减少其通道容量而变得非常轻,但也可以学习有用的时间信息用于视频识别。
2.Introduction
在识别图像I(x,y)时,通常会对称地处理两个空间维x和y。以近似图像的各向同性——所有的方向都是等可能的——和移位-不变的[38,23]。但是,对于视频信号I (x、y、t),运动是方向[1]的时空对等物,但所有的时空方向的可能性并不相等。慢动作比快动作更有可能(事实上,我们看到的世界上大部分都在给定的时刻处于静止状态),这在人类如何感知运动刺激[51]的贝叶斯描述中得到了利用。例如,如果我们看到一个孤立的运动边缘,我们就认为它是垂直于自身移动的,即使原则上它也可能有一个与自身相切的任意运动分量(光流中的孔径问题)。如果先前有利于缓慢的动作,这种感知是合理的。
如果所有的时空方向都不相等,那么就没有理由对称地处理空间和时间,就像基于时空卷积[44,3]的视频识别方法中所隐含的那样。更可能会“考虑”架构来分别处理空间结构和时间事件。为了具体性,让我们在认可的背景下研究一下。视觉内容的分类空间语义往往发展缓慢。例如,在挥手动作中,挥手不会改变他们作为“手”的身份,一个人总是属于“人”类别,即使他/她可以从步行到跑步。所以对分类语义的识别(以及它们的颜色、纹理、灯光等)。可以刷新得相对较慢。另一方面,正在执行的动作可以比他们的主题身份进化得快得多,比如鼓掌、挥手、摇晃、行走或跳跃。它可以期望使用快速刷新帧(高时间分辨率)来有效地建模潜在的快速变化的运动。
基于这种直觉,作者提出了一个视频识别的双路径快速模型(图1)。一种路径被设计用来捕获图像或一些稀疏帧可以给出的语义信息,它在低帧率和慢刷新速度下运行。相比之下,另一种途径负责通过以快速刷新速度和高时间分辨率来捕捉快速变化的运动。尽管它的时间率很高,但这个路径是非常轻的,例如,∼占总计算量的20%。这是因为该路径被设计为具有更少的通道和更弱的处理空间信息的能力,而这些信息可以由第一个路径以更少的冗余的方式提供。作者称第一个为慢路径,第二个为快速路径,由它们不同的时间速度驱动。这两条路径通过横向连接而融合。
作者的概念性的想法导致了灵活和有效的设计的视频模型。快速路径,由于其轻量级的特性,不需要执行任何时间池化——它可以在所有中间层的高帧率上操作,并保持时间保真度。同时,由于较低的时间速率,慢路径可以更关注空间域和语义。通过以不同的时间速率处理原始视频,这种方法允许这两种途径在视频建模方面有自己的专业知识。
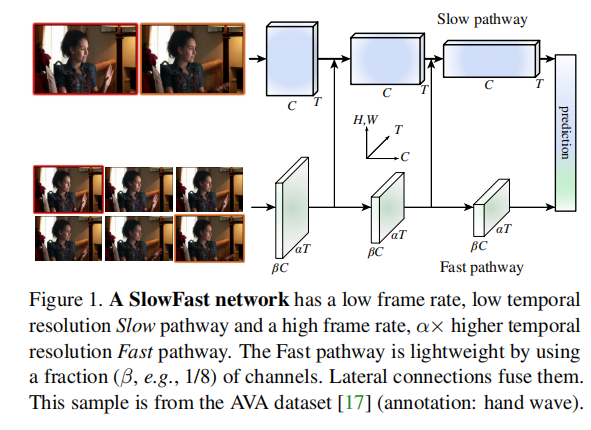
作者的方法部分受到了对灵长类动物视觉系统[24,34,6,11,46]中视网膜神经节细胞的生物学研究的启发,尽管不可否认,这个类比是粗糙和不成熟的。这些研究发现,在这些细胞中,∼80%是微细胞(p细胞),∼15-20%是巨细胞(m细胞)。m细胞在高时间频率下工作,对时间变化更敏感,但对空间细节或颜色不敏感。p细胞提供了精细的空间细节和颜色,但具有较低的时间分辨率。作者的框架类似于: (i)模型有两条路径分别在低时间分辨率下工作;(ii)快速路径旨在捕捉快速变化的运动,但更少的空间细节,类似于Mcells;(iii)快速路径是轻量级的,类似于m细胞的小比例。
3. SlowFast Networks
3.1. Slow pathway
慢路径可以是任何卷积模型(例如,[9,44,3,50]),它作为一个时空体积在视频剪辑上工作。我们的慢路径的关键概念是在输入帧上的一个大的时间步幅,也就是说,它只处理
帧中的一个。模型的
的一个典型值是16——这个刷新速度大约是每秒2帧每秒的视频采样。将慢路径采样的帧数表示为T,原始剪辑长度为T×
帧。
3.2. Fast pathway
与慢路径平行,快速路径是另一个具有以下特性的卷积模型。
高帧率。目标是沿着时间维度有一个很好的表示。快速路径使用/α的小时间步幅,其中α > 1是快速和慢路径之间的帧率比率。两条路径在同一个原始剪辑上运行,所以快速路径采样αT帧,比慢路径密集α倍。实验中的一个典型值是α = 8。
高时间分辨率的特征。快速路径不仅具有较高的输入分辨率,而且在整个网络层次结构中都追求高分辨率的特性。在实例化中,在整个快速路径中不使用时间降采样层(既没有时间池化,也没有时间链卷积),直到分类之前的全局池化层。因此,特征张量总是在时间维度上有αT帧,尽可能地保持时间保真度。
通道容量低。快速路径还与现有模型的区别在于,它可以使用显著较低的通道容量,以实现快速模型的良好精度。这使得它很轻。
简而言之,快速路径是一个类似于慢路径的卷积网络,但具有慢路径的β(β < 1)通道的比例。实验中的典型值为β = 1/8。请注意,公共层的计算(浮动数运算或浮动)的信道缩放比通常是二次的。这就是为什么快速路径比慢路径更有效地计算。实例中,快速路径通常需要∼占总计算的20%。有趣的是,正如在第二节中提到的。1,有证据表明,灵长类动物视觉系统中∼15-20%的视网膜细胞是m细胞(对快速运动敏感,但对颜色或空间细节不敏感)。
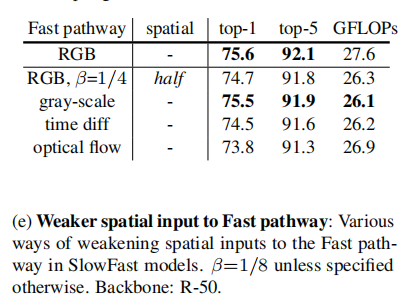
低信道容量也可以解释为一种较弱的空间语义表示能力。从技术上讲,快速路径在空间维度上没有特殊处理,因此由于空间建模能力较少,其空间建模能力应该比慢路径少,模型的实验良好结果表明,快速路径在增强其时间建模能力的同时削弱其空间建模能力是一个理想的权衡。
基于这种解释,作者还探索了在快速路径中削弱空间容量的不同方式,包括降低输入的空间分辨率和去除颜色信息。正如通过实验所展示的,这些版本都可以提供良好的准确性,这表明一个空间容量较小的轻量级快速路径可以来说是有益的。
3.3. Lateral connections
在每个“阶段”中,在两条路径之间连接一个横向连接(图1)。特别是对于ResNets [21],这些连接就在池1、res2、res3和res4之后。这两条路径有不同的时间维度,所以横向连接执行一个转换来匹配它们(详见Sec。3.4).同时使用单向连接,将快速路径的特征融合到慢路径的连接中(图1)。作者也进行了双向融合的实验,也发现了类似的结果。
最后,对每个路径的输出执行一个全局平均池化。然后将两个合并的特征向量连接为全连接的分类器层的输入。
3.4. Instantiations
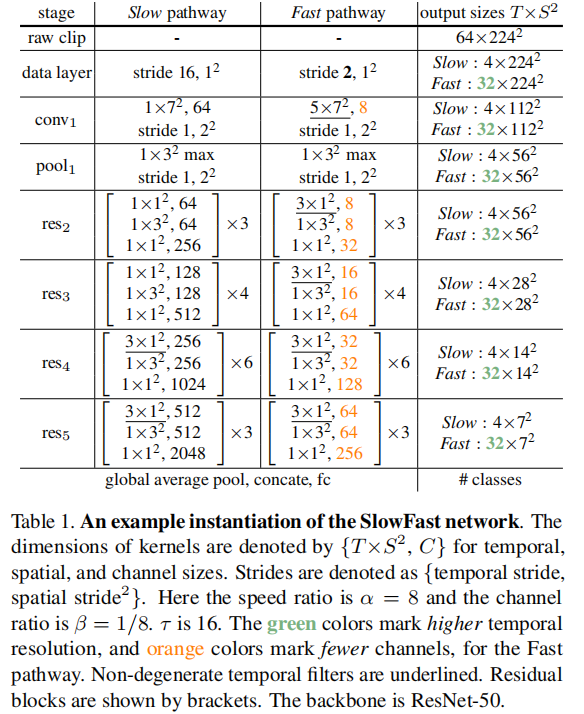
在表1中指定了一个SlowFast 模型的示例。我们用T×S^2来表示时空大小,其中T是时间长度,S是一个经过正方形空间裁剪后的高度和宽度。下面将描述这些细节。
Slow pathway. 表1中的慢路径是一个由[9]修改而来的3D ResNet,经过临时分支。它有T = 4帧作为网络输入,从一个64帧的原始剪辑中稀疏采样,时间步幅为= 16。在这个实例化中不执行时间降采样,因为当输入步幅很大时,这样做将是有害的。
与典型的C3D / I3D模型不同,只在res4和res5中使用非退化的时间卷积(时间核大小>1,在表1中下划线);从conv1到res3的所有滤波器本质上都是该路径上的二维卷积核。这是由于实验观察,即在早期的层中使用时间卷积会降低准确性。作者认为,这是因为当物体移动快速且时间步幅较大时,除非空间感受域足够大(即在后面的一层),否则在时间感受域内几乎没有相关性。
Fast pathway. 表1显示了α = 8和β = 1/8的Fast通路示例。它具有更高的时间分辨率(绿色)和较低的信道容量(橙色)。
快速路径在每个块中都具有非退化的时间卷积。这是由于观察到该路径具有良好的时间分辨率的时间卷积捕捉详细的运动。此外,快速路径在设计上没有时间降采样层。
(i) Time-to-channel: 将{αT,S^2,βC}重塑并转置为{T,S^2,αβC},这意味着将所有的α帧打包到一个帧的通道中。
(ii) Time-strided sampling: 简单地从每个α帧中取样一个,所以{αT,S^2,βC}就变成了{T,S^2,βC}
(iii) Time-strided convolution: 我们使用2βC输出通道和步幅=α对5×12内核进行三维卷积。
横向连接的输出通过累加或连接融合到慢路径中。
4. Experiments: Kinetics Action Classifification
Datasets. Kinetics-400
Inference. 按照通常的做法,从一个视频的时间轴上均匀地抽取10个片段。对于每个剪辑,将较短的空间侧缩放到256像素,并取3个256×256的crops来覆盖空间维度,作为全卷积测试的近似值,遵循[50]的代码。取预测的softmax的平均值。
4.1. Results and Analysis
使用预训练:

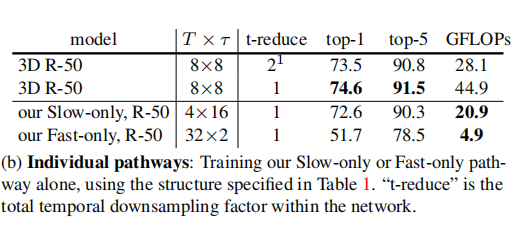
只使用单个路径:
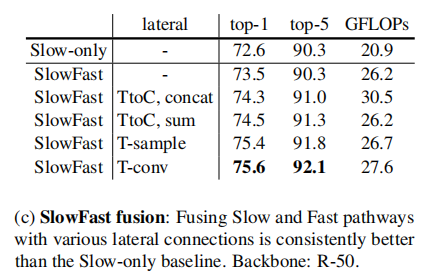
融合模块:
Channel capacity of Fast pathway.

Weaker spatial inputs to Fast pathway.
vs. Slow+Slow

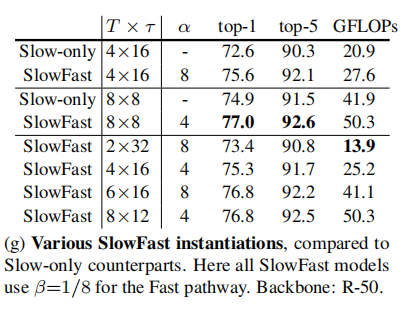
Various SlowFast instantiations.
Advanced backbones.

Comparison with state-of-the-art results.

Kinetics-600.

5. Experiments: AVA Action Detection
Dataset. AVA dataset
我们的探测器类似于Faster R-CNN [37],最小的修改适用于视频。我们使用快速网络或其变体作为主干。我们将空间步幅设置为res5到1(而不是2),并将其滤波器放大为2。这使res5的空间分辨率提高了2×。我们在res5的最后一个特征图上提取感兴趣区域(RoI)特征[14]。我们通过沿着时间轴复制每个2D RoI,将每一帧上的每个2D RoI扩展为一个3D RoI。我们通过RoIAlign [19]计算RoI特征,以及全局平均池。然后,RoI特征被最大限度地合并,并输入到每个类,基于sigmoid分类器进行多标签预测。
5.1. Results and Analysis
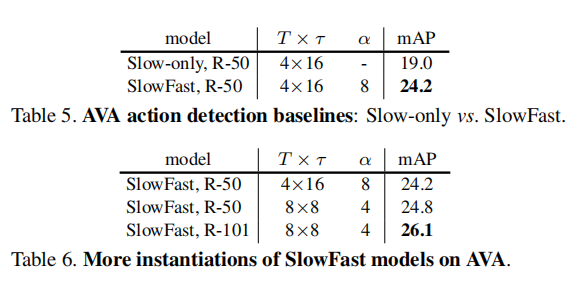
Comparison with state-of-the-art results.


